

In Part 3, we focused on analyzing and cleaning the extracted data to address potential issues like missing values, inconsistencies, and outliers. To make it easier for future decision-making, we saved the cleaned data in various formats, such as CSV, databases, and S3 buckets.
In Part 4, we'll delve into strategies for bypassing common web scraping hurdles. We'll explore techniques such as using proxies, rotating user agents, and leveraging web scraping APIs to keep your scraping tasks running smoothly.
Without further ado, let’s get started!
Blocks and Bans: Common Web Scraping Hurdles
When you start scraping data at scale, you quickly realize that building and running the scrapers themselves is actually the easy part. The real challenge is consistently getting reliable HTML responses from the target pages. See, once you start scaling up to thousands or even millions of requests, the websites you're scraping are going to start blocking your access. Major sites like Amazon actively monitor visitors by tracking IP addresses and user agents and have all sorts of sophisticated anti-bot measures in place. If you identify as a scraper, your request will be blocked.
However, there are techniques to get around these anti-bot protections. While these techniques may not be needed for our project on scraping Nike, it's useful to understand how to apply these techniques if you ever need to scrape a website with advanced anti-bot measures.
Let’s dive in!
Techniques to Avoid Bot Detection with Playwright
Here are some techniques you can use to evade bot detection using Python with Playwright.
Use Proxies
Proxies act as an intermediary between you and your target website, reducing the risk of getting blocked. Implementing a proxy in Playwright is straightforward.
Here's how to set up a proxy in Playwright:
Start by defining an asynchronous function. Launch a new browser instance and pass your proxy details as parameters. For this example, we’ll use a free proxy from FreeProxyList.
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(
proxy={"server": "170.247.222.44:8080"}
)
Within the browser, create a new context and open a page:
context = await browser.new_context()
page = await context.new_page()
Navigate to your target website, scrape the required data, and then close the browser. In this example, we scrape the IP address from HTTPBin:
await page.goto("https://httpbin.org/ip")
ip_add = await page.text_content("body")
print(ip_add)
await context.close()
await browser.close()
asyncio.run(main())
Combining everything, your complete script will look like this:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(
proxy={
"server": "170.247.222.44:8080",
},
)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://httpbin.org/ip")
ip_add = await page.text_content("body")
print(ip_add)
await context.close()
await browser.close()
asyncio.run(main())
The output will display:

The output confirms that your requests are being routed through the proxy. You’ve now successfully set up a Playwright proxy!
Proxy providers offering premium proxies require authentication to access their servers. You can easily pass your credentials in the launch() method. Here’s how:
browser = await playwright.chromium.launch(
proxy={
"server": "<PROXY_IP_ADDRESS>:<PROXY_PORT>",
"username": "<YOUR_USERNAME>",
"password": "<YOUR_PASSWORD>",
}
)
Now, let’s incorporate this into a complete Playwright script:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(
proxy={
"server": "<PROXY_IP_ADDRESS>:<PROXY_PORT>",
"username": "<YOUR_USERNAME>",
"password": "<YOUR_PASSWORD>",
}
)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://httpbin.org/ip")
ip_add = await page.text_content("body")
print(ip_add)
await context.close()
await browser.close()
asyncio.run(main())
Websites can detect and block requests from specific IP addresses. To avoid this, you can rotate proxies between requests. Let’s set up a proxy pool and choose a random proxy for each request.
from playwright.async_api import async_playwright
import asyncio
import random
proxy_pool = [
{"server": "156.255.25.149:8080"},
{"server": "45.139.59.216:8080"},
{"server": "143.137.165.150:8080"},
{"server": "154.92.120.99:8080"},
{"server": "185.161.254.156:8080"},
]
async def main():
for _ in range(5): # Making 5 requests here...
