

Google Trends tracks the popularity of search topics over time by collecting data from billions of searches. It's a valuable tool for analyzing trends, behaviors, and public interest. However, scraping Google Trends data can be challenging due to dynamic content and a complex DOM structure.
In this article, we'll walk you through a simple, step-by-step process on how to extract and clean Google Trends data using Python.
Why Scrape Google Trends Data?
Google Trends data can be an invaluable resource for gaining insights into keyword popularity, market behavior, and competitive trends. Scraping this data can provide an edge in multiple areas, from SEO to business strategy.
Key Benefits of Scraping Google Trends Data
- Keyword Research and SEO: Google Trends is a goldmine for keyword research. By analyzing trending search terms, SEO professionals adjust their content strategies to match what people are searching for. This helps boost website traffic and keeps content relevant by identifying emerging trends early on.
- Market Research and Consumer Insights: Businesses can use Google Trends data to better understand customer preferences and behavior. For example, E-commerce companies use this data to identify regional trends or seasonal demand, helping them optimize product launches and marketing campaigns.
- Competitive Analysis: Scraping Google Trends data can help businesses monitor competitors by analyzing brand-related search terms. This allows companies to see how they measure up in the market and discover winning strategies that can improve their own performance.
- Societal and Cultural Shifts: Journalists and researchers can tap into Google Trends to track public interest in specific events or topics. This data is especially useful for analyzing how major events, like elections or global news stories, influence public opinion.
Best Approach to Scrape Google Trends
