

In Part 2, we talked about creating a web scraper with Playwright to extract data from the Nike website, which has dynamically loaded content.
In Part 3, we will focus on carefully analyzing the extracted data and ensuring it's properly cleaned to deal with potential issues like missing values, inconsistencies, and outliers. The cleaned data will then be stored in different formats such as CSV, databases, and S3 buckets to make it easier for future decision-making.
Without further ado, let’s get started!
Why Clean Web-Scraped Data?
In today's data-driven world, it’s important to have clean, reliable data for making informed decisions. Data collected from web sources often contains errors, inconsistencies, and noise, which need to be addressed before analysis.
Issues such as duplicate records, missing values, and variations in formats can compromise the accuracy of the analysis. Through data cleaning, raw scraped data can be transformed into high-quality datasets, ready for extracting actionable insights.
How to Clean Our Web-Scraped Data?
In Part 2, we scraped data and stored it in a JSON file. Here's an example:
{
"colorDescription": "Anthracite/Sail/Legend Sand/Jade Smoke",
"currency": "USD",
"currentPrice": 86.97,
"fullPrice": 115,
"inStock": true,
"title": "Air Jordan 1 Low",
"subtitle": "Women's Shoes",
"url": "https://www.nike.com/en/t/air-jordan-1-low-womens-shoes-rJrHLw/DC0774-001"
}
While this data looks clean, we should still check for potential issues, such as missing text or formatting inconsistencies. Here’s how we can do this:
- Missing Values: Check each text field for missing data. If a field is empty, replace it with a placeholder like ‘missing’.
- Whitespace Removal: Strip any extraneous whitespace from fields such as
title,subtitle, andcolorDescription. - Discount Calculation: Calculate the discount percentage by comparing
currentPricewithfullPrice. For example, if the current price is $86.97 and the full price is $115, the discount percentage is approximately 24%. Add this as a new field to help users understand the savings associated with each product.
By performing these checks, we can ensure our data is clean and ready to be stored in various formats.
Structuring Data with Python Data Classes
In web scraping, structuring data effectively is crucial. Python dataclasses provide a great way to structure the data extracted from web scraping. It automatically generates methods like __init__, __repr__, and other helpful methods for you, reducing boilerplate code.
Moreover, You can easily convert dataclasses to dictionaries or other formats for further processing or storage.
Let's go through how to use Python dataclasses to structure extracted data effectively.
Initializing the Dataclass
Let’s define a Product class using the dataclass decorator:
@dataclass
class Product:
title: str = ""
subtitle: str = ""
color_description: str = ""
currency: str = ""
current_price: float = 0.0
full_price: float = 0.0
in_stock: bool = True
url: str = ""
discount_percentage: float = field(init=False)
In the Product class, the following attributes are defined:
title,subtitle,color_description,currency, andurlare strings with default empty values.current_priceandfull_priceare floats with default values of 0.0.in_stockis a boolean with a default value ofTrue.discount_percentageis a float that is not initialized through the constructor (init=False). This means it must be set or calculated later.
When creating a Product object, you need to provide values for title, current_price, full_price, etc., but you do not provide a value for discount_percentage. The discount_percentage value will be computed based on the current_price and full_price.
Cleaning and Validating Data During Initialization
After initializing the Product object, the __post_init__ method is automatically called, allowing us to perform additional data processing.
@dataclass
class Product:
# ...
def __post_init__(self):
self.title = self.clean_text(self.title)
self.subtitle = self.clean_text(self.subtitle)
self.color_description = self.clean_text(self.color_description)
self.currency = self.clean_text(self.currency)
self.url = self.clean_url()
self.discount_percentage = round(
self.calculate_discount(self.current_price, self.full_price)
)
This method ensures that after the Product object is created, text attributes are cleaned, the URL is formatted, and the discount percentage is calculated and rounded.
Implementing Data Cleaning Methods
Let’s create the helper methods clean_text and clean_url, which are used to clean text and URLs, respectively.
@dataclass
class Product:
# ...
def __post_init__(self):
# ..
def clean_text(self, text):
return text.strip() if text else "missing"
def clean_url(self):
return self.url if self.url else "missing"
Calculating Discount Percentage
Finally, we implemented a method to calculate the discount percentage based on the current and full prices. If the full price is greater than zero, the method computes the discount; otherwise, it returns 0.0.
@dataclass
class Product:
# ...
def __post_init__(self):
# ...
def calculate_discount(self, current_price, full_price):
if full_price > 0:
return ((full_price - current_price) / full_price) * 100
return 0.0
This method automatically calculates the discount percentage and stores it as part of the Product data class. Therefore, every time a product is created, its discount percentage is calculated.
Complete Data Class Implementation
Here is the complete code for our Product data class, encapsulating all the steps we've discussed:
@dataclass
class Product:
title: str = ""
subtitle: str = ""
color_description: str = ""
currency: str = ""
current_price: float = 0.0
full_price: float = 0.0
in_stock: bool = True
url: str = ""
discount_percentage: float = field(init=False)
def __post_init__(self):
self.title = self.clean_text(self.title)
self.subtitle = self.clean_text(self.subtitle)
self.color_description = self.clean_text(self.color_description)
self.currency = self.clean_text(self.currency)
self.url = self.clean_url()
self.discount_percentage = round(
self.calculate_discount(self.current_price, self.full_price)
)
def clean_text(self, text):
return text.strip() if text else "missing"
def clean_url(self):
return self.url if self.url else "missing"
def calculate_discount(self, current_price, full_price):
if full_price > 0:
return ((full_price - current_price) / full_price) * 100
return 0.0
Here’s the snapshot of the data that will be returned from the Product data class.
