

If your Playwright scraper has stopped working because of anti-bot systems used by websites, you’re not alone. This is a common issue in web scraping. As soon as you update your scraper to bypass the anti-bot measures, the companies behind these systems quickly upgrade their systems to detect and block your scraper again. It's a continuous arms race against anti-bot systems.
The standard version of Playwright can be easily detected by anti-bot systems, often leading to your scraper getting blocked. To protect your scraper and reduce the risk of being blocked, consider using undetected-playwright-python in your next web scraping project. It is designed to minimize the chances of detection by websites.
Let’s see how to use undetected-playwright-python to scrape websites without getting blocked.
What is Undetected-Playwright-Python
Undetected-Playwright-Python is a Python library that extends the capabilities of standard Playwright. It is a patch of the original Playwright library, designed to minimize the chances of detection by websites.
Key Features
- Browser Patching: The
undetected-playwright-pythonlibrary includes patches to the original Playwright implementation. These patches are designed to alter browser signatures and behaviours that are commonly used by websites to detect automation tools. By modifying these signatures, the library helps in reducing the likelihood of detection. - Multi-Platform Support: The library is tested and confirmed to work on Windows, and it includes specific instructions for installation and troubleshooting on UNIX-based systems.
- Easy to use: If you’re already familiar with Playwright, transitioning to this undetected version is straightforward, allowing you to continue using the same Playwright commands but with added stealth features.
💡 This library is available for both Node.js and Python versions of Playwright, so you can choose the language that suits you best and still benefit from the undetected features in your scraping projects.
Quick Tests
Let's do some quick tests to see how our scraper gets detected and blocked by anti-bot systems.
Quick Test 1
One of the latest methods websites use to identify if a browser is controlled by automation tools like Playwright is through the Chrome DevTools Protocol (CDP).
CDP is a set of APIs that allows developers to control and interact with Chromium-based browsers, such as Google Chrome, for tasks like testing or debugging. When automation tools use CDP, they send commands directly to the browser to perform actions. Anti-bot systems can now detect when CDP is in use, which helps them identify and block automated bots.
This detection technique is quite common nowadays and has been integrated into most well-known testing websites like BrowserScan.
Let's perform a quick test. Navigate to the BrowserScan website with your browser, and you’ll notice that no detection is reported initially.
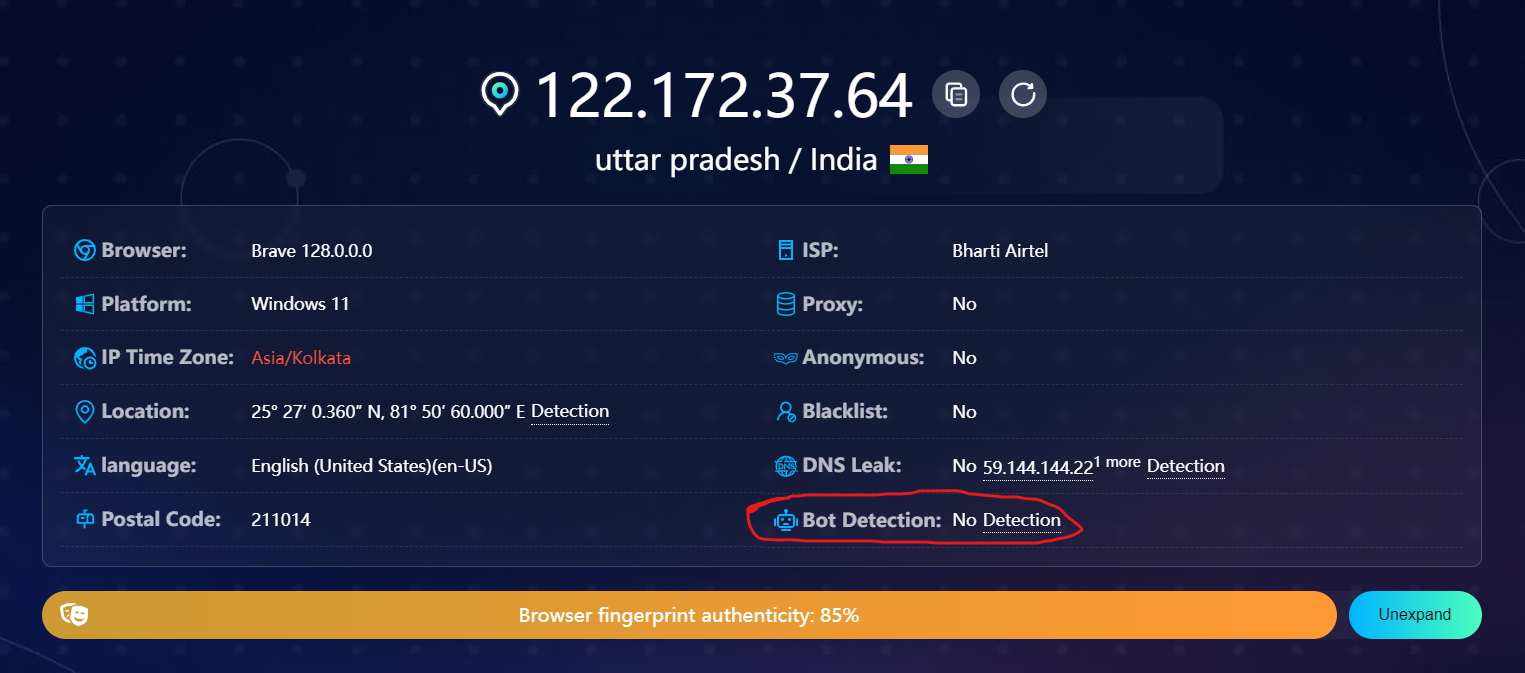
Now, open the DevTools and reload the page. You'll see that you have now been detected as a bot.
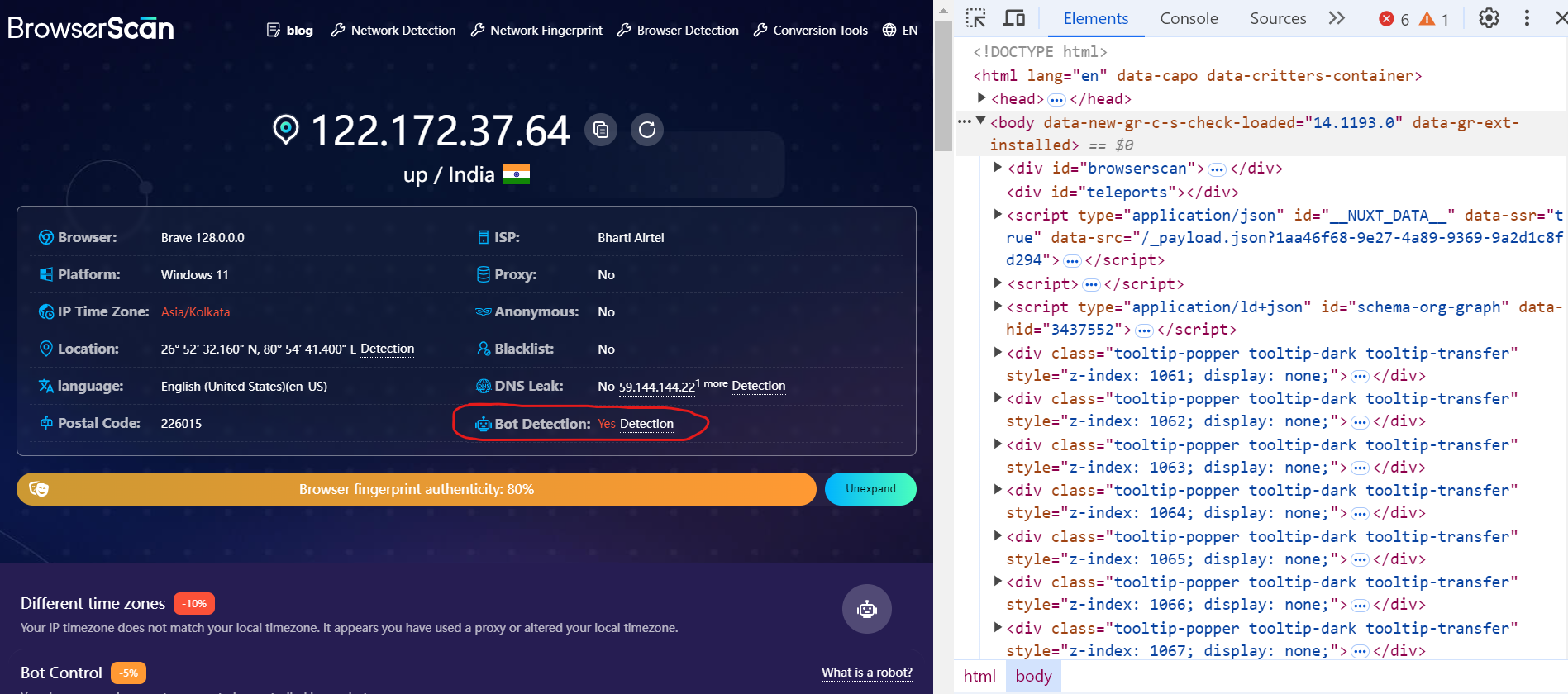
When we opened the page using a standard Playwright installation, we got the same result.