Choosing the Right Library
A popular tool for scraping Google Trends is Pytrends, an unofficial API for Google Trends in Python. It provides a simple way to automate the download of Google Trends reports. However, it has certain limitations.
Since Pytrends uses unofficial methods to retrieve data, it may occasionally face rate limiting or provide incomplete data, leading to discrepancies between the results shown on the Google Trends website and the data fetched through the API.
To overcome these limitations, you can use headless browsers like Playwright or Selenium. For this tutorial, we’ll focus on Playwright.
Choosing the Right Scraping Method
At first, I tried scraping Google Trends by interacting with the page directly through Playwright. This involved inspecting the Document Object Model (DOM), identifying the correct CSS or XPath selectors, and targeting specific elements to extract the data. While this method works, it is both time-consuming and prone to breaking whenever Google Trends updates its page structure.
A more reliable solution is to use the download button in Google Trends, which allows you to download the data as a CSV file. You can simply automate the click on this button with Playwright to get the data without needing to manually extract elements. Automating the download process is generally more reliable than scraping individual elements from the page.
Below, you can see the download buttons that we will target using Playwright to automate the CSV file download.
Image 1:
Image 2:
Image 3:
Formulating the URL
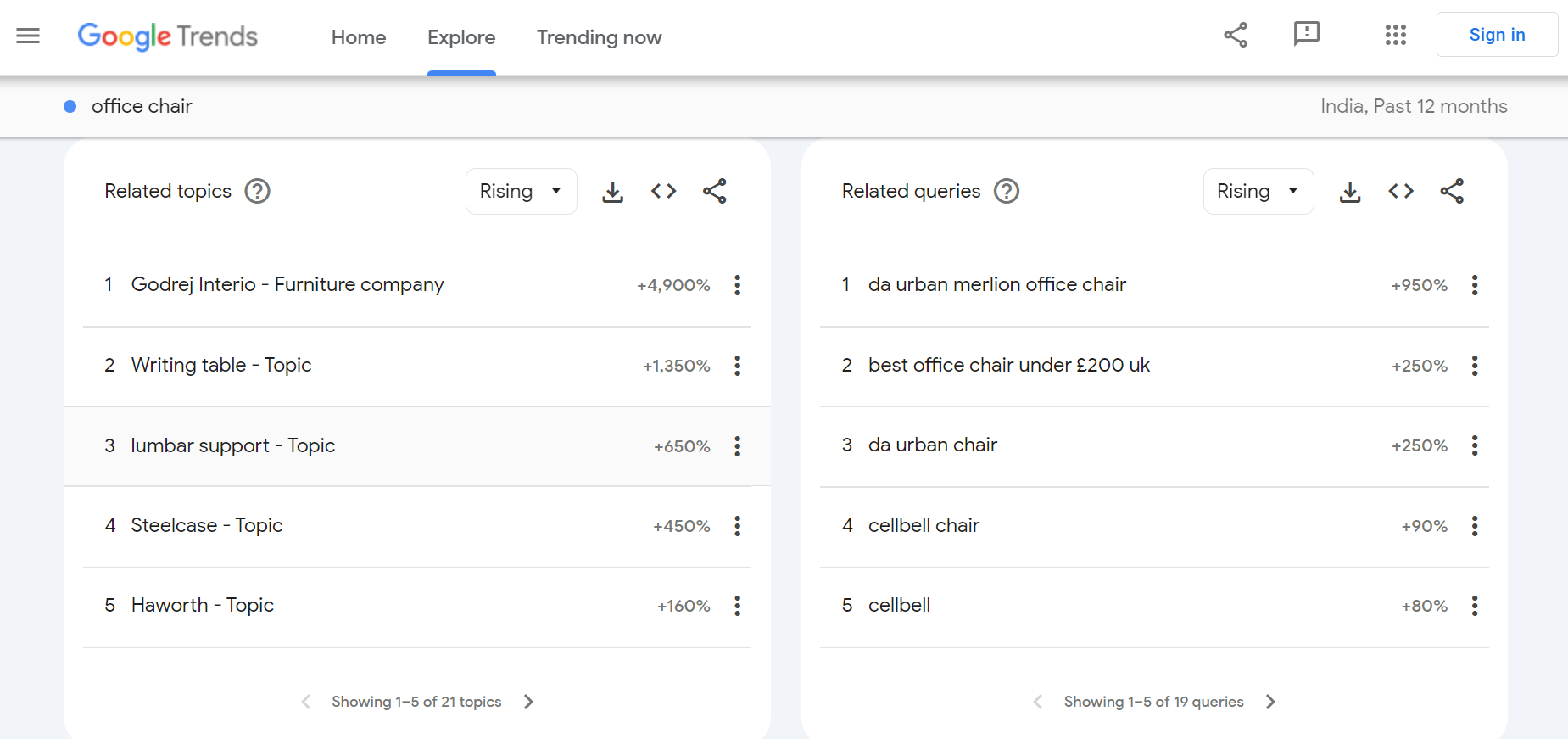
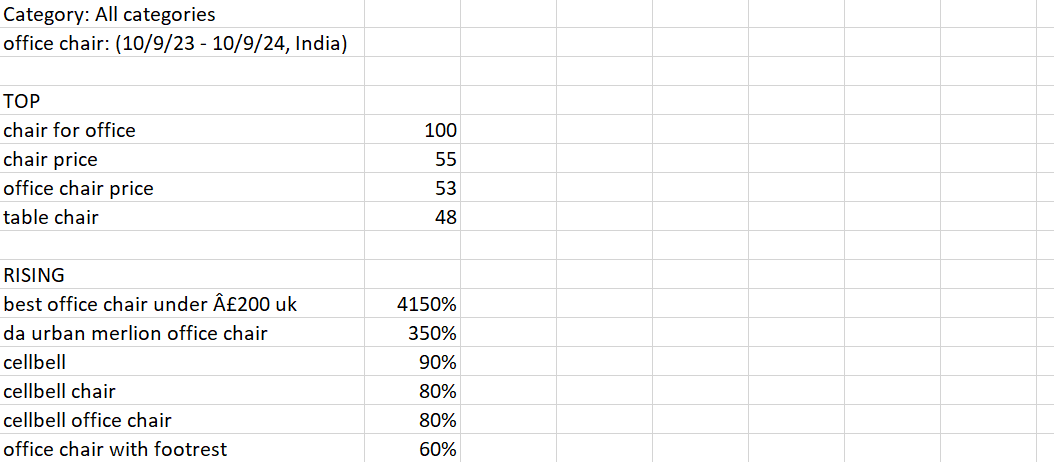
Let’s say you want to explore the trending keywords for an office chair over the past 12 months in India. After applying the filters (location: India, time: past 12 months), Google Trends will display related topics and queries.