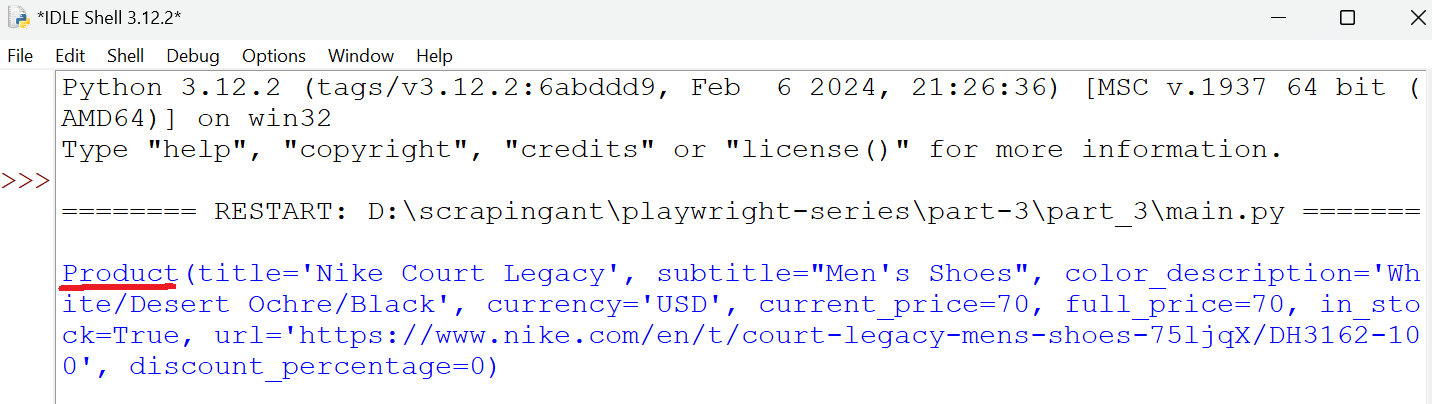
Managing Data Flow with Data Pipeline
Once our data is structured and cleaned using a dataclass, the next step is to manage the flow and storage of this data efficiently. To do this, we will create a new class, ProductDataPipeline, that handles the flow of data from cleaning to storage.
Initializing the Data Pipeline
The ProductDataPipeline class is designed to manage the flow of cleaned data by storing it in a queue and then saving it to various storage options like CSV. We initialize this class with parameters such as the CSV filename and a storage queue limit only.
class ProductDataPipeline:
def __init__(self, csv_filename="nike_shoes.csv", data_queue_limit=10):
self.data_queue = []
self.data_queue_limit = data_queue_limit
self.csv_filename = csv_filename
Note: In later sections, we will look into storing the data in different mediums, such as databases and S3 bucket. At that point, additional parameters will be needed to initialize the class. However, for now, our focus is on the CSV method to ensure that the process remains smooth and easy to understand.
Transforming Raw Data
The clean_raw_data method takes raw data and cleans it using the Product dataclass.
class ProductDataPipeline:
# ...
def clean_raw_data(self, scraped_data):
return Product(
title=scraped_data.get("title", ""),
subtitle=scraped_data.get("subtitle", ""),
color_description=scraped_data.get("colorDescription", ""),
currency=scraped_data.get("currency", ""),
current_price=scraped_data.get("currentPrice", 0.0),
full_price=scraped_data.get("fullPrice", 0.0),
in_stock=scraped_data.get("inStock", True),
url=scraped_data.get("url", ""),
)
This method ensures that all data we process is cleaned and structured before being added to our pipeline.
Adding Data to the Pipeline
The enqueue_product method receives raw data and sends it to the clean_raw_data method. This method processes the data and returns organized and cleaned data, which is then stored in the data queue. When the queue reaches a specific limit, it triggers the save_to_csv method to save the data to a CSV file.
class ProductDataPipeline:
# ...
def enqueue_product(self, scraped_data):
product = self.clean_raw_data(scraped_data)
self.data_queue.append(product)
if len(self.data_queue) >= self.data_queue_limit:
self.save_to_csv()
self.data_queue.clear()
When processing large volumes of data, using a queue with a limit helps manage memory usage and optimize I/O operations by processing and saving data in batches.
💡Important Note: To prevent duplicate entries and prepare for the next data batch, clear the data_queue after the data is saved to different storage mediums.
Saving Data to CSV
Finally, save the data to the CSV file.
class ProductDataPipeline:
# ...
def save_to_csv(self):
data_batch = []
data_batch.extend(self.data_queue)
if not data_batch:
return
header_order = [
"title",
"subtitle",
"color_description",
"currency",
"current_price",
"full_price",
"discount_percentage",
"in_stock",
"url",
]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=header_order)
if not file_exists:
writer.writeheader()
for product in data_batch:
product_dict = asdict(product)
reordered_product_dict = {
field: product_dict[field] for field in header_order
}
writer.writerow(reordered_product_dict)
This method saves data from a queue to a CSV file. It first extracts all data from the queue into a batch, clears the queue, and then writes the batch to the CSV file.
