

As the amount of information on the internet is increasing exponentially, the use of data extraction methods is also on the rise. Web scraping is one of the most popular, reliable, and efficient means of data extraction. It is done both manually and using automated systems, with the automated method being the most popular and widely used.
Programming language is a must to implement automatic data extraction on web scrapers. So today, we shall discuss web scraping in R, as R is the best and most widely used language for data scraping. Now let’s begin understanding what web scraping is:
What is Web Scraping?
Web scraping is data extraction that automatically collects information and data from websites using scrapers. There are manual and automatic methods for this operation. However, the automated technique is more prevalent since it is substantially faster and more accurate.
Scrapers are programs that automatically extract and organize data according to the user's criteria.
Despite being such a fast and reliable means of data extraction, it’s sensitive, and its legality is a topic of much debate. Data and information are closely related to privacy, so it is often easy to break the rules and laws if one is not careful.
Now the question may arise, is web scraping legal or not? Let's answer that:
What is the Legality of Web Scraping?
Web scraping has always been a grey area with a fine line separating legal and illegal. While it is true that scraping and crawling are both legal on the whole, web scraping can sometimes be considered illegal in certain cases. It is not against the law to scrape websites to extract publicly available data as that information is free for everyone to use.
But web scraping can be illegal if it goes against a website's terms of service or if personal information is extracted and used without consent. To comply with the laws about data privacy, we should always follow and maintain web scraping best practices. Now let's look at R:
What is R? What is R in Web Scraping?
R is an open-source programming language created by Ross Ihaka and Robert Gentleman and developed by the R Development Core Team. It is mainly used for cataloging statistical computing and graphics.
