

This article will expose how to block specific resources (HTTP requests, CSS, video, images) from loading in Playwright. Playwright is Puppeteer's successor with the ability to control Chromium, Firefox, and Webkit. So I'd call it the second one of the most widely used web scraping and automation tools with headless browser support.
Why block resources
Block resources from loading while web scraping is a widespread technique that allows you to save time and costs.
For example, when you crawl a resource for product information (scrape price, product name, image URL, etc.), you don't need to load external fonts, CSS, videos, and images themselves. However, you'll need to extract text information and direct URLs for media content for most cases.
Also, such improvements will:
- speed up your web scraper
- increase number of pages scraped per minute (you'll pay less for your servers and will be able to get more information for the same infrastructure price)
- decrease proxy bills (you won't use proxy for irrelevant content download)
Intercept requests with Playwright
Request interception
Since Playwright is a Puppeteer's successor with a similar API, it can be very native to try out using the exact request interception mechanism. Also, from the documentation for both libraries, we can find out the possibility of accessing the page's requests.
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
page.on('request', (request) => {
console.log(`Request: ${request.url()} to resource type: ${request.resourceType()}`);
});
await page.goto('https://amazon.com');
await browser.close();
})();
So, the output will provide information about the requested resource and its type.
Request: https://amazon.com/ to resource type: document
Request: https://www.amazon.com/ to resource type: document
......
Request: https://m.media-amazon.com/images/I/41Kf0mndKyL._AC_SY200_.jpg to resource type: image
Request: https://m.media-amazon.com/images/I/41ffko0T3kL._AC_SY200_.jpg to resource type: image
Request: https://m.media-amazon.com/images/I/51G8LfsNZzL._AC_SY200_.jpg to resource type: image
Request: https://m.media-amazon.com/images/I/41yavwjp-8L._AC_SY200_.jpg to resource type: image
......
Request: https://m.media-amazon.com/images/S/sash/2SazJx$EeTHfhMN.woff2 to resource type: font
Request: https://m.media-amazon.com/images/S/sash/ozb5-CLHQWI6Soc.woff2 to resource type: font
Request: https://m.media-amazon.com/images/S/sash/KwhNPG8Jz-Vz2X7.woff2 to resource type: font
Still, according to Playwright's documentation, the Request callback object is immutable, so you won't be able to manipulate the request using this callback.
Let's check out the Playwright's suggestion about this situation:
/**
* Emitted when a page issues a request. The [request] object is read-only. In order to intercept and mutate requests, see
* [page.route(url, handler)](https://playwright.dev/docs/api/class-page#pagerouteurl-handler) or
* [browserContext.route(url, handler)](https://playwright.dev/docs/api/class-browsercontext#browsercontextrouteurl-handler).
*/
on(event: 'request', listener: (request: Request) => void): this;
Cool. Let's use page.route for the request manipulations.
Route interception
The concept behind using page.route interception is very similar to Puppeteer's page.on('request'), but requires indirect access to Request object using route.request.
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.route('**/*', (route) => {
return route.request().resourceType() === 'image'
? route.abort()
: route.continue()
});
await page.goto('https://amazon.com');
await page.screenshot({ path: 'amazon_no_images.png' });
await browser.close();
})();
So, we're using intercepting routes and then indirectly accessing the requests behind these routes.
As a result, you will see the website images not being loaded.