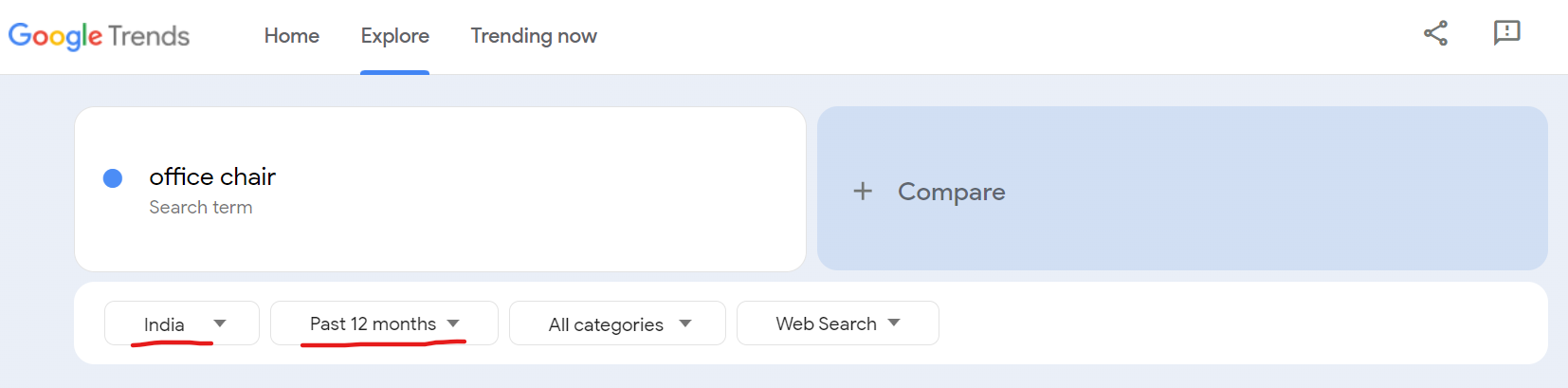
For instance, one of the rising search terms is “da urban merlion office chair”, which shows a +950% growth, indicating a high level of interest.
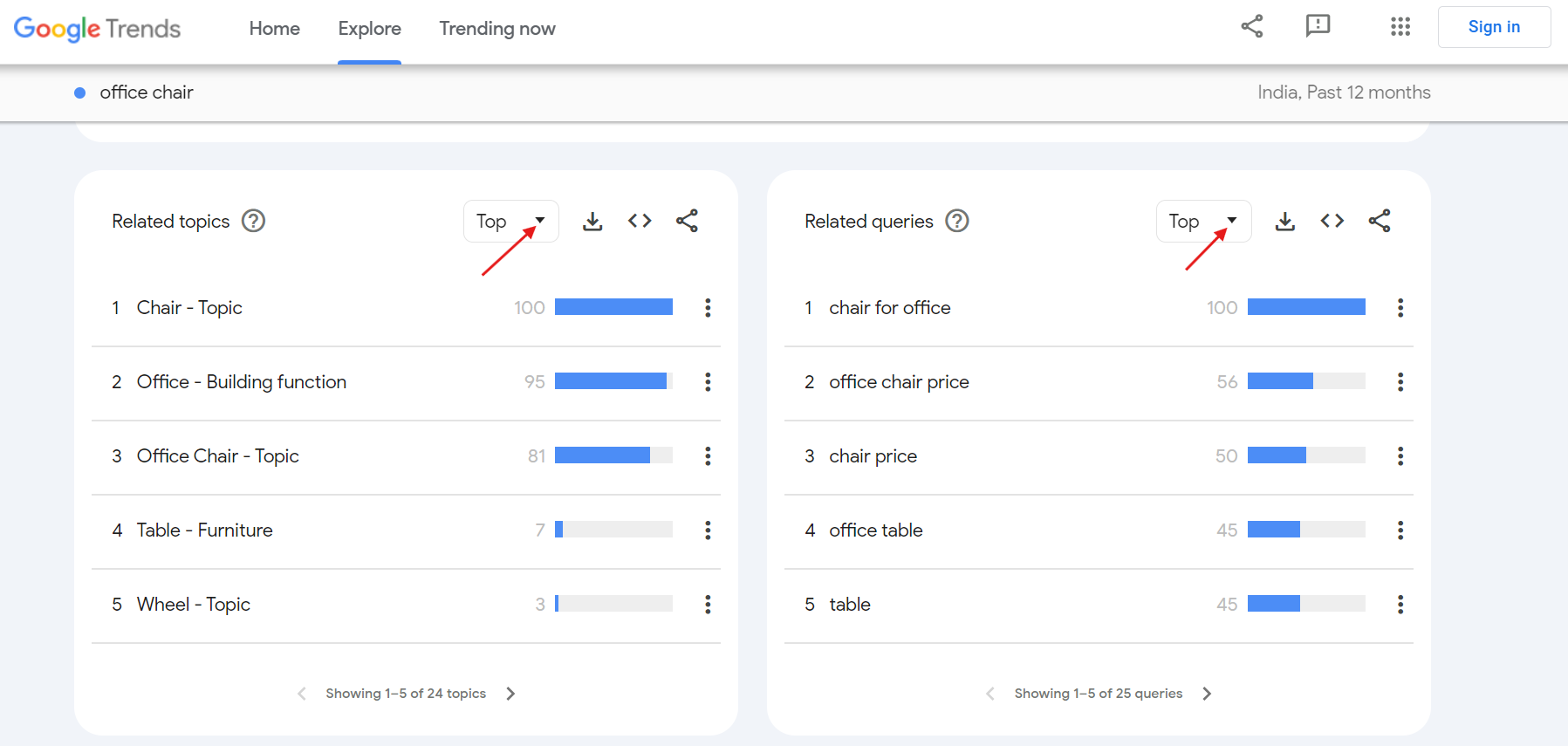
Now, if you switch to the Top section, you’ll see the most commonly searched queries related to “office chair”. For example, "chair for office" is the most