Another use for R language is web scraping. It is free to use and is the number one choice for data analysts because of its functionality and data handling capabilities.
Some of its functions include
- Machine Learning Algorithms.
- Regression analysis.
- Statistical Inference.
- Data Handling and Storage.
- Operators like arrays, matrices, etc.
- Loops, cycles, etc.
R is used for data science because it offers various statistical libraries. Even companies like Google, Facebook, Twitter, etc., use R. It contains a lot of options for creating static graphics.
Web scraping in R requires you to understand two things:
HTML and CSS.
The first thing you must know involves HTML and CSS - terms with which you might be familiar. But let’s get a little deeper into those concepts here.
HTML
There is a common misconception that HTML is a programming language. But that’s wrong as it is a markup language, meaning it is more of a description of the content and structure of a webpage.
CSS
In short, CSS is used to style web pages. If you think of HTML as the structure and outline of the web page, the CSS part can be considered the webpage's details. For instance: the font, size, color of the text, etc.
Web Scraping Principles
The principles of web scraping are simple make-requests>extact data>store-extracted-data. And the best way to do that is to follow ethical web scraping and the best practices.
Understanding Webpages: CSS Selectors and HTML
HTML:
HTML or Hyper Text Markup Language is a web page's skeleton. To see any HTML code, simply go to any website and RIGHT click and select Inspect to see the HTML code. For instance:
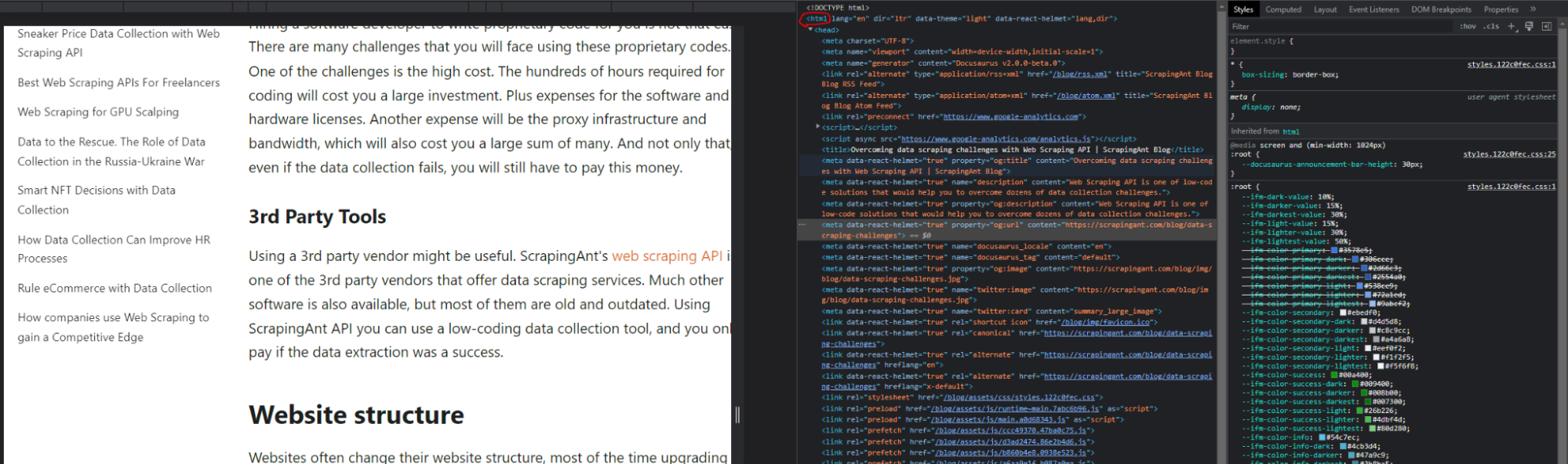
Here, you can easily spot the HTML code. The HTML code always begins with the tag <html> and ends with </html>.
CSS:
CSS can be added to HTML in three main ways:
External stylesheets.
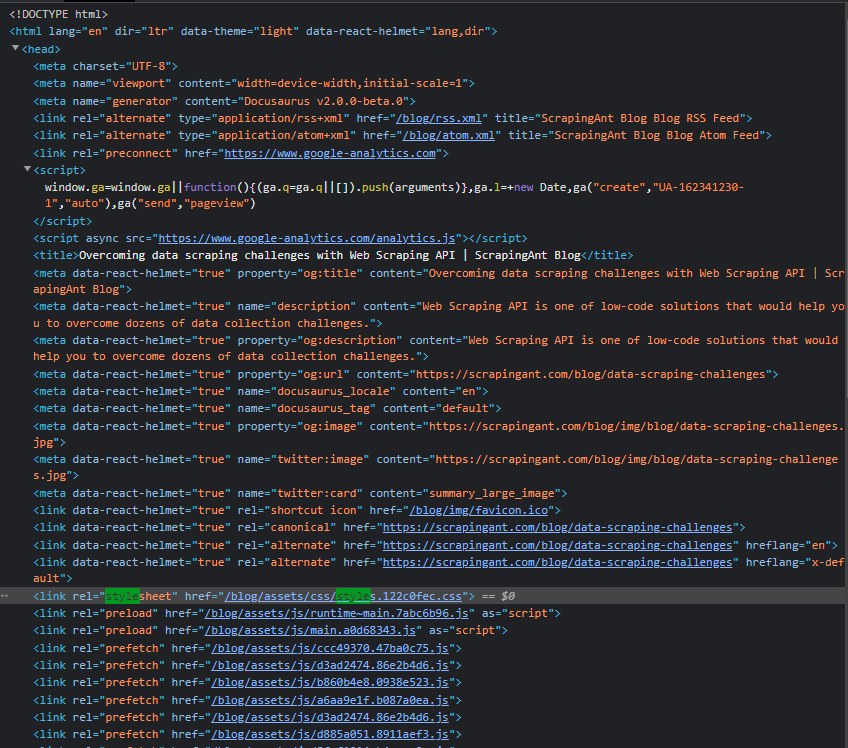
It can be written using any text editing software, including Notepad, but it needs to be saved under the .css type. That file contains the details.
Internal CSS
<html>
<head>
<style>
body{
background-color: coral;
}
h1{
Color: red;
margin-left: 60px;
}
</style>
</head>
<body>
<h1> This is just an example</h1>
</body>
</html>
This CSS style is used when a webpage has a unique or personalized style. It is always enclosed in between <style> and </style> tags.
