

In Part 1, you learned about the basics of Playwright, environment setup, browser launching, and taking screenshots.
In Part 2, you’ll learn how to build a scraper from scratch. We'll cover how to locate and extract data, manage dynamically loaded content, utilize Playwright's network event feature, and improve the scraper's performance by blocking unnecessary resources.
Without further ado, let’s get started!
Selecting Data to Scrape
We'll scrape Mens Lifestyle Shoes data from the Nike website for this Playwright Python series. Take a look at the image below:
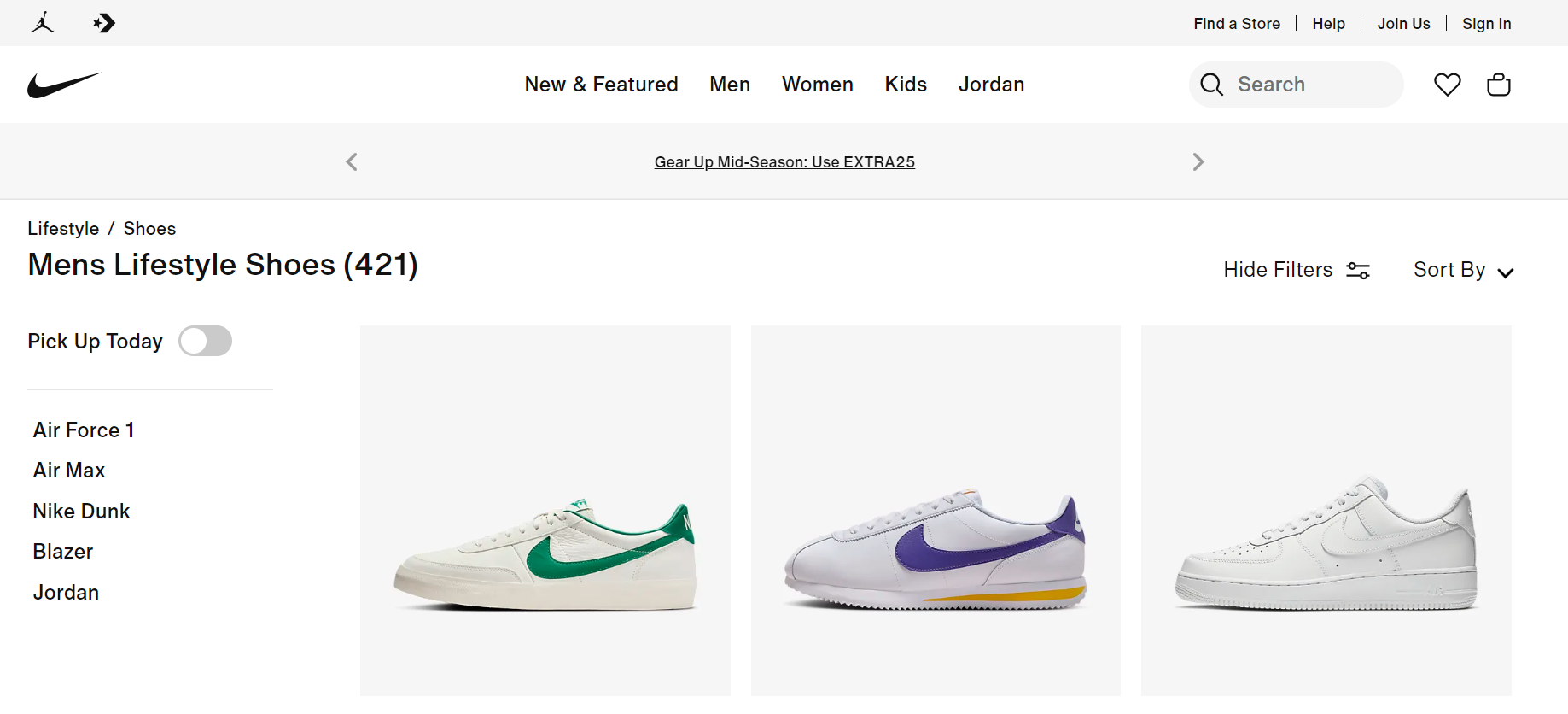
We'll use Playwright to launch a browser, navigate to the Nike product page, and extract the necessary data. This includes the shoe's name, price, page URL, available colors, and other details.
