
In this article, we'll take a look at how to submit forms using Playwright. This knowledge might be beneficial while scraping the web, as it allows to get the information from the target web page, which requires providing parameters before.
Looking for a Puppeteer guide? Check out: How to submit a form with Puppeteer?
We're going to check out several different topics about the form submission:
- how to fill an input and click a button using Playwright API
- how to upload a file to a file input using Playwright API
- hot to fill an input and click a button using an internal Javascript execution
Automating form submission
Let's start with automating Google search using Playwright.
By visiting Google.com and revealing HTML sources, we may observe required selectors for both the search input field and the search button.
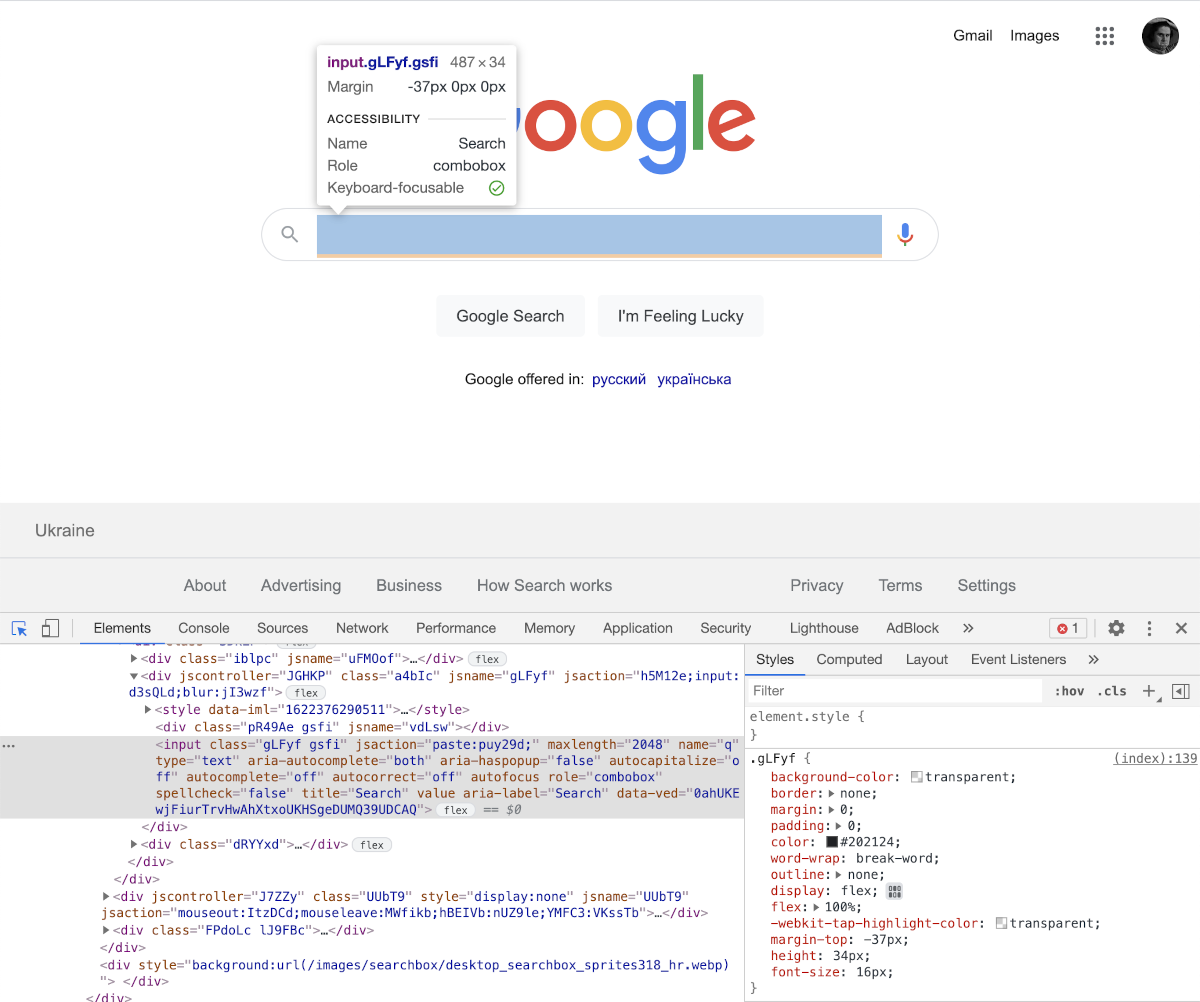
The text input has the name attribute q, while the form submission button has the name btnK.