Inline CSS
<html>
<body>
<h1 style=”color:red;text-align:left;”> This is just an example </h1>
</body>
</html>
This method is used to customise a single element on the webpage and differentiate it from other elements.
Here are some common CSS selectors:
| Selector | Instance | Output |
|---|---|---|
| * | * | Selects all elements |
| [attribute] | [age] | Selects all elements with age attribute |
| [attribute=value] | [age=50] | Selects all elements with age=50 attribute |
| [attribute~=value] | [color~=cyan] | Selects all elements with color attribute containing the word “cyan” |
| [attribute*=value] | a[href*=”voted”] | Selects all <a> elements whose href attribute contains the string “voted” |
| .class | .h1 | Selects all elements in the HTML file with the class “h1” |
| .class1.class2 | .postition1.position2 | Selects all elements that have both “position1” and “position2” in its class attribute |
| .class1 .class2 | .position1 .position2 | Selects all parent elements that contain position1 as the attribute and with children as position2 attribute |
| :default | jump:input | Selects the default <jump> element |
| element | div | Selects all <div> elements |
| element.class | div.title | Selects all <div> elements with class=“title” |
| element,element | div,p | Selects all <div> elements and all <p> elements |
| element1~element2 | end~paragraph | Selects all <paragraph> elements preceded by <end> element |
| element1+element2 | middlename+firstname | Selects all <middlename> elements that are placed immediately after <firstname> element |
| :focus | name:focus | Selects the name element which has focus |
Rvest and R
Rvest is a package developed for the R programming language that assists you in scraping or harvesting data from web pages. It is the go-to option when you are scraping large amounts of data. Hardley Wickham maintains it.
There is also a code of conduct for Rvest, which everyone must abide by. Now let’s take a look at how to install R.
Installing R and RStudio
To install R, simply visit the R project website and download the latest version. It is an open-source programming language and is free to use.
To install R studio IDE, simply visit their official website and download the version you think is best for you, as there are paid and free versions out there, with paid versions having more functions and features.
Adding Rvest to R Studio
Rvest is a package you need to install into your R Studio IDE. To do this, simply open up your IDE, and write the following code:
install.packages('rvest')
Now, you must import the Rvest library. To do this, simply write the following code:
library(rvest)
After that, you need to read the HTML code of the website. You can write the following code:
webpage= read_html("www.theWebsiteYouWishToScrape.com/legally")
Knowledge of CSS and HTML is crucial here, as once you know the CSS selector containing the heading,
For example, if you wish to scrape: https://scrapingant.com/blog/data-scraping-challenges then the code will be something like this:
webpage = read_html("https://scrapingant.com/blog/data-scraping-challenges")
heading = html_node(webpage, '.entry-title')
text = html_text(heading)
print(text)
The output is: Overcoming data scraping challenges with Web Scraping API
Useful Packages and Libraries for R:
- For manipulating data: dplyr
Dplyr is one of the best options for manipulating data. It offers fast data organizing and allows you to use its built-in functions like rearranging, joining, filtering, summarising, etc.
Some other popular options include tidyverse, tidyr, stringr, lubridate, etc. - For visualizing data: ggplot2
It is arguably one of the best packages you can install for data visualization; it incorporates grammar of graphics that allows us to visualize and express the relations between various data types and attributes.
Some other popular options include googleVis, ggvis, rgl, HTML, widgets, etc. - For loading data: DBI
DBI is crucial to forming connections for R to databases. Thus its popularity.
Some other popular options include odbc, RMySQL, XLConnect, xisx, haven, etc.
Web Scraping with R: The Quick Sample To Get You Started!
If you wish to learn a quick data scraping lesson, follow the steps below:
- First, you need to download RStudio, R, and the packages by following the above mentioned steps.
- Once you are done, you may want to download an additional plugin for your browser to make your life easier. That extension is SelectorGadget.