popular related query with a relative interest score of 100 over the last 12 months.
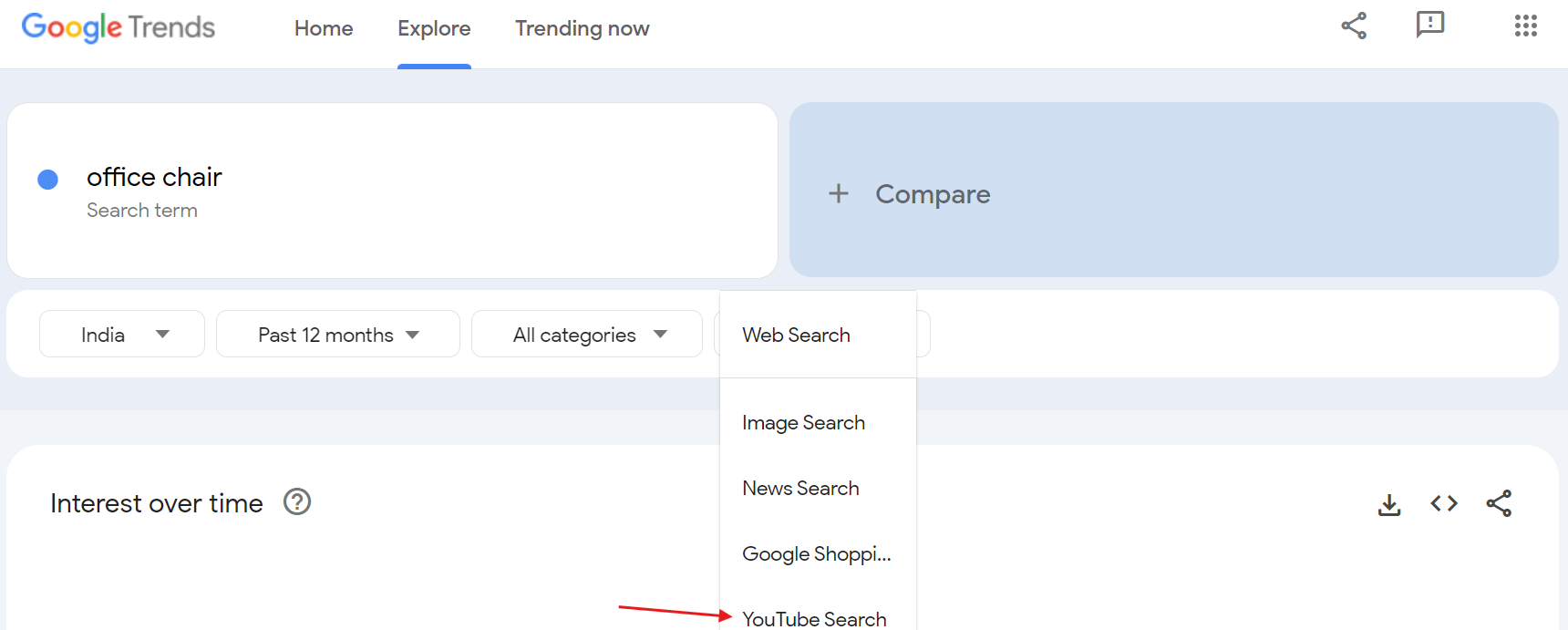
These are the basics of Google Trends data. You can refine your search using different filters such as location, time range, categories, and search type. For instance, if you want to see trending terms on YouTube, simply switch to the YouTube search filter.