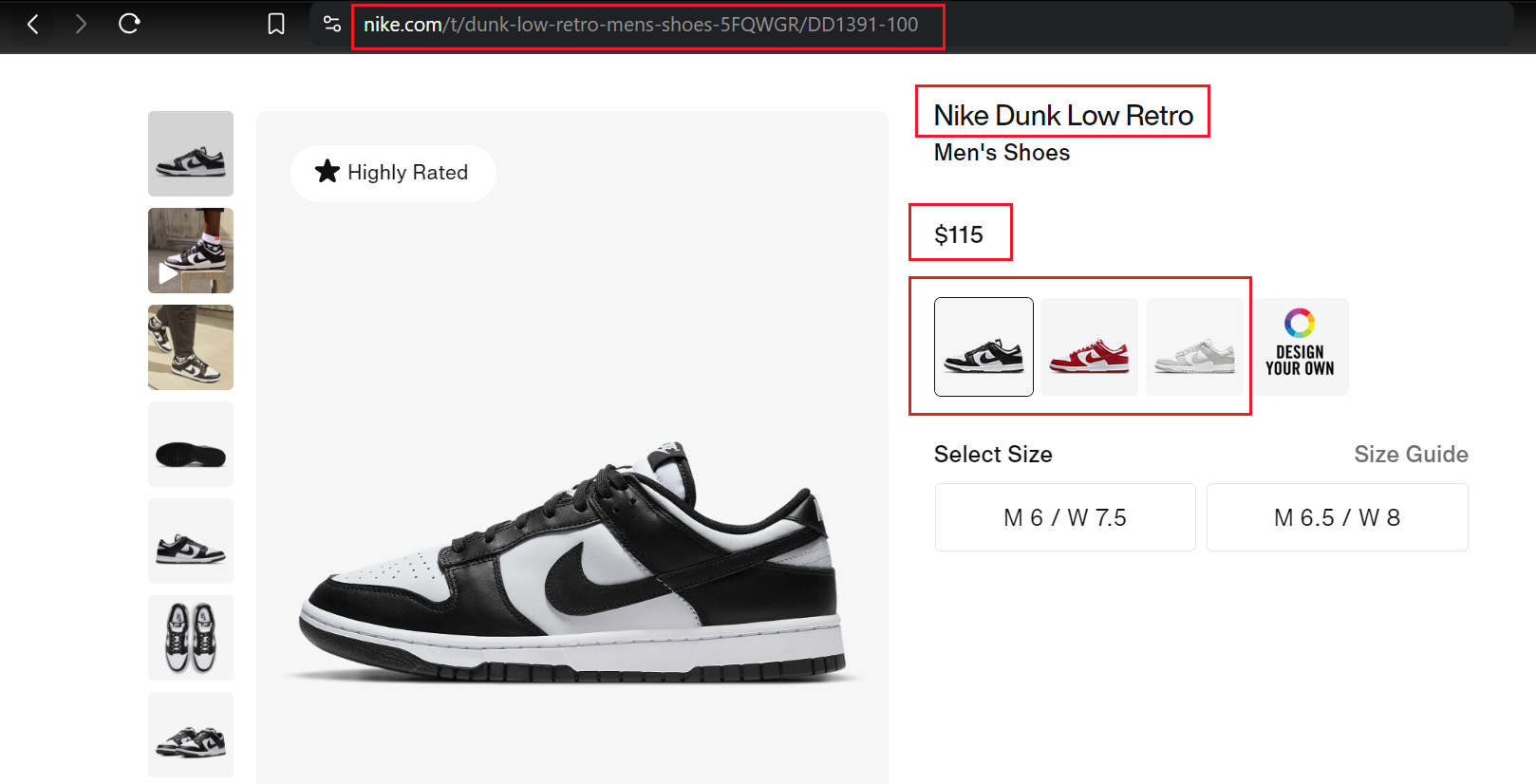
Locating Elements
When building a web scraper, the first crucial step is to identify the webpage elements containing the desired data. To do this effectively, you need to understand the HTML structure of the website.
For example, on the Nike website, each shoe is enclosed within a <div> element with classes such as product-card, product-grid_card, and so on. Each of these <div> elements represents a specific shoe. You can expand each element to view detailed information about the individual shoe.
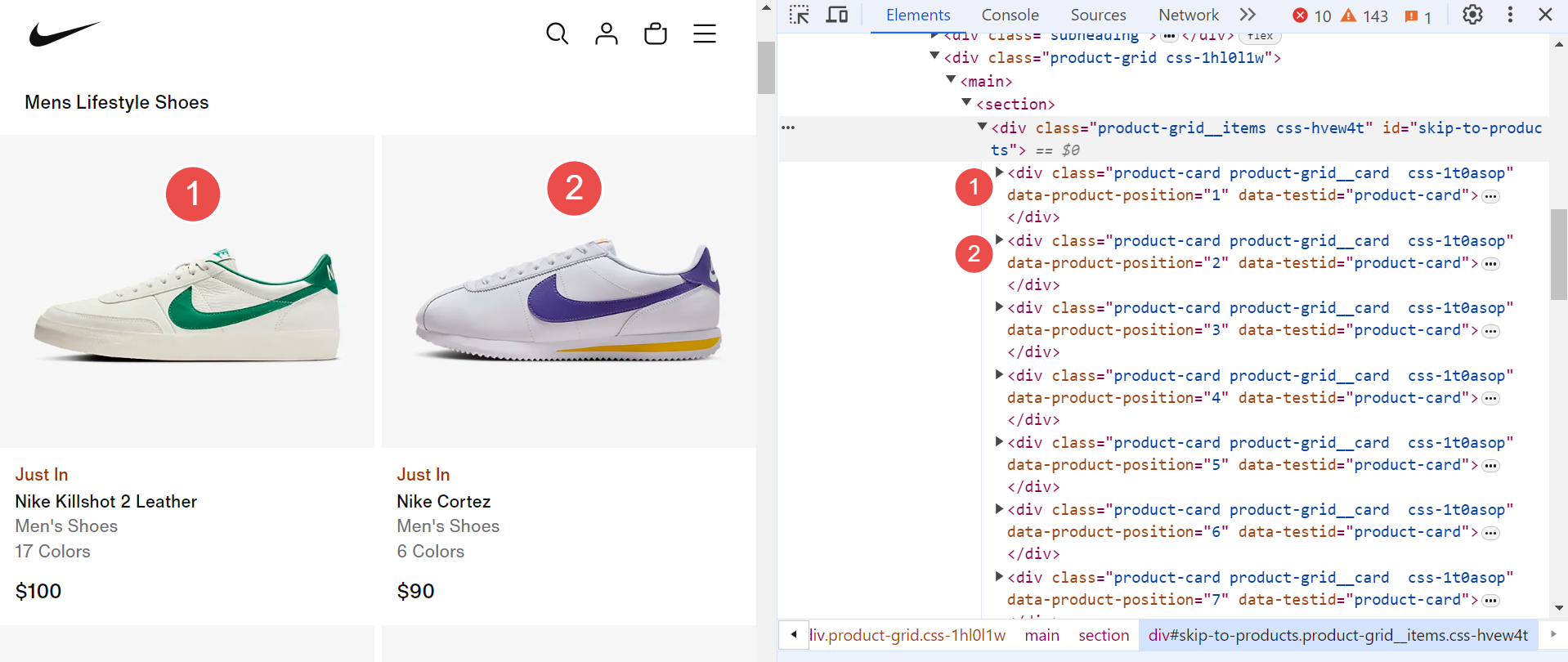
Once you've pinpointed where the data is located, you can use selectors such as CSS selectors or XPath selectors to precisely target and extract the data you need.