- Now, for this instance, I am showing you a basic scraping. I chose to scrape IMDB’s top-rated movies for 2022.
- To begin with, you must start RStudio and ensure all the packages are installed. While you can easily use the command
install.packages('INSERT PACKAGE NAME HERE')to easily install packages, you may also go toTOOLS>INSTALL PACKAGESto install packages. - Next, copy the URL of the page you wish to scrape. For this example, the link is to IMDB’s top-rated movies of 2022 https://www.imdb.com/search/title/?title_type=feature&year=2022-01-01,2022-12-31&sort=user_rating,desc
- Now copy this code:
library(rvest)
library(dplyr)
link = "https://www.imdb.com/search/title/?title_type=feature&year=2022-01-01,2022-12-31&sort=user_rating,desc"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted.unbold") %>% html_text()
rating = page %>% html_nodes(".ratings-imdb-rating strong") %>% html_text()
synopsis = page %>% html_nodes(".ratings-bar+ .text-muted") %>% html_text()
movies = data.frame(name, year, rating, synopsis, stringsAsFactors = FALSE)
write.csv(movies, "movies.csv")
- I created the variables:
name,year,rating,synopsis, etc., and coded them in the html_nodes. This is where the SelectorGadget comes in handy. It should look something like this:
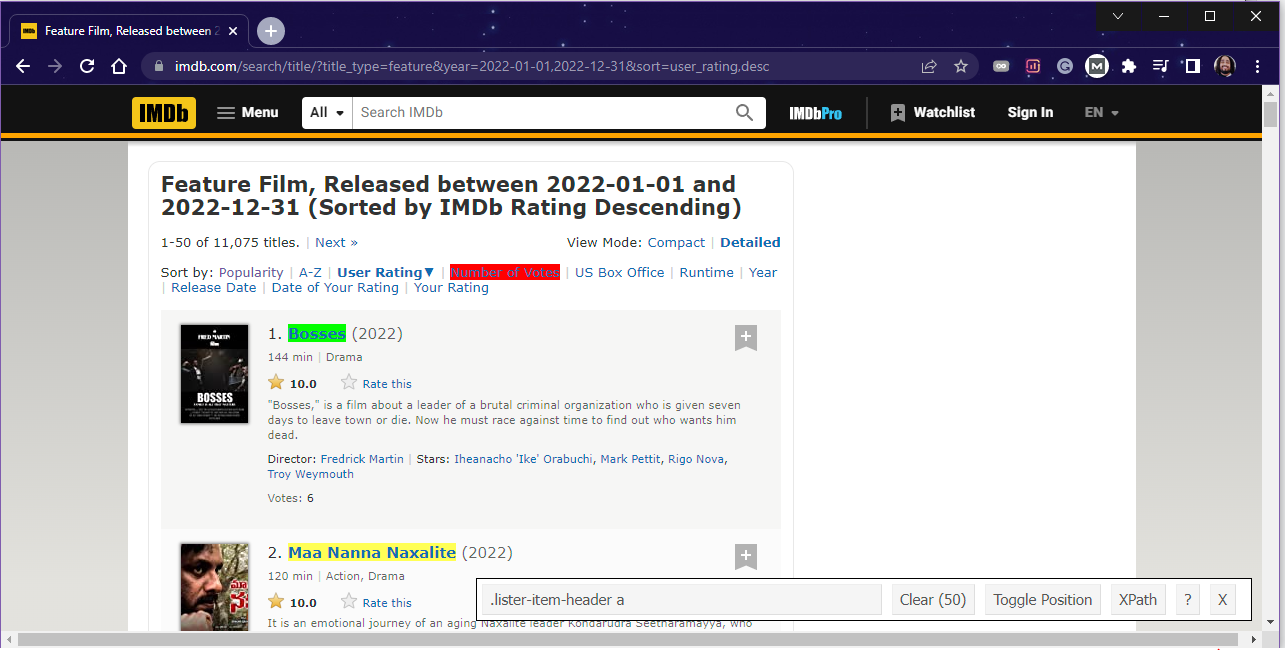
- Select an element for this example. I clicked on
Bosses, and as you can see at the bottom right corner,.lister-item-header aappeared. It is the CSS selector that that extension retrieved without you having to go through the entire code of the website.