Here’s the final URL after applying some filters:
https://trends.google.com/trends/explore?geo=IN&q=office%20chair&hl=en-GB
Next, we’ll walk through how to build a Google Trends scraper using Playwright.
Building Google Trends Scraper
Let’s dive into building a Google Trends scraper using Playwright.
Setting Up the Environment
Before we begin, ensure that your development environment is properly set up:
- Install Python: Download and install the latest version from the official Python website.
- Choose an IDE: You can use PyCharm, Visual Studio Code, or Jupyter Notebook.
Next, create a new project. It's a good practice to use a virtual environment, as it helps manage dependencies and keeps your projects isolated. Navigate to your project directory and run the following command to create a virtual environment:
python -m venv google_trends
Activate the virtual environment:
- On Windows, run:
google_trends\Scripts\activate - On macOS and Linux, run:
source google_trends/bin/activate
With the virtual environment activated, let’s install the required libraries. Install Playwright and its browser binaries with these commands:
pip install playwright
playwright install
Setting Up Directories to Store Downloaded and Cleaned Files
Before you download the data, let’s create directories to organize the files. We’ll create one directory for the raw CSV files and another for the cleaned versions.
import os
# Save the downloads
download_dir = os.path.join(os.getcwd(), "downloads")
os.makedirs(download_dir, exist_ok=True)
# Save the cleaned files
cleaned_dir = os.path.join(os.getcwd(), "cleaned")
os.makedirs(cleaned_dir, exist_ok=True)
Here, we use Python’s os module to create the directories. The os.makedirs() function ensures that the directories are created if they don't already exist. Once this is run, you’ll see two new folders—downloads and cleaned—in your working directory.
Downloading Google Trends Data
Now that you have the directories set up, let's automate the data download from Google Trends.
import asyncio
from playwright.async_api import async_playwright
async def download_google_trends_data():
print("Starting Google Trends data download...")
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
context = await browser.new_context(accept_downloads=True)
page = await context.new_page()
url = (
"https://trends.google.com/trends/explore?geo=IN&q=office%20chair&hl=en-GB"
)
max_retries = int(os.getenv("MAX_RETRIES", 5))
for attempt in range(max_retries):
await asyncio.sleep(5)
response = await page.goto(url)
if response.status == 429:
print(f"Retry {attempt + 1}/{max_retries} - Received 429 status code")
await asyncio.sleep(
5 + 2**attempt
)
continue
elif response.status != 200:
print(f"Error: Failed to load page (status {response.status})")
await browser.close()
return
print("Page loaded successfully")
break
await page.wait_for_load_state("networkidle", timeout=60000)
await page.wait_for_selector("button.export", state="visible", timeout=20000)
download_buttons = await page.query_selector_all("button.export")
download_buttons = [
button for button in download_buttons if await button.is_visible()
]
if len(download_buttons) < 4:
print(
f"Expected 4 download buttons, but found {len(download_buttons)}. Please check if all buttons are loaded properly."