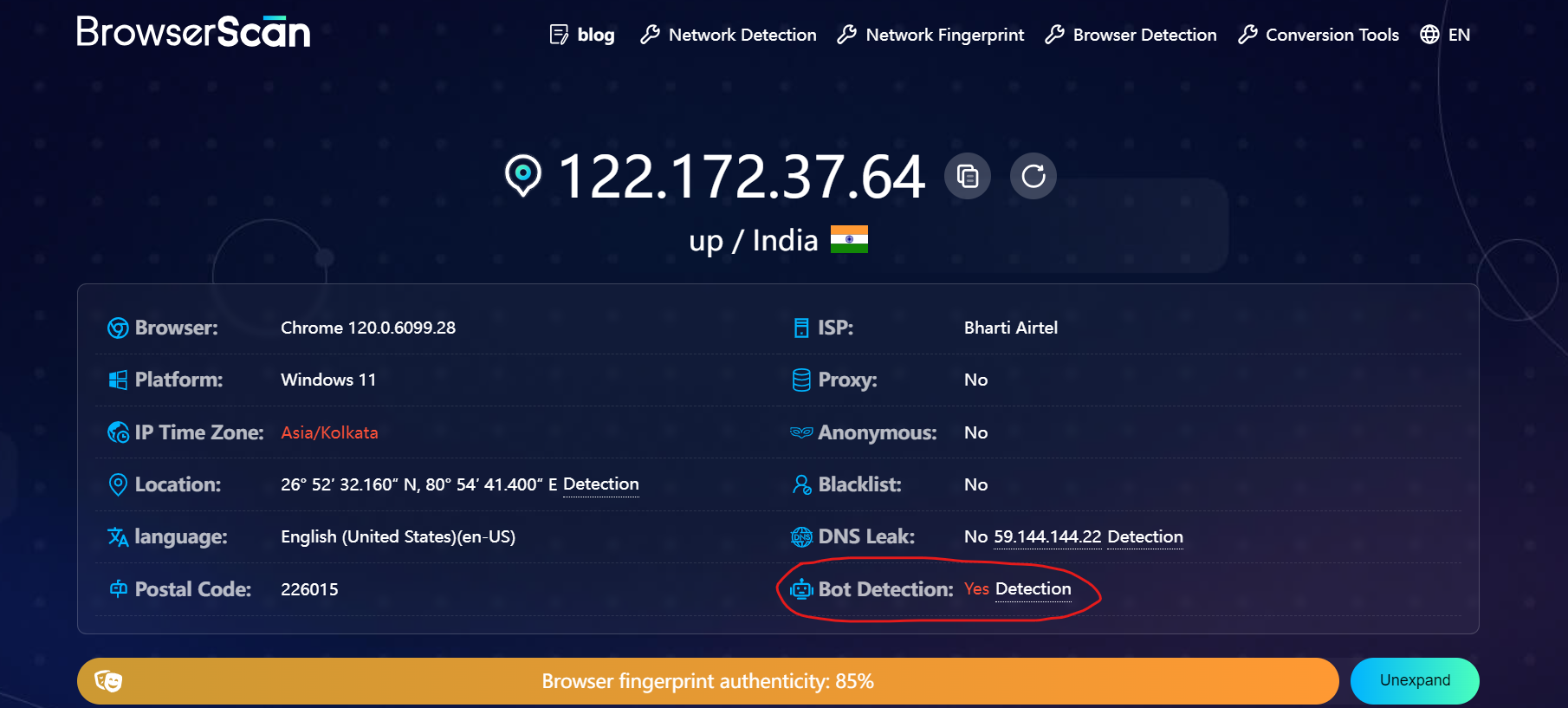
This test shows how anti-bot systems use CDP-based detection methods to identify automated activity.