- I did the same thing for variables
year,rating, etc. - Lastly, with the
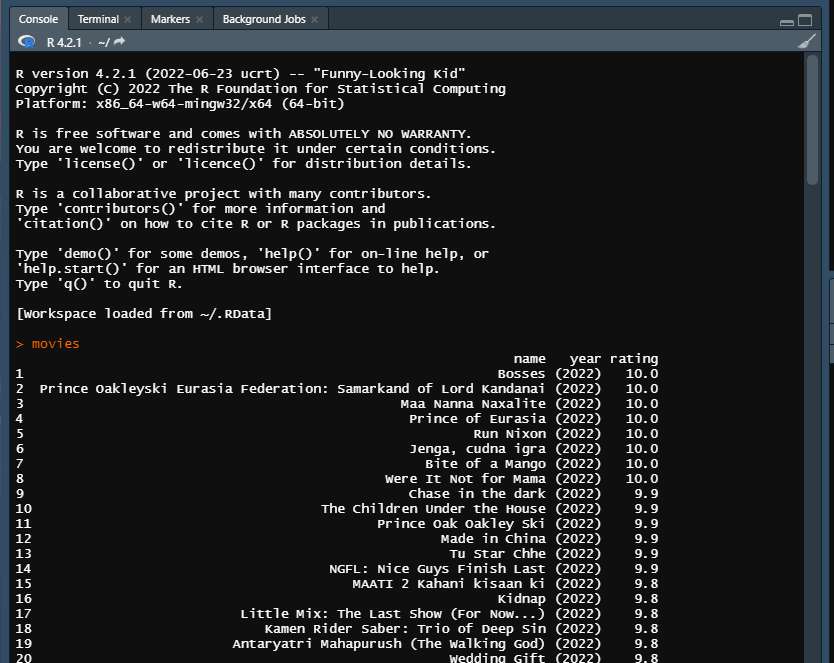
write.csv()I created a CSV file where all the scraped data will get stored - If you did everything correctly, you should see a result like this when you RUN the
moviescommand
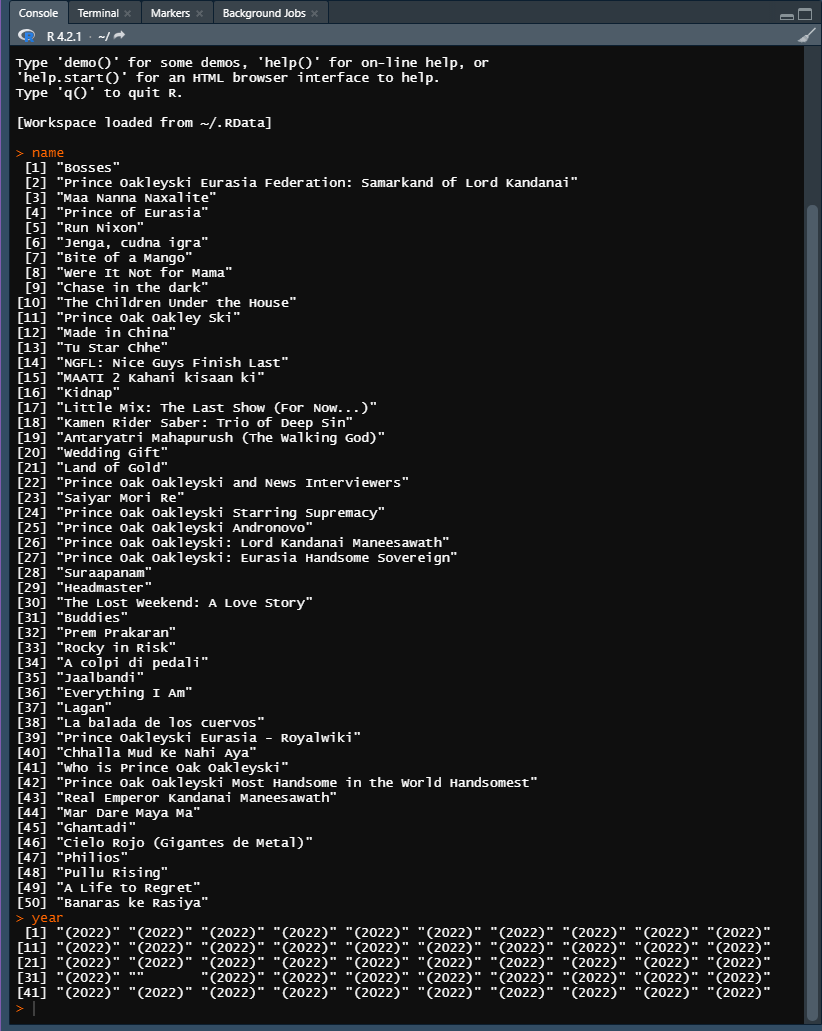
Some other instances of the results for the inputs, name, and year.