Closing the Pipeline
Finally, when the pipeline is closed, any remaining products in the queue are saved to the CSV file. This ensures that no data is lost when the pipeline finishes its operation.
class ProductDataPipeline:
# ...
def close_pipeline(self):
if len(self.storage_queue) > 0:
self.save_to_csv()
Complete Data Pipeline Implementation
Here is the complete code for the ProductDataPipeline class, encapsulating all the steps we’ve discussed:
class ProductDataPipeline:
def __init__(self, csv_filename="nike_shoes.csv", data_queue_limit=10):
self.data_queue = []
self.data_queue_limit = data_queue_limit
self.csv_filename = csv_filename
def clean_raw_data(self, scraped_data):
return Product(
title=scraped_data.get("title", ""),
subtitle=scraped_data.get("subtitle", ""),
color_description=scraped_data.get("colorDescription", ""),
currency=scraped_data.get("currency", ""),
current_price=scraped_data.get("currentPrice", 0.0),
full_price=scraped_data.get("fullPrice", 0.0),
in_stock=scraped_data.get("inStock", True),
url=scraped_data.get("url", ""),
)
def enqueue_product(self, scraped_data):
product = self.clean_raw_data(scraped_data)
self.data_queue.append(product)
if len(self.data_queue) >= self.data_queue_limit:
self.save_to_csv()
self.data_queue.clear()
def save_to_csv(self):
data_batch = []
data_batch.extend(self.data_queue)
if not data_batch:
return
header_order = [
"title",
"subtitle",
"color_description",
"currency",
"current_price",
"full_price",
"discount_percentage",
"in_stock",
"url",
]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=header_order)
if not file_exists:
writer.writeheader()
for product in data_batch:
product_dict = asdict(product)
reordered_product_dict = {
field: product_dict[field] for field in header_order
}
writer.writerow(reordered_product_dict)
def close_pipeline(self):
if len(self.data_queue) > 0:
self.save_to_csv()
Full Code: Product Dataclass & Data Pipeline
Here’s the complete code integrating the Product Dataclass with the Data Pipeline:
import asyncio
import csv
import os
from contextlib import suppress
from dataclasses import dataclass, field, asdict
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Playwright, Response, async_playwright
@dataclass
class Product:
title: str = ""
subtitle: str = ""
color_description: str = ""
currency: str = ""
current_price: float = 0.0
full_price: float = 0.0
in_stock: bool = True
url: str = ""
discount_percentage: float = field(init=False)
def __post_init__(self):
self.title = self.clean_text(self.title)
self.subtitle = self.clean_text(self.subtitle)
self.color_description = self.clean_text(self.color_description)
self.currency = self.clean_text(self.currency)
self.url = self.clean_url()
self.discount_percentage = round(
self.calculate_discount(self.current_price, self.full_price)
)
def clean_text(self, text):
return text.strip() if text else "missing"
def clean_url(self):
if self.url == "":
return "missing"
return self.url
def calculate_discount(self, current_price, full_price):
if full_price > 0:
return ((full_price - current_price) / full_price) * 100
return 0.0
class ProductDataPipeline:
def __init__(self, csv_filename="nike_shoes.csv", data_queue_limit=10):
"""Initialize the product data pipeline."""
self.data_queue = []
self.data_queue_limit = data_queue_limit
self.csv_filename = csv_filename
def save_to_csv(self):
"""Save the product data to a CSV file."""
data_batch = []
data_batch.extend(self.data_queue)
if not data_batch:
return
# Define the desired order of headers
header_order = [
"title",
"subtitle",
"color_description",
"currency",
"current_price",
"full_price",
"discount_percentage",
"in_stock",
"url",
]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(
self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=header_order)
if not file_exists:
writer.writeheader()
for product in data_batch:
product_dict = asdict(product)
# Reorder fields according to header_order
reordered_product_dict = {
field: product_dict[field] for field in header_order
}
writer.writerow(reordered_product_dict)
def clean_raw_data(self, scraped_data):
"""Clean and create a Product instance from raw scraped data."""
return Product(
title=scraped_data.get("title", ""),
subtitle=scraped_data.get("subtitle", ""),
color_description=scraped_data.get("colorDescription", ""),
currency=scraped_data.get("currency", ""),
current_price=scraped_data.get("currentPrice", 0.0),
full_price=scraped_data.get("fullPrice", 0.0),
in_stock=scraped_data.get("inStock", True),
url=scraped_data.get("url", ""),
)
def enqueue_product(self, scraped_data):
"""Enqueue a new product to the pipeline and save data if queue limit is reached."""
product = self.clean_raw_data(scraped_data)
self.data_queue.append(product)
if len(self.data_queue) >= self.data_queue_limit:
self.save_to_csv()
self.data_queue.clear()
def close_pipeline(self):
"""Save remaining data and close the pipeline."""
if len(self.data_queue) > 0:
self.save_to_csv()
class ShoeScraper:
def __init__(
self, playwright: Playwright, target_url: str, pipeline: ProductDataPipeline
):
"""Initialize the shoe scraper with Playwright, target URL, and data pipeline."""
self.playwright = playwright
self.target_url = target_url
self.pipeline = pipeline
async def scroll_to_bottom(self, page) -> None:
"""Scroll to the bottom of the page to load all products."""
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(1)
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
iteration += 1
async def block_resources(self, page) -> None:
"""Block unnecessary resources to speed up scraping."""
async def intercept_route(route, request):
if request.resource_type in ["image", "stylesheet", "font", "xhr"]:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept_route)
async def extract_product_data(self, response: Response) -> None:
"""Extract product data from the response and add it to the pipeline."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryid" in query_params and query_params["queryid"][0] == "products":
data = await response.json()
with suppress(KeyError):
for product in data["data"]["products"]["products"]:
product_details = {
"colorDescription": product["colorDescription"],
"currency": product["price"]["currency"],
"currentPrice": product["price"]["currentPrice"],
"fullPrice": product["price"]["fullPrice"],
"inStock": product["inStock"],
"title": product["title"],
"subtitle": product["subtitle"],
"url": product["url"].replace(
"{countryLang}", "https://www.nike.com/en"
),
}
self.pipeline.enqueue_product(product_details)
async def scrape(self) -> None:
"""Perform the scraping process."""
browser = await self.playwright.chromium.launch(headless=True)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
await self.block_resources(page)
page.on("response", lambda response: self.extract_product_data(response))
await page.goto(self.target_url)
await asyncio.sleep(2)
await self.scroll_to_bottom(page)
await browser.close()
async def main() -> None:
"""Main function to initialize and run the scraping process."""