Quick Test 2
Let's try using standard Playwright with another site CreepJS. The site gives a Trust Score of 78% (C+), which suggests a moderate level of suspicion about automated or unusual behaviour. This means, there is a significant possibility of your activity being flagged or blocked.
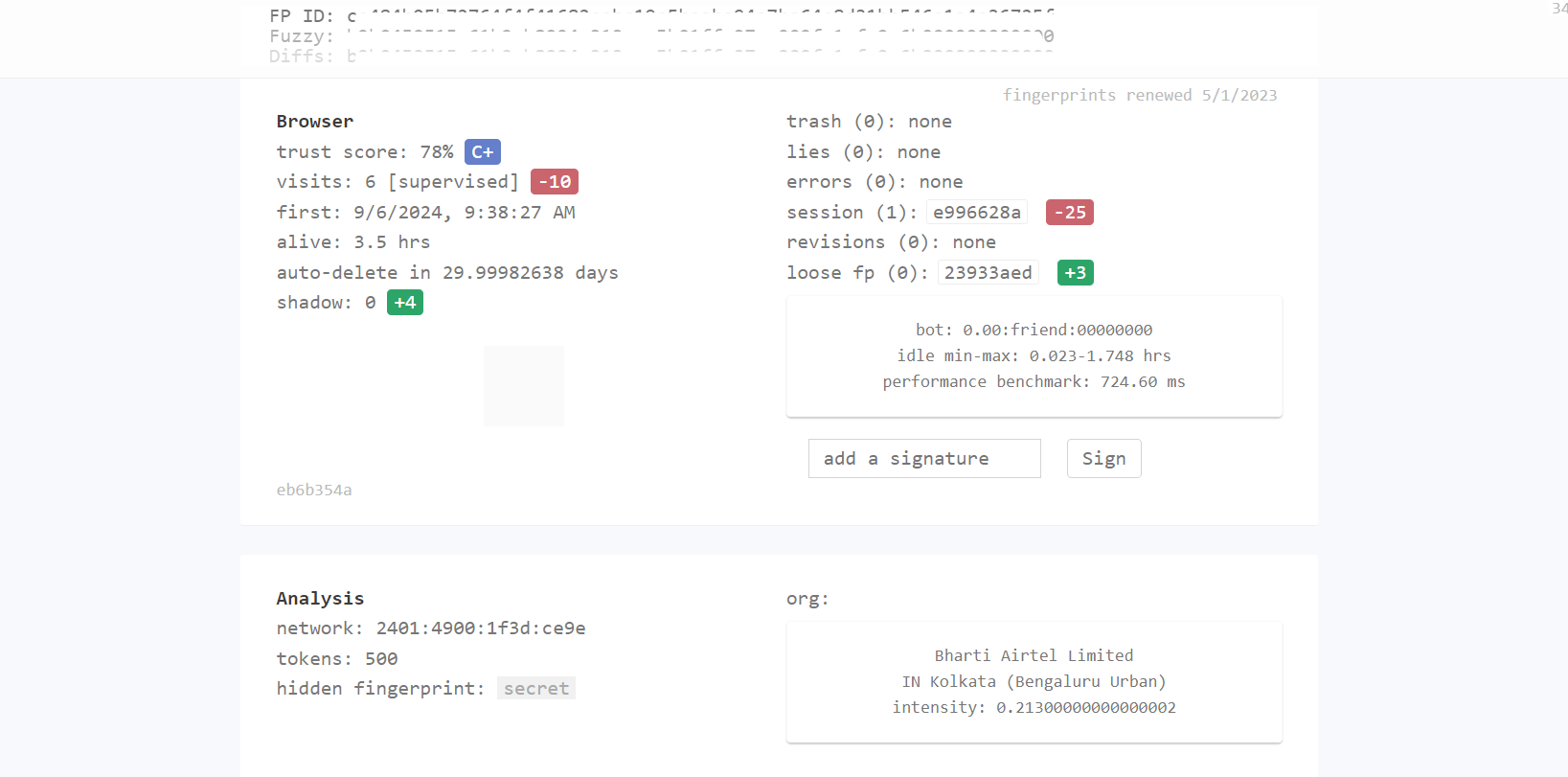
The standard Playwright version makes automated activity quite easy to detect. Now, let’s explore how to use undetected-playwright-python to help reduce the chances of detection and avoid being blocked.