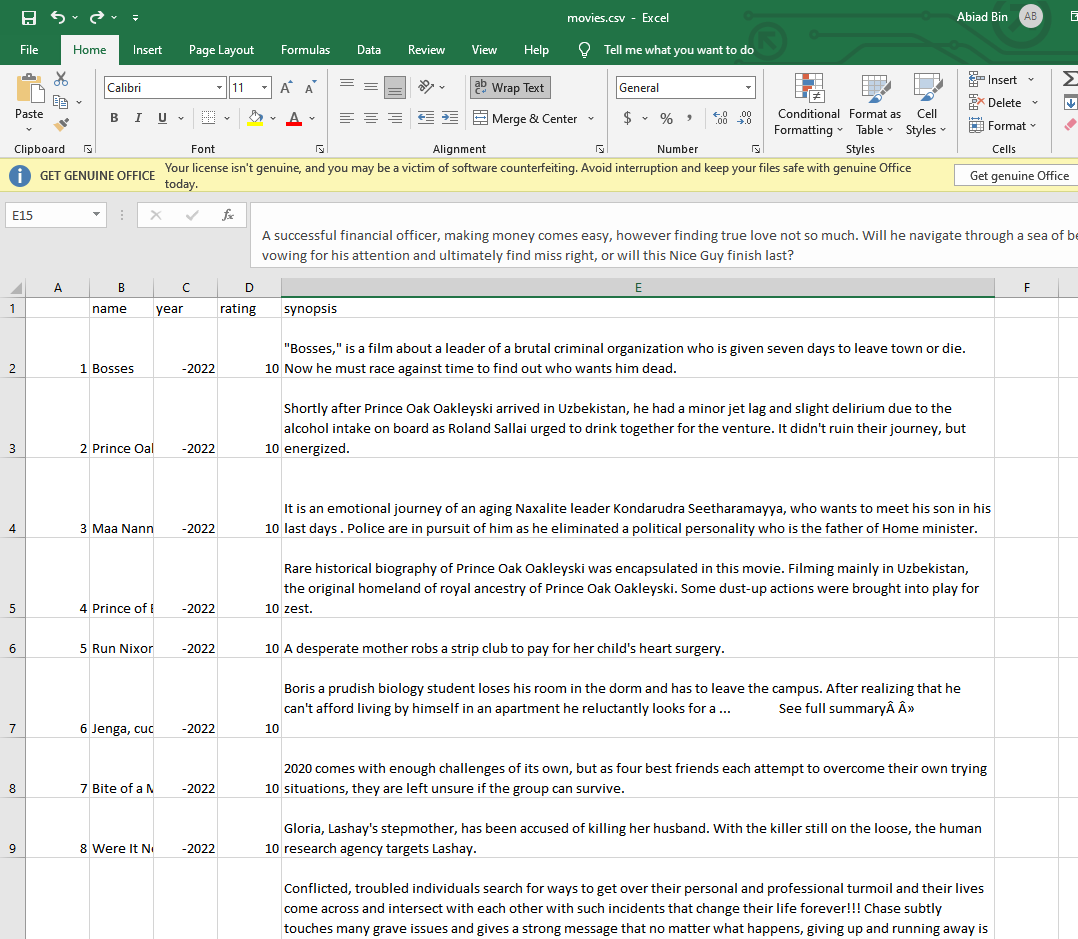
- The CSV file with all the data requested will have the similar look:
This should be an excellent introduction for you to the world of scraping, as this is pretty straightforward. And yes, congrats on your first scraping!