Extracting Data
Extracting data is a key part of web scraping. The playwright offers several methods to retrieve data from located elements. Here are two commonly used methods:
- query_selector(selector): This method finds an element matching the specified selector. If no elements match the selector, returns
null. - query_selector_all(selector): The method finds all elements matching the specified selector. If no elements match the selector, returns an empty array.
Continuing with the Nike example, once you've identified target elements like <div>, it's time to extract the desired data from them. To do this, we'll use selectors. These can be CSS selectors, XPath selectors, or others. Here, we'll focus on CSS selectors.
Let's expand the <div> element to determine the necessary selectors for extracting information.

The expanded <div> element above displays complete shoe information. Let's identify the CSS selectors to extract specific data.
- Shoe name:
.product-card__title - Price:
.product-price - Color count:
.product-card__product-count - Status (e.g., Just In, Bestseller):
.product-card__messaging - Shoe link:
.product-card__link-overlay
Great! Let's write a Python Playwright script to extract and print this data to the console.
shoe_containers = await page.query_selector_all(".product-card")
for shoe in shoe_containers:
shoe_name = await shoe.query_selector(".product-card__title")
shoe_name = await shoe_name.text_content() if shoe_name else "N/A"
shoe_price = await shoe.query_selector(".product-price")
shoe_price = await shoe_price.text_content() if shoe_price else "N/A"
shoe_colors = await shoe.query_selector(".product-card__product-count")
shoe_colors = await shoe_colors.text_content() if shoe_colors else "N/A"
shoe_status = await shoe.query_selector(".product-card__messaging")
shoe_status = await shoe_status.text_content() if shoe_status else "N/A"
shoe_link = await shoe.query_selector(".product-card__link-overlay")
shoe_link = await shoe_link.get_attribute("href") if shoe_link else "N/A"
The class product-card represents individual shoe products on the page. We use the page.query_selector_all method to find all elements matching the CSS selector .product-card. This returns a list of shoe containers, each containing shoe details.
We iterate through these containers to extract the desired data using the Playwright method query_selector and various CSS selectors that we have already discussed.
Here's the complete code:
import asyncio
from playwright.async_api import Playwright, async_playwright
async def scrape_shoes(playwright: Playwright, url: str) -> None:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
await page.goto(url)
shoes_list = []
shoe_containers = await page.query_selector_all(".product-card")
for shoe in shoe_containers:
shoe_name = await shoe.query_selector(".product-card__title")
shoe_name = await shoe_name.text_content() if shoe_name else "N/A"
shoe_price = await shoe.query_selector(".product-price")
shoe_price = await shoe_price.text_content() if shoe_price else "N/A"
shoe_colors = await shoe.query_selector(".product-card__product-count")
shoe_colors = await shoe_colors.text_content() if shoe_colors else "N/A"
shoe_status = await shoe.query_selector(".product-card__messaging")
shoe_status = await shoe_status.text_content() if shoe_status else "N/A"
shoe_link = await shoe.query_selector(".product-card__link-overlay")
shoe_link = await shoe_link.get_attribute("href") if shoe_link else "N/A"
shoe_info = {
"name": shoe_name,
"price": shoe_price,
"colors": shoe_colors,
"status": shoe_status,
"link": shoe_link,
}
shoes_list.append(shoe_info)
print(f"Total number of shoes scraped: {len(shoes_list)}")
print(shoes_list)
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_shoes(
playwright=playwright,
url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
)
if __name__ == "__main__":
asyncio.run(main())
Here’s what we are doing in the code:
The script first imports the necessary modules: asyncio for asynchronous operations and Playwright for browser automation.
scrape_shoes Function:
- The function starts by launching a Chromium browser in non-headless mode (
headless=False). - It then opens a new page with a specified viewport size and navigates to the given URL.
- It selects all elements with the class
product-card, which represents individual shoe items. - For each shoe, it extracts details such as name, price, color options, status, and the link to the shoe page. It uses CSS selectors to locate each piece of information and handles cases where some information might be missing.
- The extracted data is stored in a list called
shoes_list. - After collecting data from all the shoes, it prints the total number of items scraped and the data itself.
- Finally, it closes the browser instance using
browser.close.
main Function:
- This function uses an async context manager (
async with async_playwright()) to ensure proper cleanup of Playwright resources. - Inside the context, it calls the
scrape_shoesfunction with a Playwright instance and a Nike webpage URL.
Run the code to see the output as shown below:
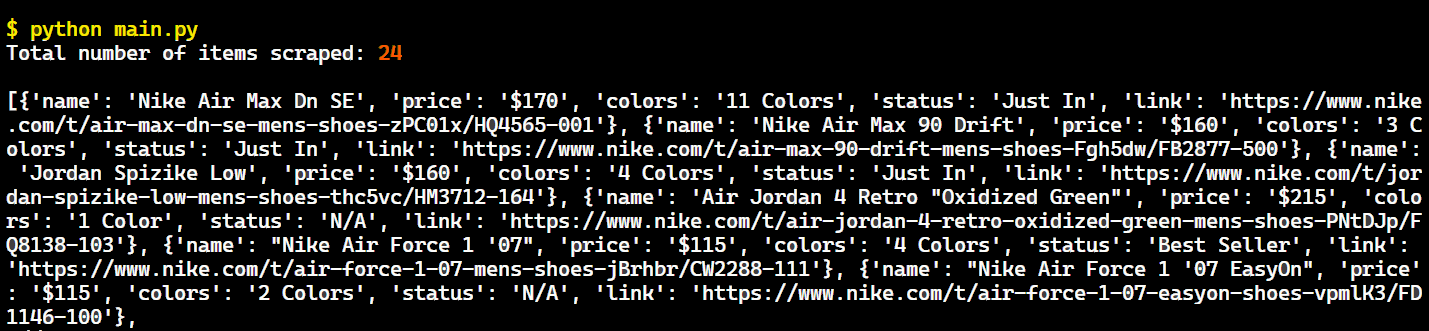
Great! Our scraper is working correctly and has extracted shoe data from the Nike website.