proxy = random.choice(proxy_pool)
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(proxy=proxy)
context = await browser.new_context()
page = await context.new_page()
await page.goto("https://httpbin.org/ip")
ip_add = await page.text_content("body")
print(ip_add)
await context.close()
await browser.close()
asyncio.run(main())
Each time you run this code, you’ll see a different IP address in the output:
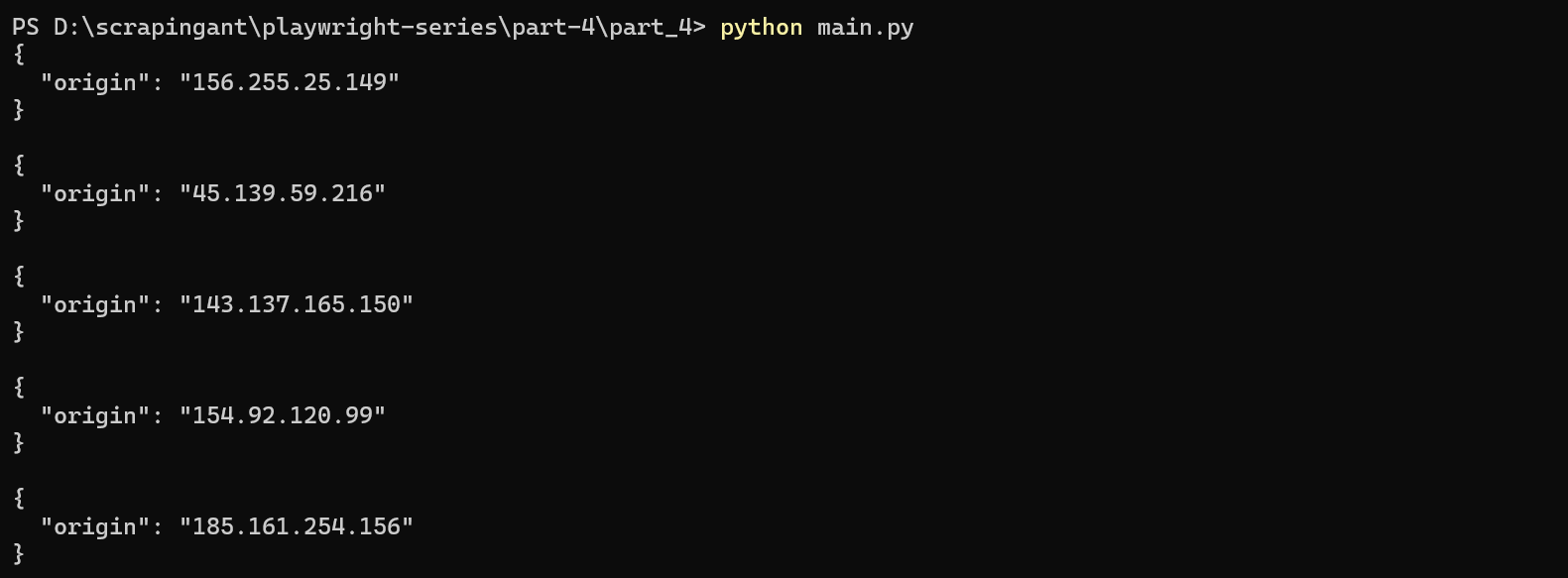
Nice! You’ve just built a simple proxy rotator in Playwright!
💡 Quick Tip: Free proxies are unreliable and often fail in practical use cases. We used them here just to demonstrate the basics.
Use a Custom User Agent
In web scraping, every HTTP request includes headers that provide details about both the request and the client making it. One crucial header is the User-Agent (UA), which can be used by websites to detect and block access if your request includes a Playwright's default UA. To avoid detection, you can set a custom User-Agent string for your Playwright instance.
Here’s how you can do it:
Start by specifying a User-Agent string that mimics a real browser:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36
Update your Playwright script to use this custom User-Agent string:
from playwright.async_api import async_playwright
import asyncio
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36"
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context(user_agent=user_agent)
page = await context.new_page()
await page.goto("https://httpbin.io/user-agent")
agent = await page.text_content("body")
print(agent)
await context.close()
await browser.close()
asyncio.run(main())
Running this script should display the custom User-Agent string in the output.

Great! You've successfully set up a custom Playwright User Agent.
If you use the same User Agent (UA) for multiple requests, it can be easily flagged as a bot by anti-bot systems. To avoid this, it's important to randomize the UA to make it appear as though the requests are coming from different users.
By rotating the Playwright User Agent randomly, you can mimic user behavior, making it more difficult for websites to detect and block your automated activities. To rotate the User-Agent, start by creating a list of UAs as shown below:
user_agent_strings = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko",
]
Remember to check that your User Agents (UAs) are compatible with the other headers and the browser you're emulating. For instance, if you set your UA to Google Chrome v118 on Windows but the other headers in the HTTP request indicate a Mac, the websites you're trying to access may detect this mismatch and block your requests.
Next, launch a browser instance and create a new context with a randomly selected user agent.
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context(
user_agent=random.choice(user_agent_strings)
)
Combining everything, your complete script will look like this:
from playwright.async_api import async_playwright
import asyncio
import random
user_agent_strings = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko",
]
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context(
user_agent=random.choice(user_agent_strings)
)
page = await context.new_page()
await page.goto("https://httpbin.io/user-agent")
ua = await page.text_content("body")
print(ua)
await context.close()
await browser.close()
asyncio.run(main())
Each time the script runs, a random User Agent is used.