async with async_playwright() as playwright:
pipeline = ProductDataPipeline(csv_filename="nike_shoes.csv")
scraper = ShoeScraper(
playwright=playwright,
target_url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
pipeline=pipeline,
)
await scraper.scrape()
pipeline.close_pipeline()
if __name__ == "__main__":
asyncio.run(main())
Run the code to generate the CSV file in your directory. Below is a preview of the data that will be saved in the CSV file:
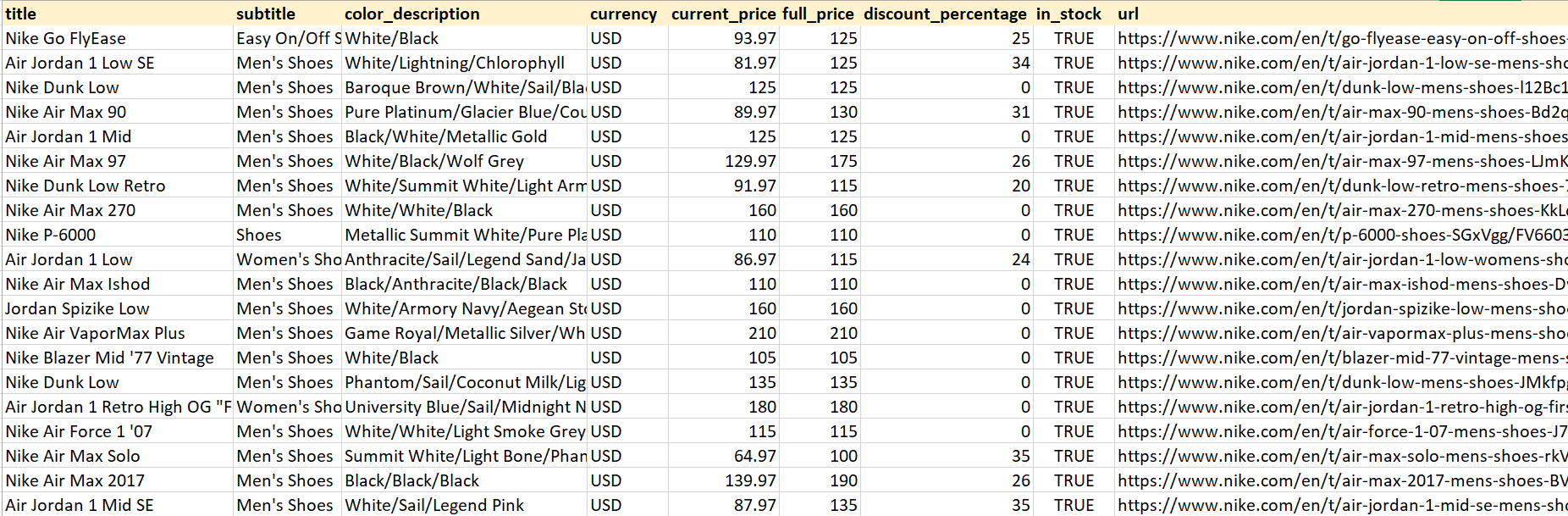
Nice! The dataset looks clean and structured.
Storing Data into Different Formats
Now, let’s explore how to store data in databases such as SQLite and MySQL, as well as in an Amazon S3 bucket. We’ve previously covered storing data in a CSV file.
Storing Data in SQLite
SQLite is a serverless, self-contained database engine. This means you don't need to set up or maintain a database server, making it easy to use and integrate into small to medium-sized projects. SQLite stores data in a single .db file, which makes it portable and easy to share or back up. You can easily move this file across systems without worrying about compatibility.
Below is a simple code snippet to use the SQLite database in our project:
# ...
import sqlite3
class ProductDataPipeline:
def __init__(self, db_filename="nike_shoes.db"):
# ...
self.db_filename = db_filename
self.create_table()
def create_table(self):
with sqlite3.connect(self.db_filename) as conn:
cursor = conn.cursor()
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS nike_shoes (
title TEXT,
subtitle TEXT,
color_description TEXT,
currency TEXT,
current_price REAL,
full_price REAL,
discount_percentage REAL,
in_stock BOOLEAN,
url TEXT
)
"""
)
conn.commit()
def save_to_sqlite(self):
with sqlite3.connect(self.db_filename) as conn:
cursor = conn.cursor()
for product in self.storage_queue:
cursor.execute(
"""
INSERT INTO nike_shoes (title, subtitle, color_description, currency, current_price, full_price, discount_percentage, in_stock, url)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""",
(
product.title,
product.subtitle,
product.color_description,
product.currency,
product.current_price,
product.full_price,
product.discount_percentage,
product.in_stock,
product.url,
),
)
conn.commit()
The save_to_sqlite() function processes scraped product data from the data_queue. For each product, an SQL INSERT INTO command adds the product details to the nike_shoes table. After all data is inserted, conn.commit() permanently saves changes. To prevent duplicate entries and prepare for the next data batch, the data_queue is cleared once the data is saved to the SQLite database.
The code begins by importing the sqlite3 library to interact directly with an SQLite database from Python. It establishes a connection to a database file named nike_shoes.db using sqlite3.connect() (the file is created if it doesn't exist). The create_table() method then executes an SQL command to create a nike_shoes table with columns for product attributes such as title, subtitle, price, and so on.
The save_to_sqlite() method processes the scraped product data from the data_queue. For each product, an SQL INSERT INTO command is executed to add the product data to the nike_shoes table. Once all the data is inserted, conn.commit() is used to permanently save the changes.
Once the code is successfully executed, the nike_shoes.db file will be created in your directory. You can upload this .db file to an online SQLite viewer to view and query your database directly in a browser.