However, we've currently only managed to scrape 24 items. Nike's "Mens Lifestyle Shoes" category lists approximately 400 shoes at the time of writing this article and It seems that these 24 items are from the first page. Our goal isn't limited to a single page.
Now, let's see how to use Playwright to scrape all website pages.
Handling Dynamic Content Loading
As you scroll down the page, you'll observe that additional shoes are continuously loaded. This is an example of the concept of infinite scrolling. During this process, the website initiates more AJAX requests to fetch additional data as you scroll downwards.
So, let’s take a look at how to extract all product data from this dynamically loading content.
Web pages that use infinite scrolling automatically load more content as the user scrolls down. Therefore, our scraping script must ensure all products are loaded by navigating to the bottom of the page. This can be achieved by executing JavaScript code to command the browser to scroll downwards.
When you run the code snippet below:
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
Playwright successfully scrolls to the bottom of the page. However, since new content loads dynamically, you need to scroll multiple times to reach the actual bottom.
To address this, let's create a dedicated helper function named scroll_to_bottom. This function will repeatedly scroll the page until no new content appears, ensuring you've reached the page's end.
# ...
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height of the page
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
# Scroll to the bottom of the page
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
# Wait for the page to load additional content
await asyncio.sleep(1)
# Get the new scroll height and compare it with the last height
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break # Exit the loop if the bottom of the page is reached
last_height = new_height
iteration += 1
# ...
When the scroll_to_bottom function runs, the browser will scroll down the page multiple times. As a result, the page should now be fully loaded with all the data we need.
Here’s the complete code:
import asyncio
from playwright.async_api import Playwright, async_playwright, Page
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height of the page
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
# Scroll to the bottom of the page
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
# Wait for the page to load additional content
await asyncio.sleep(1)
# Get the new scroll height and compare it with the last height
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break # Exit the loop if the bottom of the page is reached
last_height = new_height
iteration += 1
async def scrape_shoes(playwright: Playwright, url: str) -> None:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
await page.goto(url)
# Scrolling to the bottom of the page...
await scroll_to_bottom(page)
shoes_list = []
shoe_containers = await page.query_selector_all(".product-card")
for shoe in shoe_containers:
shoe_name = await shoe.query_selector(".product-card__title")
shoe_name = await shoe_name.text_content() if shoe_name else "N/A"
shoe_price = await shoe.query_selector(".product-price")
shoe_price = await shoe_price.text_content() if shoe_price else "N/A"
shoe_colors = await shoe.query_selector(".product-card__product-count")
shoe_colors = await shoe_colors.text_content() if shoe_colors else "N/A"
shoe_status = await shoe.query_selector(".product-card__messaging")
shoe_status = await shoe_status.text_content() if shoe_status else "N/A"
shoe_link = await shoe.query_selector(".product-card__link-overlay")
shoe_link = await shoe_link.get_attribute("href") if shoe_link else "N/A"
shoe_info = {
"name": shoe_name,
"price": shoe_price,
"colors": shoe_colors,
"status": shoe_status,
"link": shoe_link,
}
shoes_list.append(shoe_info)
print(f"Total number of shoes scraped: {len(shoes_list)}")
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_shoes(
playwright=playwright,
url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
)
if __name__ == "__main__":
asyncio.run(main())
Run the code and the output will be:
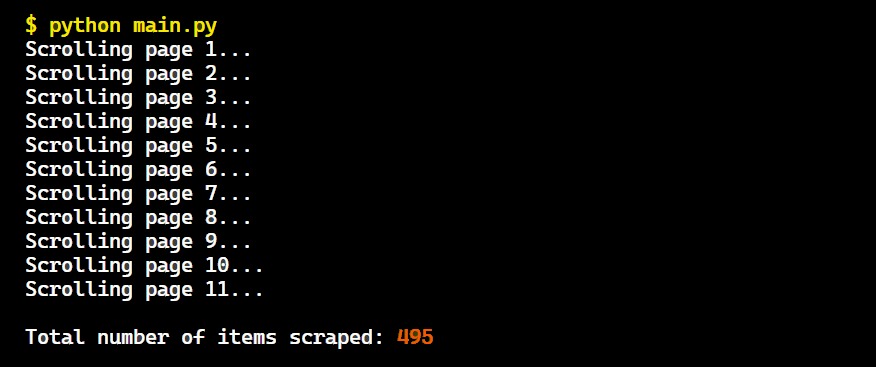
Great! We successfully scrolled through the pages and extracted all the shoe data.
Playwright Network Events
Each time you scroll down, the browser sends multiple HTTP requests to load new data, which is then rendered on the page. To extract this data more efficiently, you can intercept these network requests directly instead of parsing the updated HTML.
To pinpoint the exact request, open the browser's developer tools and go to the ‘Network’ tab. Scroll through the page to trigger the data-loading requests. In the network activity, look for requests with the parameter “queryid=products”, as these are the most relevant.
Navigate to the 'Response' section within these requests to see the precise data we need.