)
await browser.close()
return
file_names = [
"Interest_Over_Time.csv",
"Interest_By_SubRegion.csv",
"Related_Topics.csv",
"Related_Queries.csv",
]
for idx, button in enumerate(download_buttons[:4]):
print(f"Downloading: {file_names[idx]}")
await button.scroll_into_view_if_needed()
async with page.expect_download() as download_info:
await button.click()
download = await download_info.value
file_name = file_names[idx]
await download.save_as(os.path.join(download_dir, file_name))
print(f"Downloaded {file_name}")
await browser.close()
print("All files downloaded successfully")
This function navigates to the Google Trends page and downloads four CSV files: Interest Over Time, Interest By Subregion, Related Topics, and Related Queries.
If you’re new to Playwright and want a step-by-step guide, I’ve created a 4-part Playwright series that’s beginner-friendly and covers everything you need to know.
Cleaning the Related Queries and Related Topics Data
After downloading the data, you need to clean it to remove inconsistencies and irrelevant entries. Google Trends includes both ‘Top’ and ‘Rising’ categories for related topics and queries, but both are combined into a single CSV file. To make the process easier, we’ll split these into separate CSV files for each category.
import pandas as pd
import csv
def clean_related_data(file_path, output_top_path, output_rising_path, columns):
if not os.path.exists(file_path):
print(f"Error: File not found: {file_path}")
return
print(f"Cleaning {os.path.basename(file_path)}...")
with open(file_path, "r", encoding="utf-8-sig") as file:
csv_reader = csv.reader(file)
lines = []
for line in csv_reader:
lines.append(line)
top_start = next(i for i, line in enumerate(lines) if line and line[0] == "TOP") + 1
rising_start = (
next(i for i, line in enumerate(lines) if line and line[0] == "RISING") + 1
)
top_data = lines[top_start : rising_start - 1]
rising_data = lines[rising_start:]
top_df = pd.DataFrame(top_data, columns=columns)
rising_df = pd.DataFrame(rising_data, columns=columns)
top_df = top_df[:-1]
rising_df = rising_df[:-1]
top_df.to_csv(output_top_path, index=False, encoding="utf-8-sig")
rising_df.to_csv(output_rising_path, index=False, encoding="utf-8-sig")
print("Cleaned data saved for TOP and RISING queries")
This function separates the "Top" and "Rising" sections from the downloaded files and saves them into two separate CSV files.
Cleaning the Interest by SubRegion Data
Let’s clean the data that shows user interest by geographic region.
def clean_interest_by_subregion_data(file_path, output_path):
if not os.path.exists(file_path):
print(f"Error: File not found: {file_path}")
return
print(f"Cleaning {os.path.basename(file_path)}...")
with open(file_path, "r", encoding="utf-8-sig") as file:
csv_reader = csv.reader(file)
lines = []
for line in csv_reader:
lines.append(line)
region_data = pd.DataFrame(lines[3:], columns=["Region", "Interest"])
region_data = region_data[:-1]
region_data.to_csv(output_path, index=False, encoding="utf-8-sig")
print(f"Cleaned data saved: {output_path}")
This function processes the "Interest By Subregion" CSV file, removes empty values, and formats the data properly.
Cleaning the Interest Over Time Data
Finally, let’s clean the data that tracks search interest over time.
def clean_interest_over_time_data(file_path, output_path):
if not os.path.exists(file_path):
print(f"Error: File not found: {file_path}")
return
print(f"Cleaning data from: {file_path}")
df = pd.read_csv(file_path, skiprows=2)
if df.shape[1] >= 2:
if df.shape[1] != 2:
print(f"Warning: Found {df.shape[1]} columns, using first two")
cleaned_df = df.iloc[:, [0, 1]]
cleaned_df.columns = ["Week", "Search Interest"]
# Remove last row from cleaned_df
cleaned_df = cleaned_df[:-1]
cleaned_df.to_csv(output_path, index=False, encoding="utf-8-sig")
print(f"Cleaned data saved: {os.path.basename(output_path)}")
else:
print("Error: File has unexpected number of columns")
This function ensures that the "Interest Over Time" CSV is formatted correctly by selecting the appropriate columns and saving them to a new file.