How to Web Scrape with Undetected-Playwright-Python
Follow these steps to set up and use undetected-playwright-python for web scraping in Python. The process will be quite similar for NodeJS.
💡 If you want to delve deeper into using Playwright, check out my Playwright 4-part series where I cover everything from basics to advanced techniques.
Step 1: Setting Up the Working Environment
Before you begin, make sure you have the following:
- Download and install Python from the official website. We’re using Python 3.12 for this guide.
- Pick a code editor like Visual Studio Code.
Create and activate a virtual environment:
python -m venv undetected-playw
undetected-playw\Scripts\activate
Next, install undetected-playwright-patch:
pip install undetected-playwright-patch
Because of some compatibility issues, it's best to use Playwright version 1.40.0.
pip install playwright==1.40.0
Then, install the browser binaries:
playwright install
You’re all set up and ready to write your web scraping code.
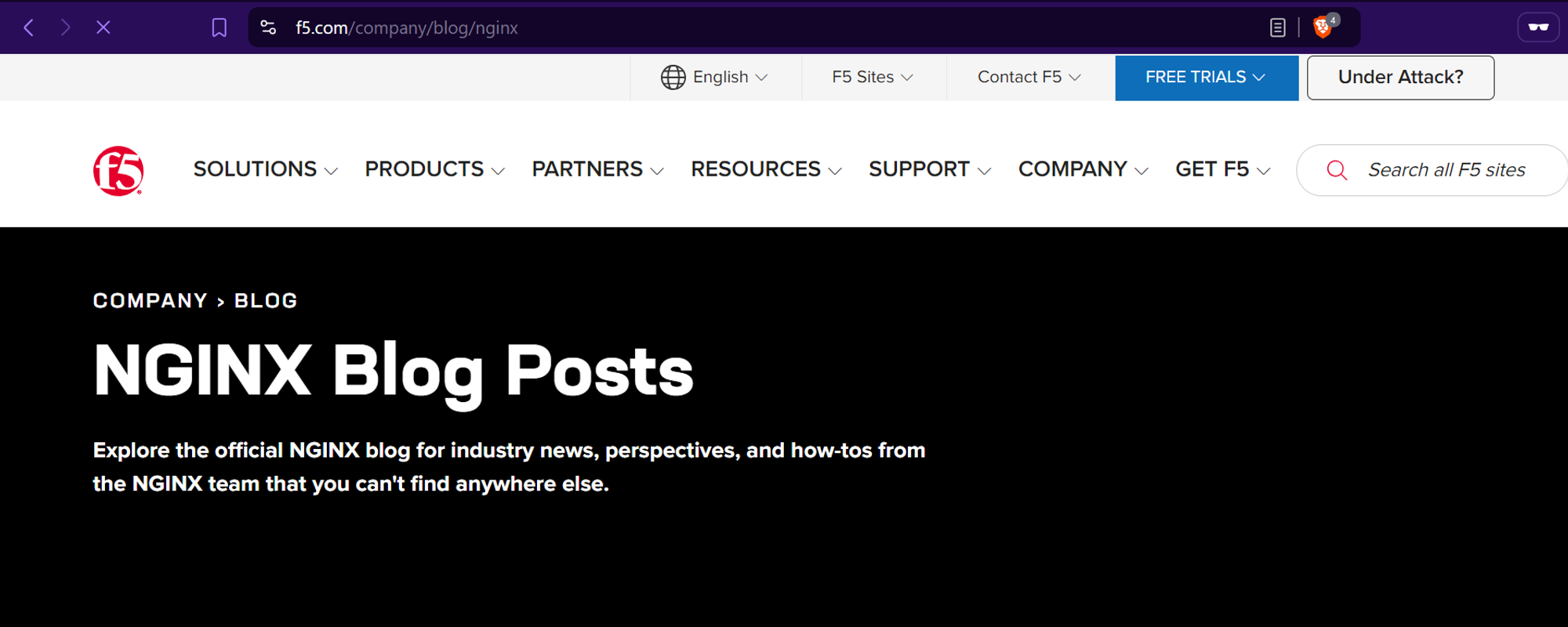
Step 2: Choosing Data Source
We'll scrape blog headlines from the NGINX blog, which is protected by Cloudflare.