To make such an inspection, open the browser's Dev Tools and inspect the form. To know more about Developer Tools inspection, check out our web scraping guide.
Those selectors will help us get control over the input and button elements, so we'll automate Google search.
Let's find something in Google. Like ScrapingAnt is awesome 😀
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://google.com');
await page.type('input[name=q]', 'ScrapingAnt is awesome');
await page.click('input[name=btnK]:visible');
await page.waitForTimeout(5000);
await page.screenshot({ path: 'scrapingant.png' });
await browser.close();
})();
And the result is the expected one:
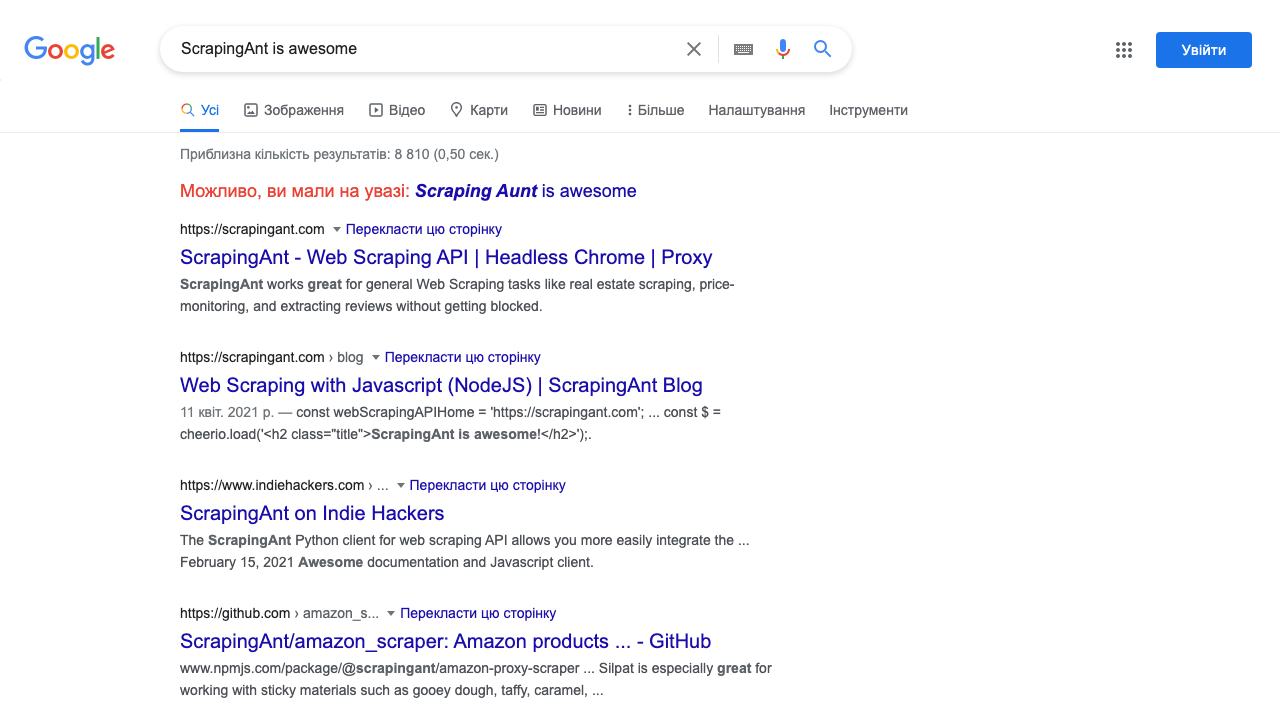
The exact input fill was implemented using page.type method with a proper CSS selector.
The more exciting part of this form submission is related to form click. While the Google.com page has several buttons with this name, we have to pick the button capable of being clicked. To select it, we've used a CSS pseudo-selector :visible.
Submitting a form with attachments
Sometimes web scraper or browser automation tool may require submitting a file as a part of the form submission.
Let's take a look at how we can upload a file using Playwright. We will use this demo form from W3 school to demonstrate file attachments in the scope of the HTML forms.
We will upload a previous screenshot we've made using Playwright and will create a new one:
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.w3schools.com/howto/howto_html_file_upload_button.asp');
await page.setInputFiles('input[type=file]', 'scrapingant.png');
await page.screenshot({ path: 'scrapingant.png' });
await browser.close();
})();
As a result, we may observe a prepared file to be sent using the HTML form.