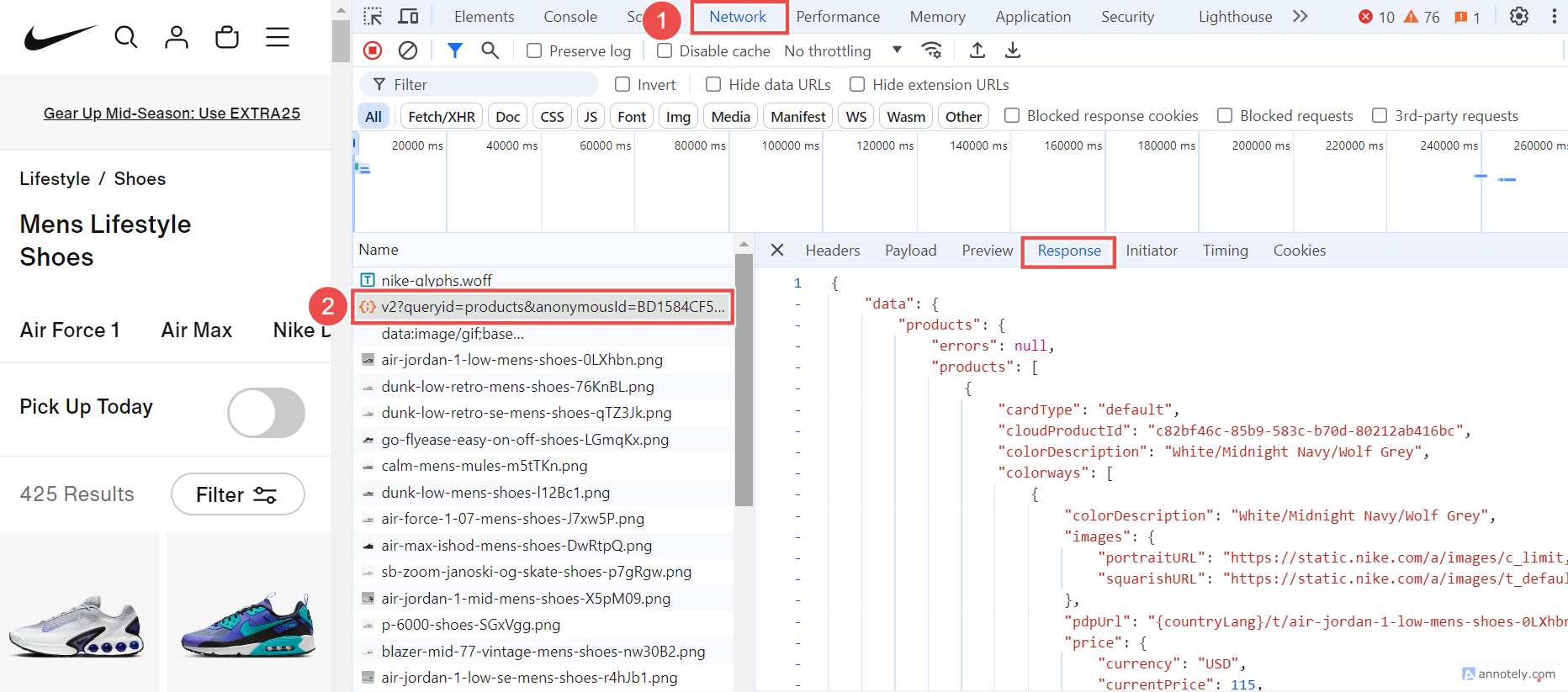
We'll now modify our script to analyze these specific requests each time they're made. By intercepting and examining the network requests and responses, we can capture the data directly from the server's responses. To achieve this, we'll use Playwright's network events feature, which lets us listen to and respond to network activities.
Right after initiating a new browser page with the browser.new_page(), we'll set up network event monitoring. This will allow us to capture the necessary requests and extract the desired data directly from these network interactions.
# ...
page.on(event="response", f=lambda response: extract_product_data(response))
# ...
The above code snippet sets up an event listener on the page to listen for HTTP response events. Whenever a response is received, the extract_product_data function is called with the response object as its argument. This function is responsible for extracting data from the HTTP responses that the page receives during its interaction with a website.
Let's create the extract_product_data function to identify and extract relevant data from network responses. This function will use the standard library urllib to parse each response's URL and check if it contains the query parameter "queryid=products".
If the query is found, it shows that the response contains the data of interest. We will then convert the response content to JSON format using the response.json() method for review and further processing.
# ...
from urllib.parse import parse_qs, urlparse
async def extract_product_data(response: Response) -> None:
# Parse the URL and extract query parameters
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if "queryid=products" is in the URL
if "queryid" in query_params and query_params["queryid"][0] == "products":
data = await response.json()
print("JSON data found in:", response.url)
print("Data:", data)
# ...
Once the extract_product_data function is executed, the JSON data will be printed to the console as shown below:
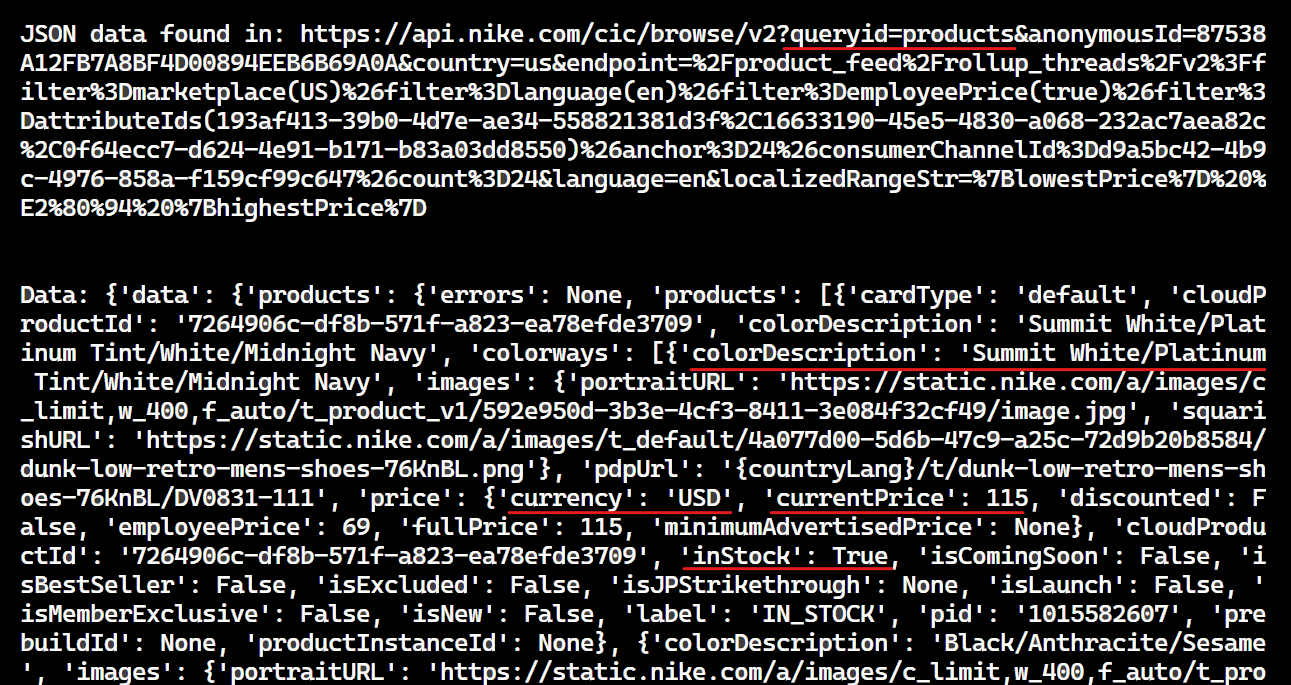
Now, carefully examine this data to identify the data you need. Then, modify the extract_product_data function accordingly to extract the desired data.