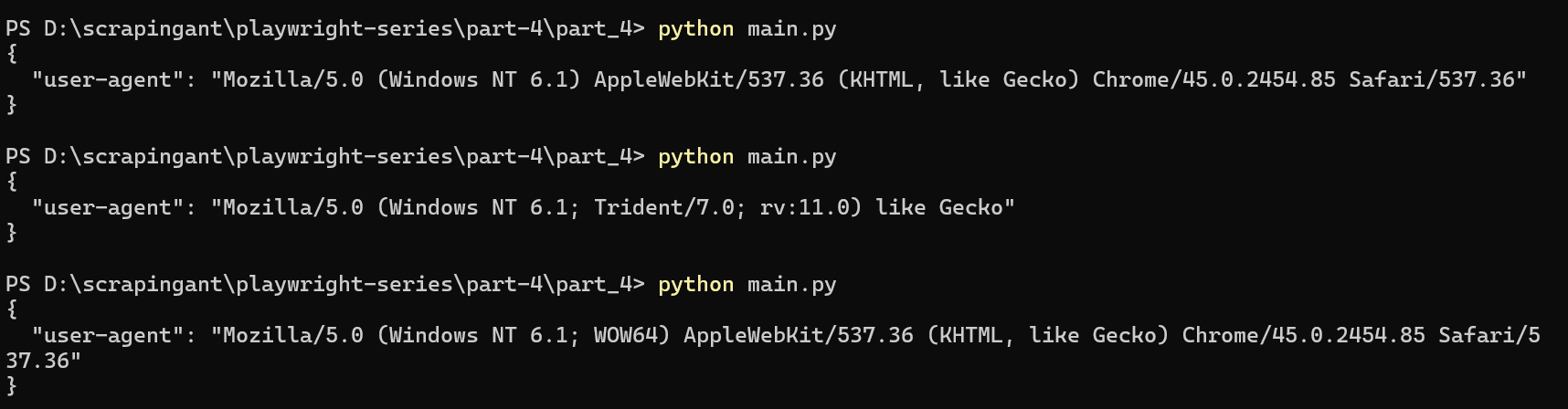
Nice! You've now successfully rotated your User Agent.
Disable WebDriver Automation Flags
When you're using automation tools like Playwright or Selenium, browsers often set specific flags that indicate the presence of automation. These flags make it easier for websites to detect that a bot is accessing the website, which can lead to blocks or restrictions. By disabling these flags, you can make your automated browser sessions look more like those of a real user.
One common flag is the navigator.webdriver property. This JavaScript property returns true if the browser is being controlled by automation. Fortunately, Playwright offers a way to disable webdriver flags and increase your chances of avoiding detection. You can use the add_init_script() function to set the navigator.webdriver property to undefined.
Add the following code in the init script to do that:
await context.add_init_script(
"Object.defineProperty(navigator, 'webdriver', { get: () => undefined })"
)
Here’s the modified Playwright web scraper:
from playwright.async_api import async_playwright
import asyncio
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
# Modify the navigator.webdriver property to prevent detection
await context.add_init_script(
"Object.defineProperty(navigator, 'webdriver', { get: () => undefined })"
)
page = await context.new_page()
await page.goto("https://example.com")
await context.close()
await browser.close()
asyncio.run(main())
Use the Playwright Stealth Plugin
The Playwright Stealth plugin modifies Playwright's default settings to help evade detection mechanisms that detect you as an automated browser. The Playwright Stealth plugin is based on the puppeteer-extra-plugin-stealth plugin, which applies various evasion techniques to make the detection of an automated browser harder.
The plugin's GitHub repository contains comparison test results that demonstrate how the base Playwright fails to evade detection mechanisms, whereas Playwright Stealth is more successful.
To get started with Playwright Stealth, you first need to install the plugin. Run the following command:
pip install playwright-stealth
Once installed, you can integrate Playwright Stealth into your Python script. Import the plugin along with Playwright:
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import stealth_async
Define an asynchronous function to create a new browser context and page
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
asyncio.run(main())
Lastly, apply the stealth plugin:
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
# Apply stealth to the page
await stealth_async(page)
asyncio.run(main())
Here's the full code:
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import stealth_async
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
# Apply stealth mode
await stealth_async(page)
await page.goto("https://example.com")
await context.close()
await browser.close()
# Run the main function
asyncio.run(main())
Playwright Stealth is a robust web scraping plugin, but it does have its limitations, as outlined in the official documentation. There are instances where it can still be detected, meaning it's not entirely reliable when attempting to bypass advanced anti-bot measures.
This leads to the question: what is the ultimate solution? Let's explore further.
Using a Web Scraping API
While traditional bypass methods can improve success rates, they are not foolproof, especially when dealing with advanced anti-bot systems. To reliably scrape any website, regardless of its anti-bot complexity, using a web scraping API like ScrapingAnt is highly effective. It automatically handles Chrome page rendering, low latency rotating proxies, and CAPTCHA avoidance, so you can focus on your scraping logic without worrying about getting blocked. To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you. Get started today with 10,000 free credits 🚀
Wrapping Up
In the 4-part series on Web Scraping with Playwright, we've covered the essentials of web scraping with Playwright—from setting up and building scrapers to cleaning data and tackling common hurdles. I hope you now have a good understanding of how to efficiently extract and use web data.
Also, make sure to check out ScrapingAnt's high-performance web scraping API, which is designed for reliable and large-scale data extraction.