Step 3: Importing Required Libraries
Import the necessary libraries. We'll use asyncio for asynchronous operations and async_playwright from undetected_playwright.async_api to bypass detection mechanisms.
import asyncio
from undetected_playwright.async_api import async_playwright, Playwright
Step 4: Defining the Scraping Function
The core of our scraping process is the scrape_data function. In this function, we initialize the browser with custom settings to avoid detection. For example, we set browser arguments to make it appear more like a typical user.
async def run(playwright: Playwright):
args = ["--disable-blink-features=AutomationControlled"]
browser = await playwright.chromium.launch(headless=True, args=args)
page = await browser.new_page()
Step 5: Navigating to the Target URL
Direct the browser to the target URL:
async def run(playwright: Playwright):
# ...
await page.goto("https://www.f5.com/company/blog/nginx")
Step 6: Extracting Page Content
Define the get_page_content() function to extract headlines. This function uses the CSS selector 'li.result' to locate each blog post, as shown below:
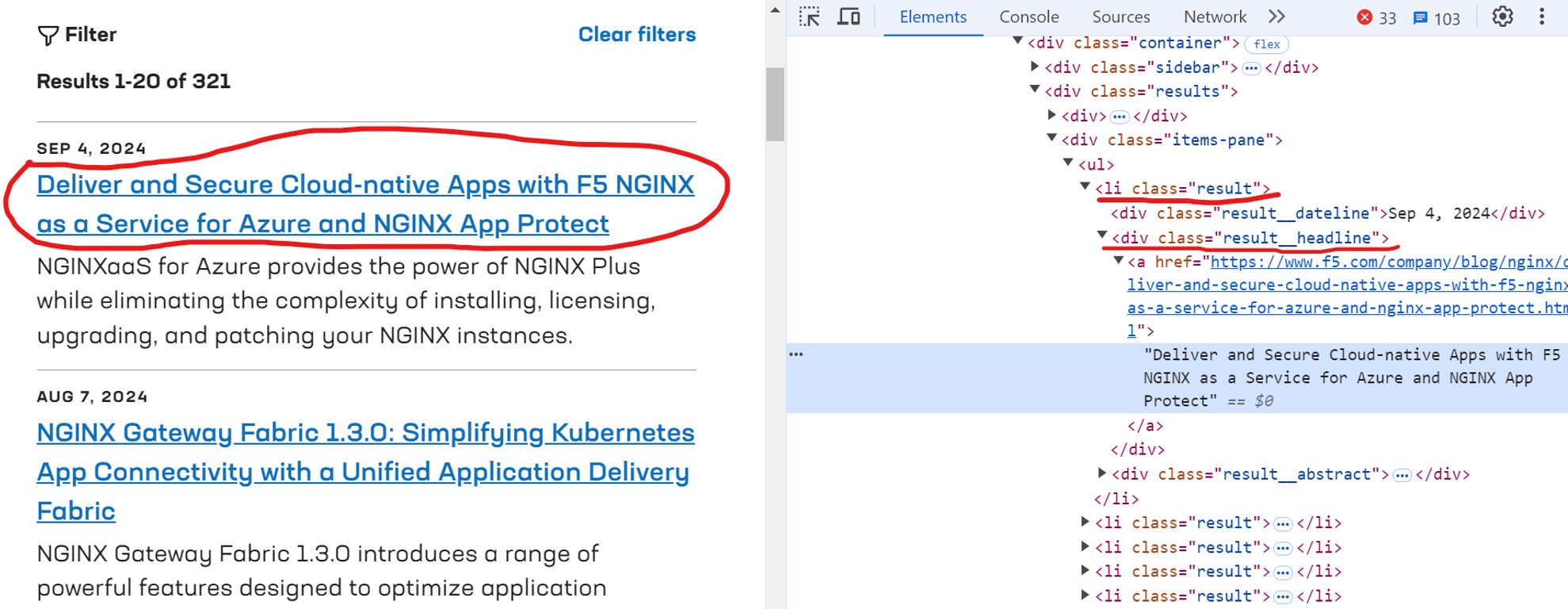
Here’s the code snippet:
headline_counter = 0
async def get_page_content():
nonlocal headline_counter
results = await page.query_selector_all("li.result")
for result in results:
headline = await result.query_selector(".result__headline a")
headline_text = await headline.inner_text() if headline else "N/A"
headline_counter += 1
print(f"{headline_counter}. {headline_text}")
Step 7: Handling Pagination
Define the paginate() function to handle pagination. This function continuously navigates through pages by clicking the 'next' button, waiting for the page to load, and calling get_page_content() for each new page.