Here’s the modified version of the extract_product_data function:
# ...
from contextlib import suppress
def extract_product_data(response: Response, extracted_products: list) -> None:
# Parse the URL and extract query parameters
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if the URL contains 'queryid=products'
if "queryid" in query_params and query_params["queryid"][0] == "products":
# Get the JSON response
data = await response.json()
# Use suppress to handle potential KeyError exceptions
with suppress(KeyError):
# Iterate through the products and extract details
for product in data["data"]["products"]["products"]:
product_details = {
"colorDescription": product["colorDescription"],
"currency": product["price"]["currency"],
"currentPrice": product["price"]["currentPrice"],
"fullPrice": product["price"]["fullPrice"],
"inStock": product["inStock"],
"title": product["title"],
"subtitle": product["subtitle"],
"url": product["url"].replace(
"{countryLang}", "https://www.nike.com/en"
),
}
# ...
The code iterates through a list of products to extract specific details, such as color description, currency, current and full prices, and title. By using suppress(KeyError), the code ensures that if any keys are not found, the KeyError is suppressed (i.e., ignored), allowing the program to continue running.
Here’s the complete code:
import asyncio
import json
from contextlib import suppress
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Page, Playwright, Response, async_playwright
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height of the page
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
# Scroll to the bottom of the page
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
# Wait for the page to load additional content
await asyncio.sleep(1)
# Get the new scroll height and compare it with the last height
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break # Exit the loop if the bottom of the page is reached
last_height = new_height
iteration += 1
async def extract_product_data(response: Response, extracted_products: list) -> None:
# Parse the URL and extract query parameters
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if the URL contains 'queryid=products'
if "queryid" in query_params and query_params["queryid"][0] == "products":
# Get the JSON response
data = await response.json()
# Use suppress to handle potential KeyError exceptions
with suppress(KeyError):
# Iterate through the products and extract details
for product in data["data"]["products"]["products"]:
product_details = {
"colorDescription": product["colorDescription"],
"currency": product["price"]["currency"],
"currentPrice": product["price"]["currentPrice"],
"fullPrice": product["price"]["fullPrice"],
"inStock": product["inStock"],
"title": product["title"],
"subtitle": product["subtitle"],
"url": product["url"].replace(
"{countryLang}", "https://www.nike.com/en"
),
}
extracted_products.append(product_details)
async def scrape_shoes(playwright: Playwright, target_url: str) -> None:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
extracted_products = []
# Set up a response event handler to extract the product data
page.on(
"response", lambda response: extract_product_data(
response, extracted_products)
)
# Navigate to the target URL
await page.goto(target_url)
await asyncio.sleep(2)
# Scroll to the bottom of the page to load all products
await scroll_to_bottom(page)
# Save the extracted data to a JSON file
with open("extracted_products.json", "w") as file:
json.dump(extracted_products, file, indent=4)
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_shoes(
playwright=playwright,
target_url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
)
if __name__ == "__main__":
asyncio.run(main())
Run the code, and you'll see that a file named extracted_products.json will be created.
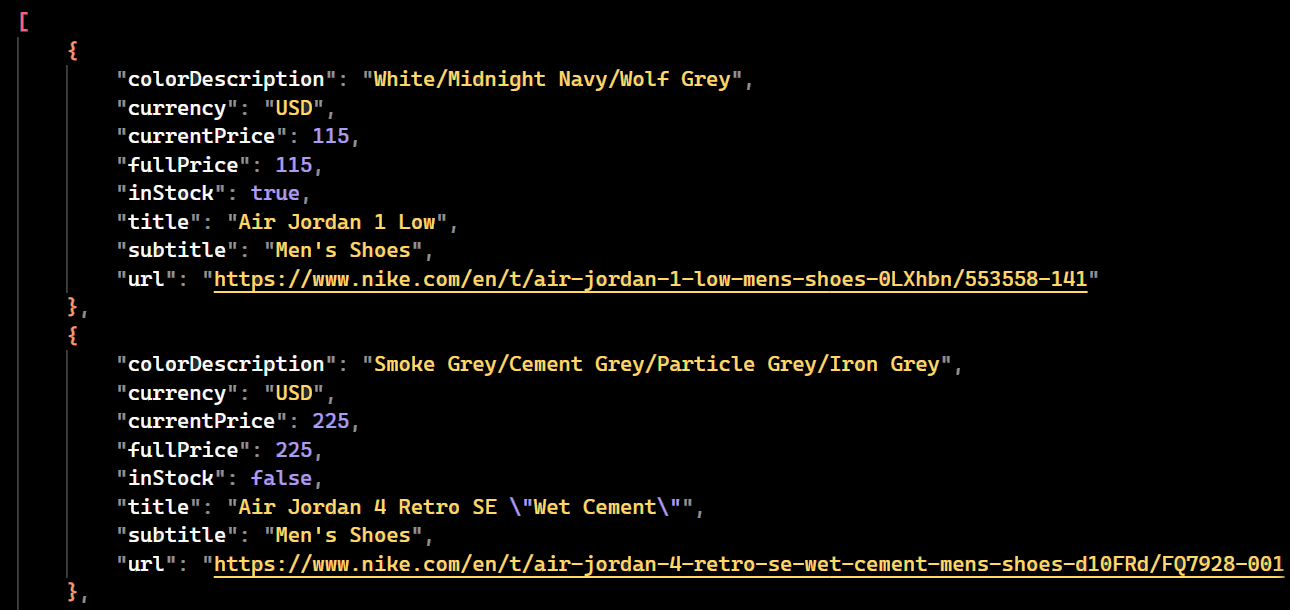
Blocking Images and Resources
When using Playwright, Selenium, or any other automated browser, performance issues are common. By default, browsers render all content on the page, which consumes both resources and time. To mitigate these issues, it's often necessary to implement strategies to control or limit rendering and loading.