The result is:
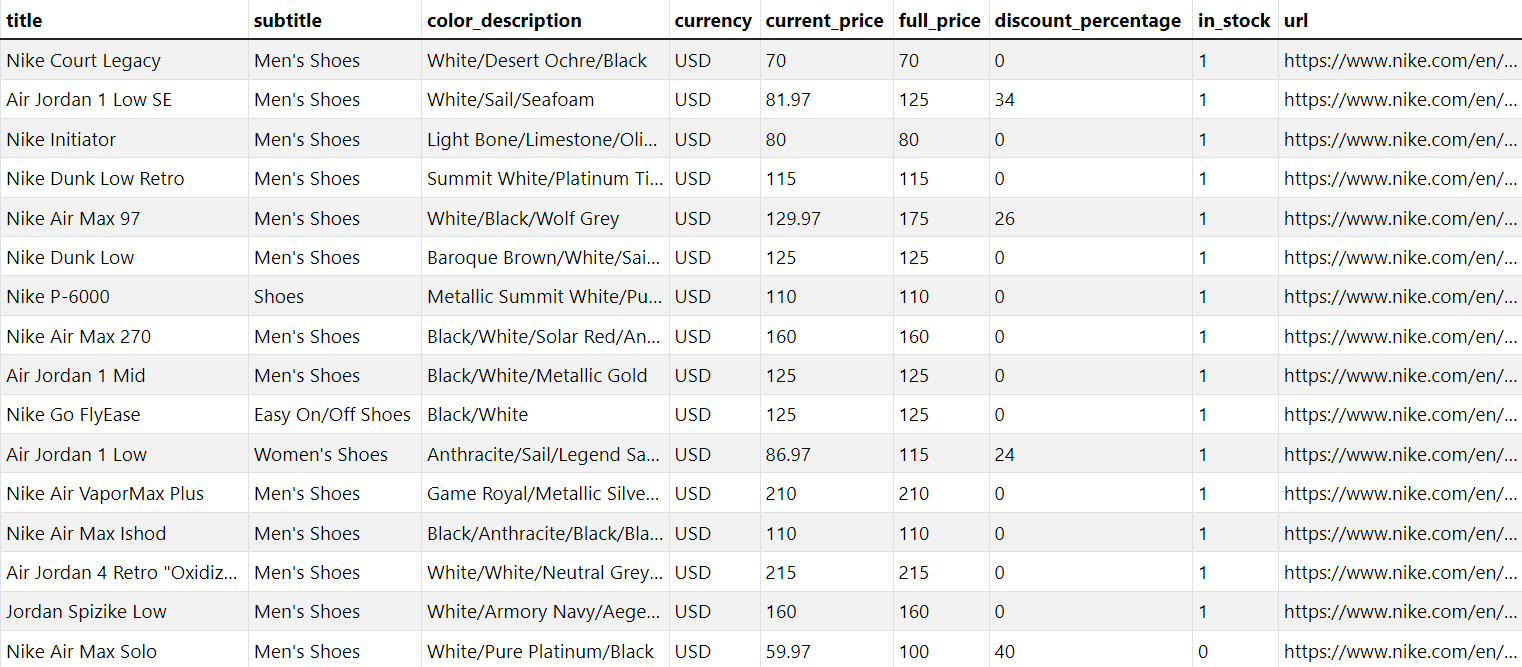
Storing Data in MySQL
In this section, we will demonstrate how to save data to a MySQL database. We assume that you already have a database named "nike_shoes_db" set up.
Let’s start by installing the MySQL Connector/Python, which allows us to interact with the MySQL database using Python.
pip install mysql-connector-python
Next, import the mysql.connector library, which is essential for connecting to and interacting with our MySQL database. We also import the Error class from mysql.connector to handle any errors that might occur during database operations.
import mysql.connector
from mysql.connector import Error
In the ProductDataPipeline class, pass the dictionary containing our MySQL database configuration. This configuration includes details such as the database user, password, host, and database name. Then, call the create_mysql_table method to create a table for storing the data.
class ProductDataPipeline:
def __init__(self, mysql_db_config=None):
# ...
self.mysql_db_config = mysql_db_config
if self.mysql_db_config:
self.create_mysql_table()
The create_mysql_table method connects to the MySQL database using the provided configuration (mysql_db_config) and creates a nike_shoes table with specified columns if it doesn't already exist.
The method also handles any connection or execution errors and ensures the connection is properly closed after the operation.
class ProductDataPipeline:
# ...
def create_mysql_table(self):
try:
conn = mysql.connector.connect(**self.mysql_db_config)
cursor = conn.cursor()
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS nike_shoes (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
subtitle VARCHAR(255),
color_description VARCHAR(255),
currency VARCHAR(10),
current_price DECIMAL(10, 2),
full_price DECIMAL(10, 2),
discount_percentage DECIMAL(5, 2),
in_stock BOOLEAN,
url VARCHAR(255)
)
"""
)
conn.commit()
cursor.close()
conn.close()
except Error as e:
print(f"Error creating MySQL table: {e}")
The save_to_mysql method iterates over the data_queue, which contains all the product data we’ve collected. For each product, it executes an INSERT SQL command to add the product’s details to the nike_shoes table.
