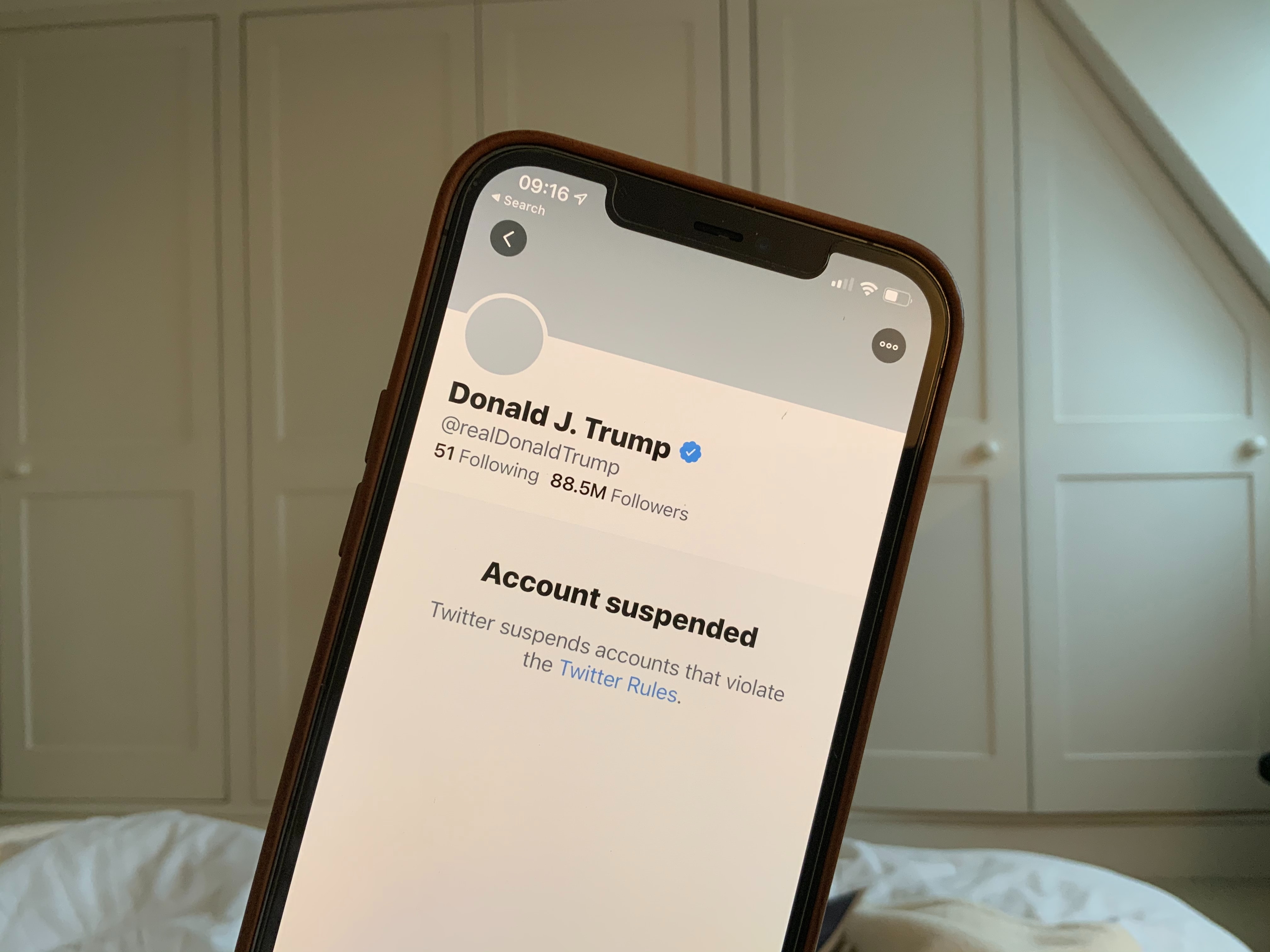
With the increasing use of the internet worldwide, it is being implemented in all aspects of our daily lives. So using it efficiently and effectively becomes crucial and could be the difference between competitors and businesses. This is where the concept of Web Automation comes in. Today I shall teach you one of the most debated topics of web automation, Puppeteer vs. Selenium.
Let's begin!