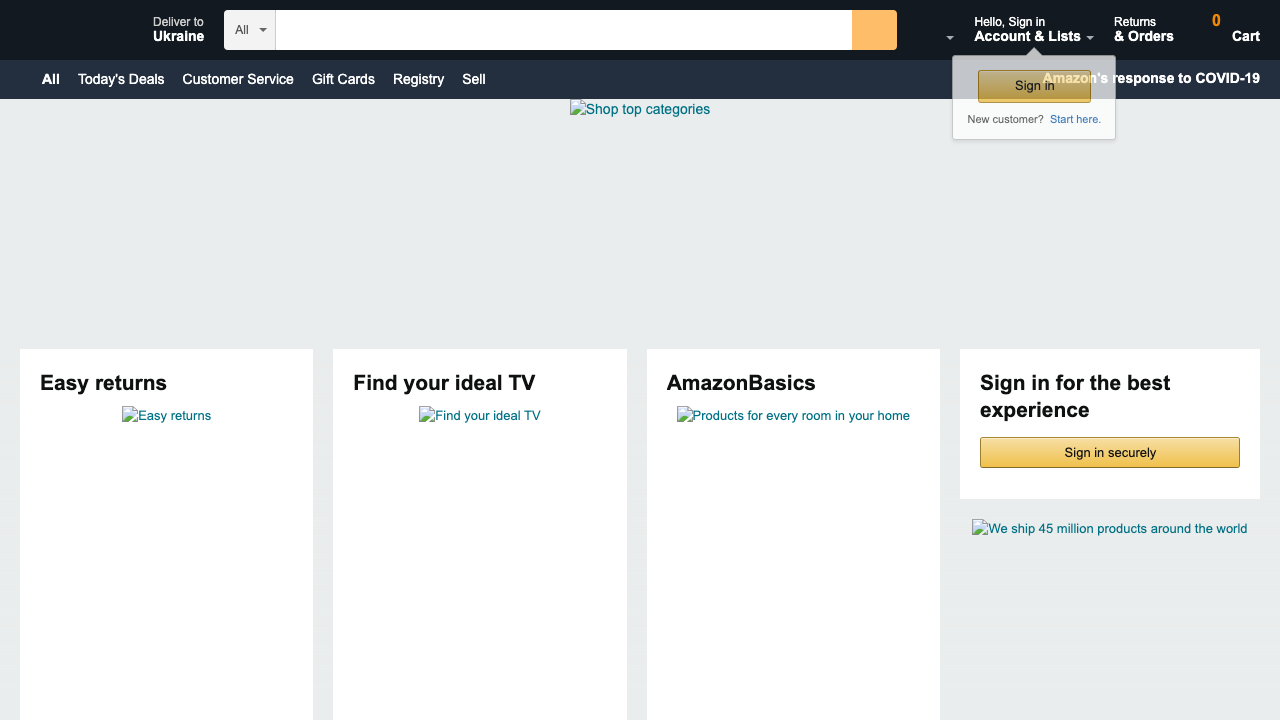
All the supported resource types can be found below:
- stylesheet
- image
- media
- font
- script
- texttrack
- xhr
- fetch
- eventsource
- websocket
- manifest
- other
Also, you can apply any other condition for request prevention, like the resource URL:
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.route('**/*', (route) => {
return route.request().url().endsWith('.jpg')
? route.abort()
: route.continue()
});
await page.goto('https://amazon.com');
await page.screenshot({ path: 'amazon_no_jpg_images.png' });
await browser.close();
})();
Improve SPA page scraping speed (Vue.js, React.js, etc.)
Since the start of my web scraping journey, I've found pretty neat the following exclusion list that improves Single-Page Application scrapers and decreases scraping time up to 10x times:
const playwright = require('playwright');
const RESOURCE_EXCLUSTIONS = ['image', 'stylesheet', 'media', 'font','other'];
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.route('**/*', (route) => {
return RESOURCE_EXCLUSTIONS.includes(route.request().resourceType())
? route.abort()
: route.continue()
});
await page.goto('https://amazon.com');
await browser.close();
})();
Such code snippet prevents binary and media content loading while providing all required dynamic web page load.
Summary
Request interception is a basic web scraping technique that allows improving crawler performance and saving money while doing data extraction at scale.
To save more money, you can check out the web scraping API concept. It already handles headless browser and proxies for you, so you'll forget about giant bills for servers and proxies.
Also, those articles might be interesting for you:
- Web Scraping with Javascript (NodeJS) - to learn more about web scraping with Javascript
- How to download a file with Playwright? - downloading files with Playwright (Javascript)
- How to submit a form with Playwright? - submitting forms with Playwright (Javascript)
Happy Web Scraping, and don't forget to enable caching in your headless browser 💾