The method also handles any errors that might occur during the data insertion process and ensures that all changes are committed to the database.
class ProductDataPipeline:
# ...
def save_to_mysql(self):
try:
conn = mysql.connector.connect(**self.mysql_db_config)
cursor = conn.cursor()
for product in self.data_queue:
cursor.execute(
"""
INSERT INTO nike_shoes (title, subtitle, color_description, currency, current_price, full_price, discount_percentage, in_stock, url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
""",
(
product.title,
product.subtitle,
product.color_description,
product.currency,
product.current_price,
product.full_price,
product.discount_percentage,
product.in_stock,
product.url,
),
)
conn.commit()
cursor.close()
conn.close()
except Error as e:
print(f"Error saving data to MySQL: {e}")
Finally, in the main function, we set up our database configuration and initialize the ProductDataPipeline with it.
async def main() -> None:
mysql_db_config = {
"user": "root",
"password": "satyam@123",
"host": "localhost",
"database": "nike_shoes_db",
}
async with async_playwright() as playwright:
pipeline = ProductDataPipeline(mysql_db_config=mysql_db_config)
# ...
Here’s the snapshot of the data stored in the MySQL database:
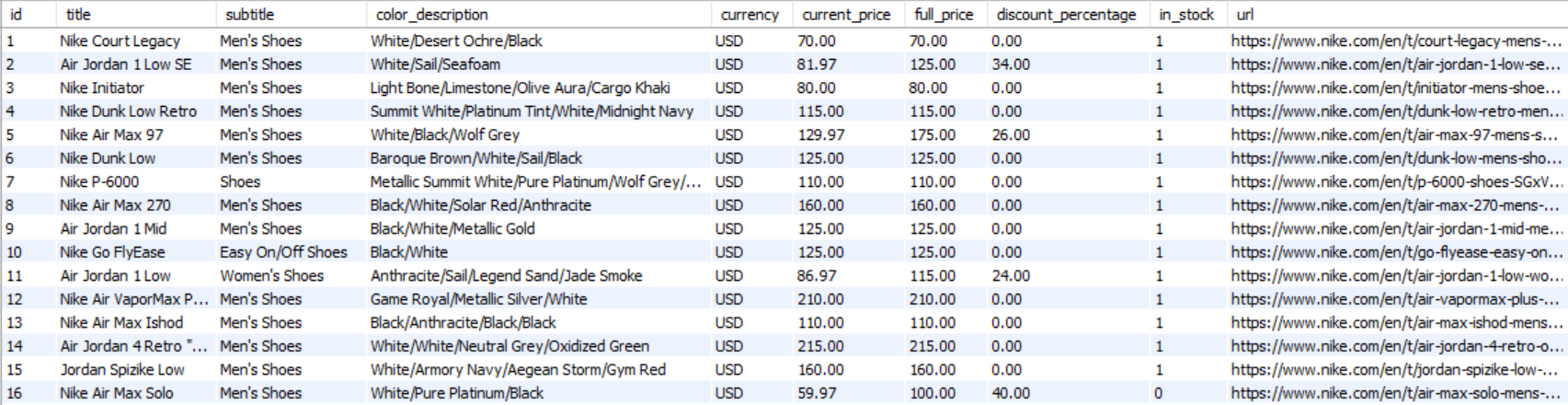
Saving Data to S3 Bucket
We have already covered how to export the data to a CSV file. Now, let's save the CSV file we created to an Amazon S3 bucket. If you don't have a bucket yet, you can follow the instructions on how to set one up.
Once you have a bucket, install the Boto3 library, a popular AWS SDK for Python.
pip install boto3
Here’s the code:
import boto3
class ProductDataPipeline:
# ...
def save_to_s3_bucket(self):
aws_access_key_id = "YOUR_AWS_ACCESS_KEY_ID"
aws_secret_access_key = "YOUR_AWS_SECRET_ACCESS_KEY"
s3_client = boto3.client(
"s3",
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
)
response = s3_client.put_object(
Bucket=self.aws_s3_bucket,
Key="nike_shoes.csv",
Body=open("nike_shoes.csv", "rb"),
)
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")
if status != 200:
print(f"Failed to upload data to S3 bucket. Status code: {status}")
In the code, we start by initializing the S3 client using the boto3.client method. Here, you have to provide your AWS access key ID and secret access key, which authenticate your requests to AWS.
The put_object method is used to upload your file to the specified S3 bucket. In this example, we're uploading a file named nike_shoes.csv to the S3 bucket.
Finally, we check the response status code. If the status code is 200, the file has been successfully uploaded.
Note: Remember to replace the aws_access_key_id and aws_secret_access_key with your actual credentials.
Here’s the snapshot showing that the file has been successfully uploaded:
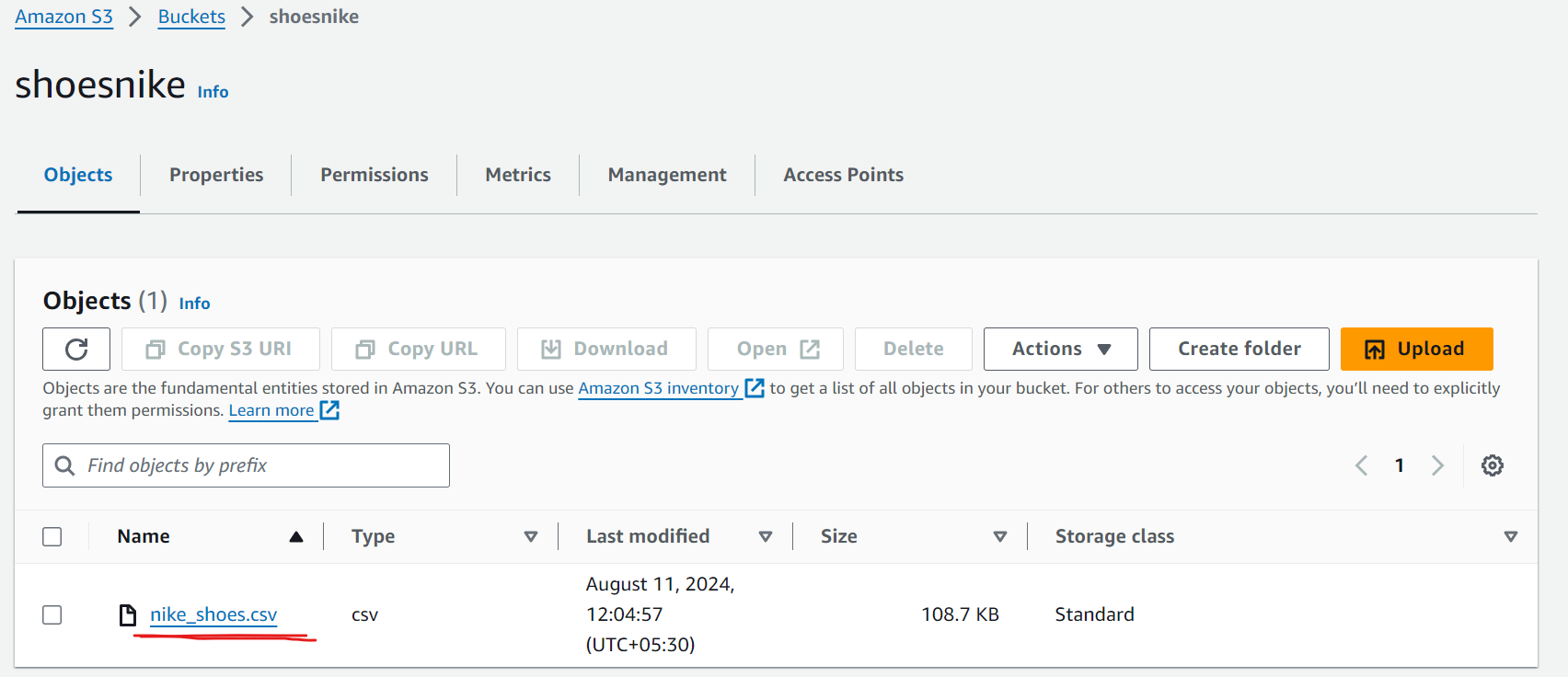
Final Code
Here is the final code that handles extracting data from the Nike website, cleaning it, and storing it in multiple formats such as CSV, SQLite, MySQL, and AWS S3.
Before running this code, make sure to set up your environment with the required dependencies. Once everything is configured, you can execute the script to begin the scraping process and automatically save the data in different storage options.
import asyncio