Playwright allows you to control content loading by blocking specific resource types such as images, stylesheets, and fonts. Blocking resources with Playwright can significantly reduce bandwidth usage and speed up your web scraper, ultimately increasing the number of pages scraped per minute.
Go to the “Network” tab again and start scrolling the page. You will see multiple requests being made. Out of these requests, we only need the ones that contain queryid=products in the URL; the others are not useful for our purposes, as shown in the image below.
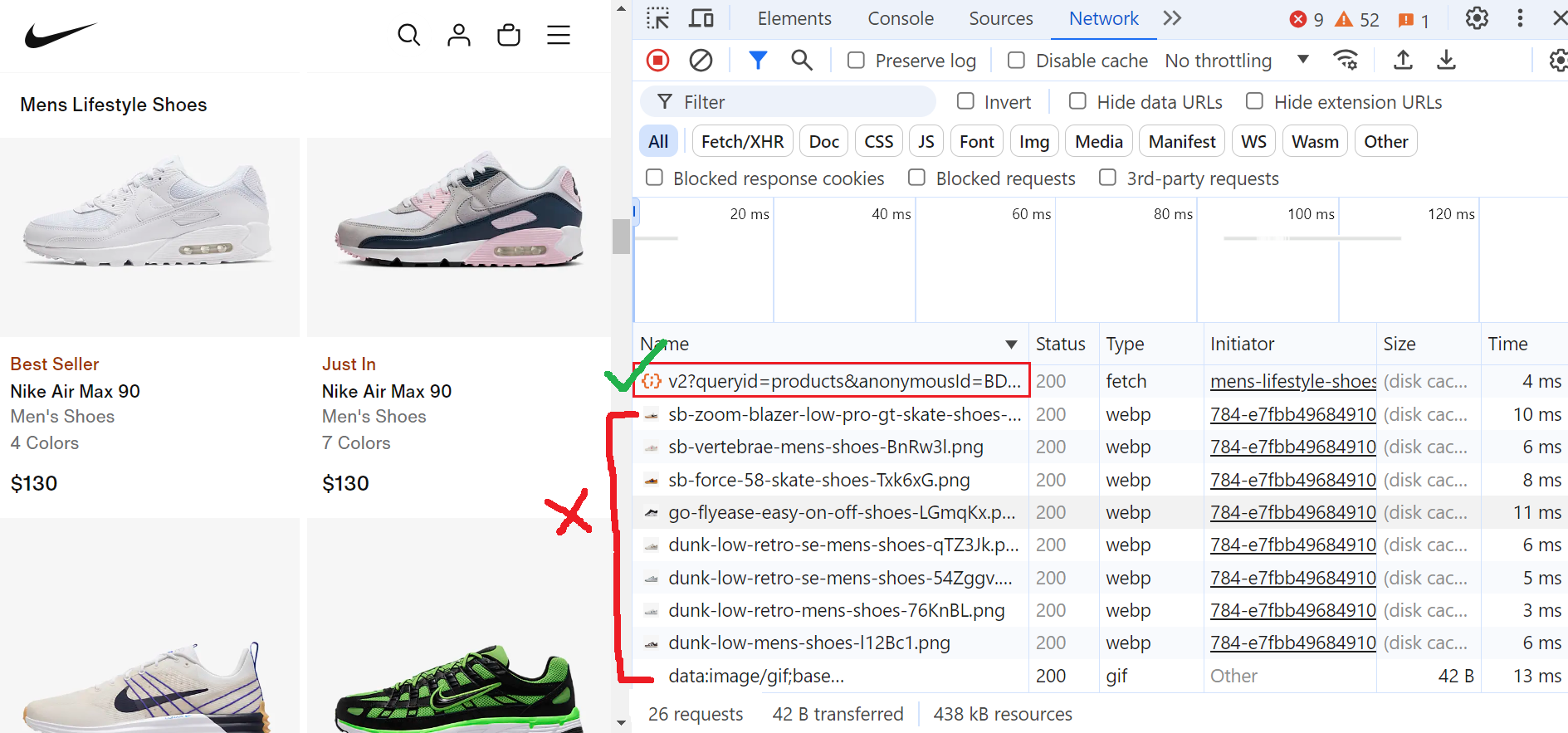
You can block resources in Playwright using the page.route() method.
Now, let's create a route_handler function to selectively block certain types of resources from loading when navigating a webpage.
# ...
def route_handler(route):
resource_type = route.request.resource_type()
# Block specific resource types
if resource_type in ("image", "stylesheet", "font", "xhr"):
route.abort() # Abort the request to block the resource
else:
route.continue_() # Allow other resources to load
page.route("**/*", route_handler) # Intercept all resource types
# ...
In the above code, the route_handler function is called for every page request to determine whether to block or allow it. The function takes a route object as input. It then checks the type of resource being requested using resource_type(). If it's an "image," "stylesheet," "font," or "xhr," the request is aborted using route.abort(). Otherwise, the request proceeds with route.continue_().
Here’s the complete code:
import asyncio
import json
from contextlib import suppress
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Page, Playwright, Response, async_playwright
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height of the page
last_height = await page.evaluate("document.body.scrollHeight")
iteration = 1
while True:
print(f"Scrolling page {iteration}...")