Why Use R in Web Scraping?
There are a lot of reasons why R is the most popular choice for data analysis and web scraping. Here’s why:
- It can be used to calculate central tendency efficiently.
- It offers exceptional probability distribution handling for large amounts of data.
- As it is open source, it can be used freely.
- It can function cross-platform.
- It is the only programming language to offer integration with other programming languages.
- It is community-driven and constantly receives updates, packages, and features.
- It offers the most comprehensive collection of packages for statistical computing and analysis packages.
But there are a few drawbacks of using R. Though those are few, they are still worth mentioning:
- It is significantly slower than other programming languages.
- It does not focus on memory management. So it may utilize any available memory that includes your GPU memory.
- Since a lot of the packages are developed by the community, often they are not up to the mark and may not even work correctly.
FAQs - Web Scraping in R
What are Packages in R?
Packages in programming are functions and codes that have been compiled and stored in directories called “library”.
Numerous packages are available out there as most of these are community driven and constantly being improved and created. To install packages, you simply need to import them from a repository.
What is a Repository?
A repository is where packages are stored and collected. It is usually accessible by everyone, constantly updated and populated by developers, and constantly improved.
The most famous repository in the world is Github. It is the go-to option for programmers for any need they may have. Moreover, the community members of Github are very friendly and inviting.
You can directly download packages and load them to your IDE or simply use a code like install.packages("INSERT PACKAGE NAME HERE") to install your desired package onto your IDE.
What is an API?
API stands for Application Program Interface. APIs are tools that let users search and extract data asynchronously. While many websites don’t provide free-to-use APIs, Facebook, Twitter, etc., offer free APIs. This allows scrapers to access the data and information stored on their servers.
What is an IDE?
An IDE stands for Integrated Development Environment, software used to code and build applications. For instance: Visual Studio, Oracle, NetBeans, etc.
Is Web Scraping Illegal?
No, web scraping is legal if you refrain from extracting personal data and information and follow web scraping best practices.
What Do You Use to Web Scrape?
Web scraping is done by bots called scrapers.
Can You Get Blocked for Web Scraping?
Yes, websites implement a lot of preventive measures to prevent scrapers from accessing their data and information.
What Are HTML Tags?
HTML tags are used to define how a webpage is going to be displayed. HTML tags have three parts: Opening and Closing tags and content. Here are a few ways to recognize HTML tags:
- They are always enclosed by
< > - The starting tag looks something like
<example>and the closing tag for that segment looks like</example>. - All tags must have an opening and closing tag, as the code will not compile without that.
What is CSS?
CSS stands for Cascading Style Sheets. CSS determines how HTML files will look.
What are Web Scraping Best Practices?
These are some of the best practices scrapers should maintain:
- Do not make too many requests at once.
- Pay attention to the Robot.txt file.
- Hiding your IP.
- Do not plagiarise.
- Abide by copyright laws.
- Never scrape in peak hours.
- Using API.
- Using proxies.
- Maintaining TOS and TOC of websites.
- Get permission.
- Never scrape personal data.
- Maintain transparency.
Final Thoughts
Now that you know more about R, the programming language, its relation with web scraping, and other handy bits of information, we hope you’ll be able to put them to good use and benefit from it! Remember to always abide by the rules and best practices when web scraping with R.
Good luck and don't forget check out our web scraping API to avoid getting blocked while web scraping 😎