import csv
import boto3
import os
import sqlite3
import mysql.connector
from mysql.connector import Error
from contextlib import suppress
from dataclasses import dataclass, field, asdict
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Playwright, Response, async_playwright
@dataclass
class Product:
title: str = ""
subtitle: str = ""
color_description: str = ""
currency: str = ""
current_price: float = 0.0
full_price: float = 0.0
in_stock: bool = True
url: str = ""
discount_percentage: float = field(init=False)
def __post_init__(self):
self.title = self.clean_text(self.title)
self.subtitle = self.clean_text(self.subtitle)
self.color_description = self.clean_text(self.color_description)
self.currency = self.clean_text(self.currency)
self.url = self.clean_url()
self.discount_percentage = round(
self.calculate_discount(self.current_price, self.full_price)
)
def clean_text(self, text):
return text.strip() if text else "missing"
def clean_url(self):
if self.url == "":
return "missing"
return self.url
def calculate_discount(self, current_price, full_price):
if full_price > 0:
return ((full_price - current_price) / full_price) * 100
return 0.0
class ProductDataPipeline:
def __init__(
self,
csv_filename="nike_shoes.csv",
sqlite_db_filename="nike_shoes.db",
mysql_db_config=None,
aws_s3_bucket=None,
data_queue_limit=10,
):
"""Initialize the product data pipeline."""
self.data_queue = []
self.data_queue_limit = data_queue_limit
self.csv_filename = csv_filename
self.sqlite_db_filename = sqlite_db_filename
self.mysql_db_config = mysql_db_config
self.aws_s3_bucket = aws_s3_bucket
self.create_sqlite_table()
if self.mysql_db_config:
self.create_mysql_table()
def create_sqlite_table(self):
"""Create SQLite table if it does not exist."""
with sqlite3.connect(self.sqlite_db_filename) as conn:
cursor = conn.cursor()
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS nike_shoes (
title TEXT,
subtitle TEXT,
color_description TEXT,
currency TEXT,
current_price REAL,
full_price REAL,
discount_percentage REAL,
in_stock BOOLEAN,
url TEXT
)
"""
)
conn.commit()
def create_mysql_table(self):
"""Create MySQL table if it does not exist."""
try:
conn = mysql.connector.connect(**self.mysql_db_config)
cursor = conn.cursor()
cursor.execute(
"""
CREATE TABLE IF NOT EXISTS nike_shoes (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
subtitle VARCHAR(255),
color_description VARCHAR(255),
currency VARCHAR(10),
current_price DECIMAL(10, 2),
full_price DECIMAL(10, 2),
discount_percentage DECIMAL(5, 2),
in_stock BOOLEAN,
url VARCHAR(255)
)
"""
)
conn.commit()
cursor.close()
conn.close()
except Error as e:
print(f"Error creating MySQL table: {e}")
async def save_to_s3_bucket(self):
"""Upload the CSV file to S3 bucket."""
aws_access_key_id = "YOUR_AWS_ACCESS_KEY_ID"
aws_secret_access_key = "YOUR_AWS_SECRET_ACCESS_KEY"
s3_client = boto3.client(
"s3",
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
)
with open(self.csv_filename, "rb") as file:
response = s3_client.put_object(
Bucket=self.aws_s3_bucket,
Key=os.path.basename(self.csv_filename),
Body=file,
)
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")
if status != 200:
print(f"Failed to upload data to S3 bucket. Status code: {status}")
def save_to_csv(self):
"""Save the product data to a CSV file."""