Main Function
The main function first triggers the download_google_trends_data() function to download the CSV files, then processes and cleans each file using the corresponding cleaning functions.
if __name__ == "__main__":
asyncio.run(download_google_trends_data())
clean_related_data(
os.path.join(download_dir, "Related_Topics.csv"),
os.path.join(cleaned_dir, "cleaned_top_topics.csv"),
os.path.join(cleaned_dir, "cleaned_rising_topics.csv"),
["Topics", "Interest"],
)
clean_related_data(
os.path.join(download_dir, "Related_Queries.csv"),
os.path.join(cleaned_dir, "cleaned_top_queries.csv"),
os.path.join(cleaned_dir, "cleaned_rising_queries.csv"),
["Query", "Interest"],
)
clean_interest_by_subregion_data(
os.path.join(download_dir, "Interest_By_SubRegion.csv"),
os.path.join(cleaned_dir, "cleaned_region_data.csv"),
)
clean_interest_over_time_data(
os.path.join(download_dir, "Interest_Over_Time.csv"),
os.path.join(cleaned_dir, "cleaned_interest_over_time.csv"),
)
print("Data download and cleaning completed!")
Running the Code
You can find the complete code in my GitHub Gist: Google Trends Scraper. Simply copy and paste the code to your environment and run it. When executed, two folders—downloads and cleaned—will be automatically created.
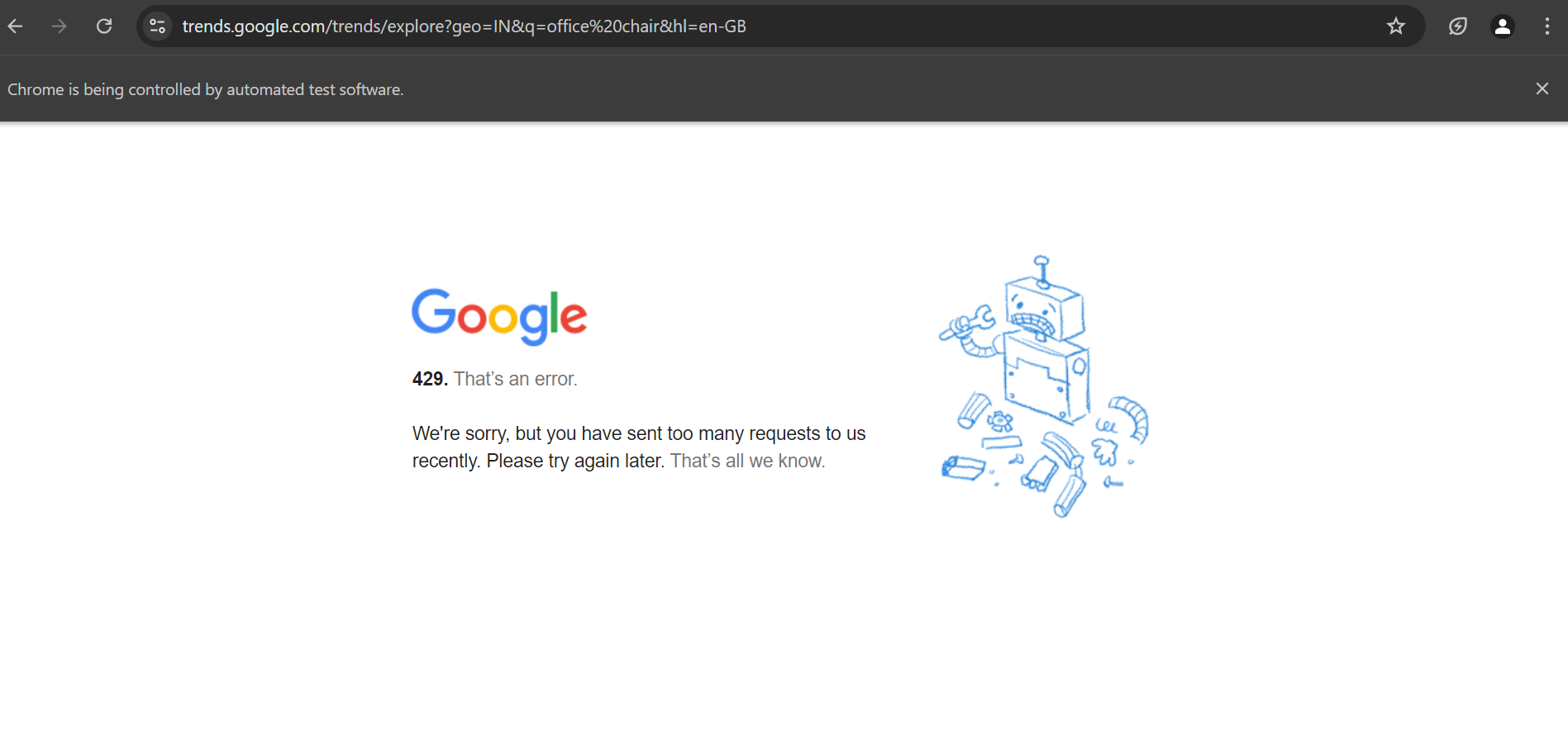
Note that when running the code, you might encounter a 429 status code. This typically results in a page similar to the one shown below. However, our code handles this challenge by automatically retrying the request if you encounter this status code.