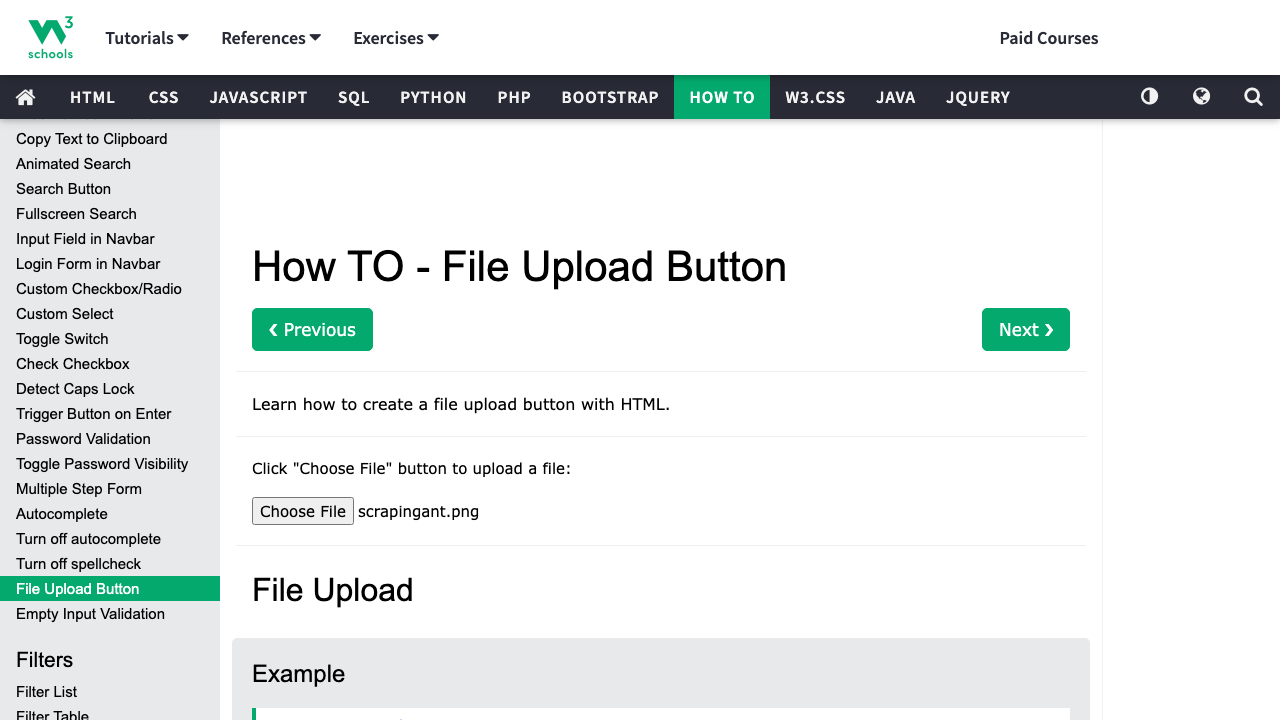
Playwright's API is capable to upload files to the inputs using page.setInputFiles method.
It makes it possible to use a file from the filesystem, several files, remove a file from the input and even use a buffer to pass the data into the file input.
Submitting a form using Javascript
Sometimes you might not be able to access a Playwright API (or any other API like Puppeteer's one), but you'll be able to execute a Javascript snippet in the context of the scraped page. For example, ScrapingAnt web scraping API provides such ability without dealing with the browser controller itself.
So, luckily, it also possible to fill a form using the Javascript code inside the page. Let's rewrite a Google Search sample using it:
const playwright = require('playwright');
(async () => {
const browser = await playwright['chromium'].launch();
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://google.com');
await page.evaluate(() => {
document.querySelector('input[name=q]').value = 'ScrapingAnt is awesome';
document.querySelector('input[name=btnK]:not([hidden])').click();
});
await page.waitForTimeout(5000);
await page.screenshot({ path: 'scrapingant.png' })
await browser.close();
})();
The mentioned code doesn't use Playwright API to fill inputs or click a button. Instead, it uses an internal page context to grab the DOM element using a query selector (document.querySelector) and manipulate it.
Also, you might observe that the pseudo-selector :visible has been replaced by :not([hidden]), which is supported and can be used in such case (:visible is not).
Conclusion
As you can see, there are a lot of possible ways to fill a form using Playwright. Some of them require basic knowledge of Playwright's API, while the other - not, which makes it possible to use the same form submitting code across the Playwright, Puppeteer, or the web scraping API.
I'm highly recommending to check out the following resources to know more about the Playwright and form submission:
- Web browser automation with Python and Playwright
- How to use a proxy in Playwright
- How to download a file with Playwright?
- Playwright Input API
- Document.querySelector() documentation
Happy Web Scraping, and don't forget to wait for the selector before the data extraction start 🕒