data_batch = []
data_batch.extend(self.data_queue)
if not data_batch:
return
header_order = [
"title",
"subtitle",
"color_description",
"currency",
"current_price",
"full_price",
"discount_percentage",
"in_stock",
"url",
]
file_exists = (
os.path.isfile(self.csv_filename) and os.path.getsize(
self.csv_filename) > 0
)
with open(self.csv_filename, mode="a", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=header_order)
if not file_exists:
writer.writeheader()
for product in data_batch:
product_dict = asdict(product)
reordered_product_dict = {
field: product_dict[field] for field in header_order
}
writer.writerow(reordered_product_dict)
def save_to_sqlite(self):
"""Save the product data to an SQLite database."""
with sqlite3.connect(self.sqlite_db_filename) as conn:
cursor = conn.cursor()
for product in self.data_queue:
cursor.execute(
"""
INSERT INTO nike_shoes (title, subtitle, color_description, currency, current_price, full_price, discount_percentage, in_stock, url)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""",
(
product.title,
product.subtitle,
product.color_description,
product.currency,
product.current_price,
product.full_price,
product.discount_percentage,
product.in_stock,
product.url,
),
)
conn.commit()
def save_to_mysql(self):
"""Save the product data to a MySQL database."""
try:
conn = mysql.connector.connect(**self.mysql_db_config)
cursor = conn.cursor()
for product in self.data_queue:
cursor.execute(
"""
INSERT INTO nike_shoes (title, subtitle, color_description, currency, current_price, full_price, discount_percentage, in_stock, url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
""",
(
product.title,
product.subtitle,
product.color_description,
product.currency,
product.current_price,
product.full_price,
product.discount_percentage,
product.in_stock,
product.url,
),
)
conn.commit()
cursor.close()
conn.close()
except Error as e:
print(f"Error saving data to MySQL: {e}")
def clean_raw_data(self, scraped_data):
"""Clean and create a Product instance from raw scraped data."""
return Product(
title=scraped_data.get("title", ""),
subtitle=scraped_data.get("subtitle", ""),
color_description=scraped_data.get("colorDescription", ""),
currency=scraped_data.get("currency", ""),
current_price=scraped_data.get("currentPrice", 0.0),
full_price=scraped_data.get("fullPrice", 0.0),
in_stock=scraped_data.get("inStock", True),
url=scraped_data.get("url", ""),
)
def enqueue_product(self, scraped_data):
"""Add a new product to the pipeline and save data if queue limit is reached."""
product = self.clean_raw_data(scraped_data)
self.data_queue.append(product)
if len(self.data_queue) >= self.data_queue_limit:
self.save_data()
def save_data(self):
"""Save data to all storage options."""
if not self.data_queue:
return
self.save_to_csv()
self.save_to_sqlite()
if self.mysql_db_config:
self.save_to_mysql()
self.data_queue.clear()
async def close_pipeline(self):
"""Save remaining data and close the pipeline."""
if len(self.data_queue) > 0:
self.save_data()
await self.save_to_s3_bucket()
print("Pipeline closed and all remaining data saved.")
class ShoeScraper:
def __init__(
self, playwright: Playwright, target_url: str, pipeline: ProductDataPipeline
):
"""Initialize the shoe scraper with Playwright, target URL, and data pipeline."""
self.playwright = playwright
self.target_url = target_url
self.pipeline = pipeline
async def scroll_to_bottom(self, page) -> None:
"""Scroll to the bottom of the page to load all products."""
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(1)
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
iteration += 1
async def block_resources(self, page) -> None:
"""Block unnecessary resources to speed up scraping."""
async def intercept_route(route, request):
if request.resource_type in ["image", "stylesheet", "font", "xhr"]:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept_route)
async def extract_product_data(self, response: Response) -> None:
"""Extract product data from the response and add it to the pipeline."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryid" in query_params and query_params["queryid"][0] == "products":
data = await response.json()
with suppress(KeyError):
for product in data["data"]["products"]["products"]:
product_details = {
"colorDescription": product["colorDescription"],
"currency": product["price"]["currency"],
"currentPrice": product["price"]["currentPrice"],
"fullPrice": product["price"]["fullPrice"],
"inStock": product["inStock"],
"title": product["title"],
"subtitle": product["subtitle"],
"url": product["url"].replace(
"{countryLang}", "https://www.nike.com/en"
),
}
self.pipeline.enqueue_product(product_details)
async def scrape(self) -> None:
"""Perform the scraping process."""
browser = await self.playwright.chromium.launch(headless=True)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
await self.block_resources(page)
page.on("response", lambda response: self.extract_product_data(response))
await page.goto(self.target_url)
await asyncio.sleep(2)
await self.scroll_to_bottom(page)
await browser.close()
print("Scraping completed and browser closed.")
async def main() -> None:
"""Main function to initialize and run the scraping process."""
mysql_db_config = {
"user": "root",
"password": "YOUR_PASSWORD",
"host": "localhost",
"database": "YOUR_MYSQL_DB_NAME",
}
async with async_playwright() as playwright:
pipeline = ProductDataPipeline(
csv_filename="nike_shoes.csv",
sqlite_db_filename="nike_shoes.db",
mysql_db_config=mysql_db_config,
aws_s3_bucket="YOUR_S3_BUCKET_NAME",
)
scraper = ShoeScraper(
playwright=playwright,
target_url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
pipeline=pipeline,
)
await scraper.scrape()
print("Data scraped. Saving to S3 and databases...")
await pipeline.save_to_s3_bucket()
await pipeline.close_pipeline()
if __name__ == "__main__":
asyncio.run(main())
Next Steps
We hope you now have a good understanding of how to clean and save the data you've scraped into different storage mediums such as CSV, databases, or S3 buckets.
In Part 4, we will explore ways to circumvent common website security measures by utilizing techniques such as proxies, user agents, and web scraping APIs to ensure uninterrupted web scraping.