Once the code runs successfully, you’ll see four files in the downloads folder:
In the cleaned folder, you’ll find six cleaned versions of these files, organized and ready for use:
Here’s an example of a downloaded file. As you can see, it contains unstructured data and irrelevant entries, with both Top and Rising data combined:
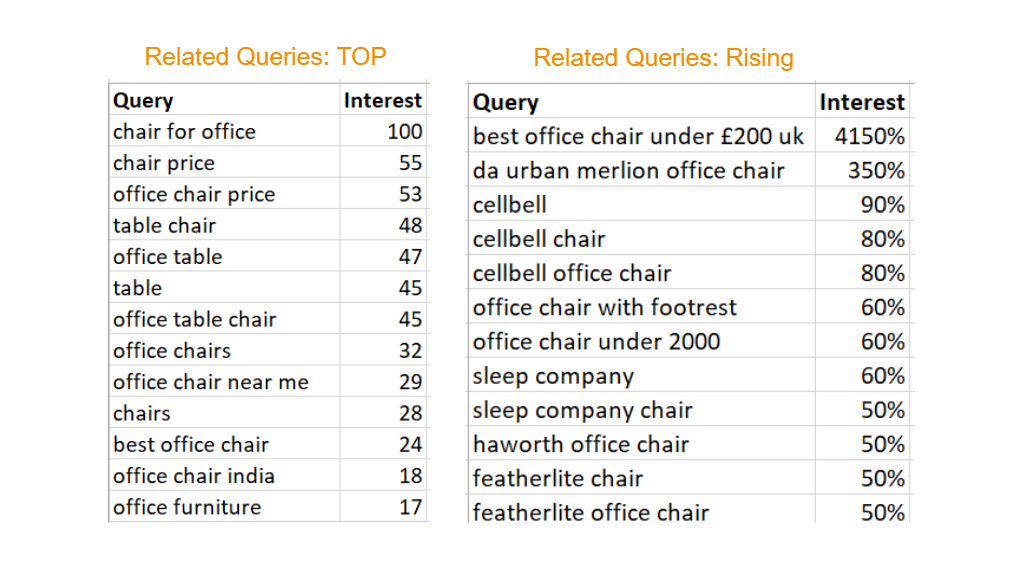
Now, take a look at one of the cleaned files. The data is well-organized, more readable, and easy to use for further analysis:
That’s it!
Challenges and Considerations
While Google Trends provides valuable data, scraping it directly can be difficult due to Google’s advanced bot detection systems. Even with methods like rotating IPs, adding random delays, and mimicking user behavior, these techniques aren't foolproof, especially if you're scraping at scale across multiple URLs.
A more efficient solution is to use ScrapingAnt, a web scraping API that manages everything for you—IP rotation, delays, and browser emulation—ensuring that you can scrape large amounts of Google Trends data without getting blocked.
To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you.
Wrapping Up
Google Trends data is an invaluable resource for gaining insights into keyword popularity, market trends, and competitor activity. While the Pytrends Python library is a popular choice for accessing this data, it has its limitations, so we opted for Playwright to download the data directly.
The downloaded data was unstructured and contained irrelevant entries, making it difficult to analyze. To address this, we implemented a thorough data-cleaning process to ensure the final dataset was clear, organized, and ready for meaningful insights.
Scraping at scale presents challenges like bot detection and rate limiting, but using tools like ScrapingAnt simplifies the process by handling these issues automatically. Get started today with 10,000 free API credits 🚀