# Scroll to the bottom of the page
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
# Wait for the page to load additional content
await asyncio.sleep(1)
# Get the new scroll height and compare it with the last height
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
break # Exit the loop if the bottom of the page is reached
last_height = new_height
iteration += 1
async def block_resources(page: Page) -> None:
async def intercept_route(route, request):
if request.resource_type in ["image", "stylesheet", "font", "xhr"]:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept_route)
async def extract_product_data(response: Response, extracted_products: list) -> None:
# Parse the URL and extract query parameters
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if the URL contains 'queryid=products'
if "queryid" in query_params and query_params["queryid"][0] == "products":
# Get the JSON response
data = await response.json()
# Use suppress to handle potential KeyError exceptions
with suppress(KeyError):
# Iterate through the products and extract details
for product in data["data"]["products"]["products"]:
product_details = {
"colorDescription": product["colorDescription"],
"currency": product["price"]["currency"],
"currentPrice": product["price"]["currentPrice"],
"fullPrice": product["price"]["fullPrice"],
"inStock": product["inStock"],
"title": product["title"],
"subtitle": product["subtitle"],
"url": product["url"].replace(
"{countryLang}", "https://www.nike.com/en"
),
}
extracted_products.append(product_details)
async def scrape_shoes(playwright: Playwright, target_url: str) -> None:
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page(viewport={"width": 1600, "height": 900})
# Block unnecessary resources
await block_resources(page)
extracted_products = []
# Set up a response event handler to extract the product data
page.on(
"response", lambda response: extract_product_data(response, extracted_products)
)
# Navigate to the target URL
await page.goto(target_url)
await asyncio.sleep(2)
# Scroll to the bottom of the page to load all products
await scroll_to_bottom(page)
# Save the extracted data to a JSON file
with open("extracted_products.json", "w") as file:
json.dump(extracted_products, file, indent=4)
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_shoes(
playwright=playwright,
target_url="https://www.nike.com/w/mens-lifestyle-shoes-13jrmznik1zy7ok",
)
if __name__ == "__main__":
asyncio.run(main())
Run the code, and you will notice that the specified resources will be blocked, as shown in the image below:
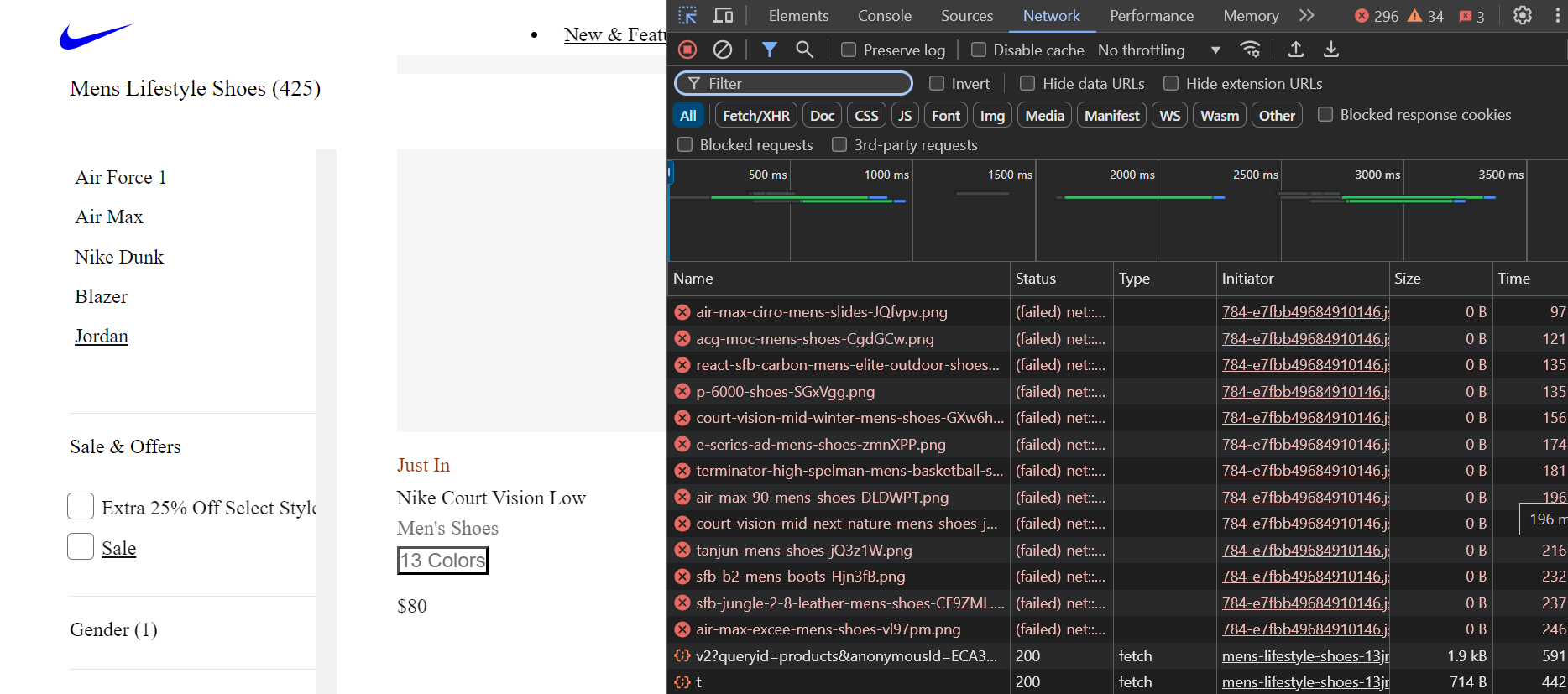
Great! We saved a lot of time and bandwidth.
Next Steps
We hope you now understand how to use Playwright to build a scraper that can easily extract data from websites, even those that heavily rely on JavaScript to render their content. We demonstrated scraping the Nike website, which generates content dynamically as you scroll down the page.
In Part 3 of this series, we'll focus on storing our data. We'll explore storing data in JSON files, databases, and AWS S3 buckets.