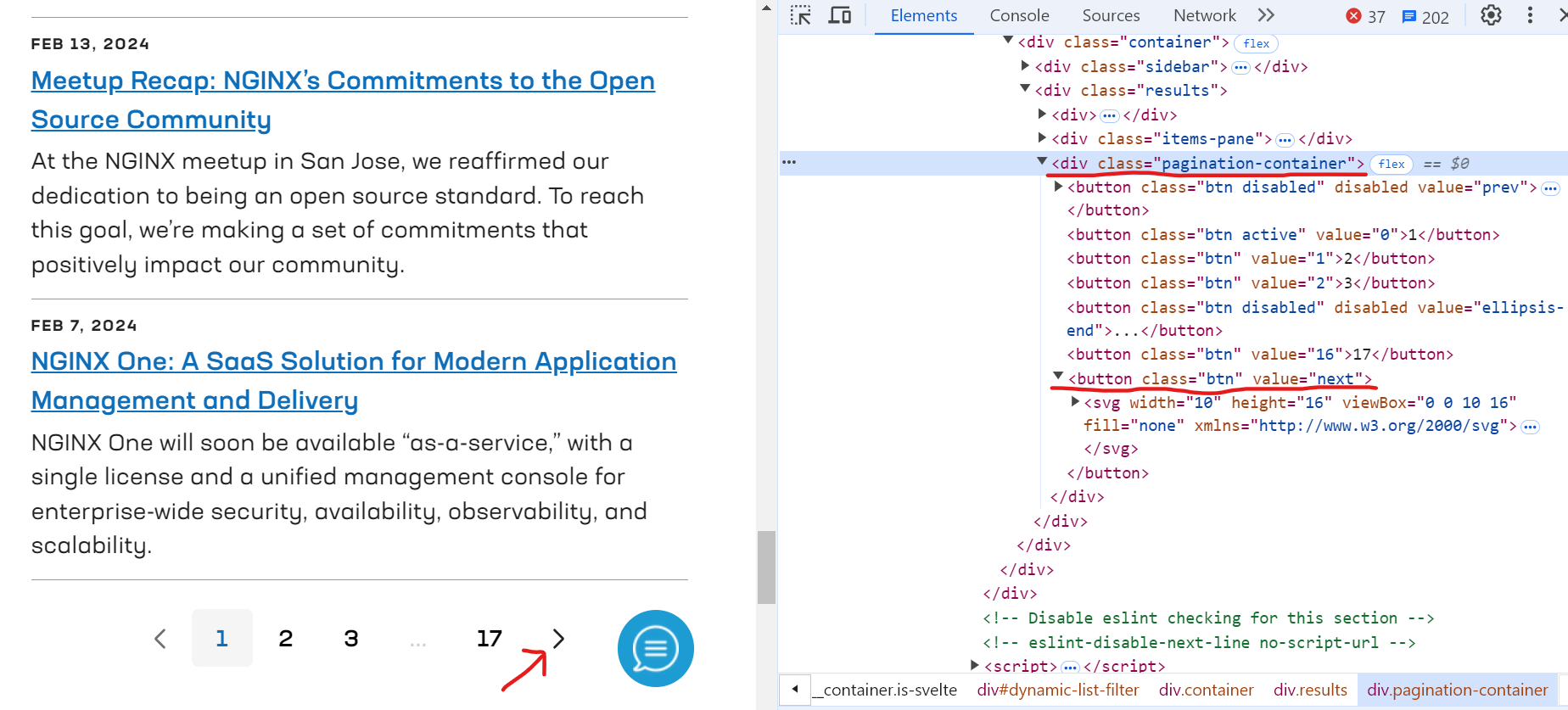
Here’s the code snippet:
async def paginate():
while True:
await page.wait_for_selector(".pagination-container")
next_button = await page.query_selector('button[value="next"]')
if not next_button or "disabled" in await next_button.get_attribute("class"):
break
await next_button.click()
await page.wait_for_load_state("networkidle")
await get_page_content()
Step 8: Closing the Browser
After all pages are scraped, close the browser to free up resources:
await browser.close()
Step 9: Running the Code
The main function initializes Playwright and calls the scrape_data function. Use an event loop to run main():
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
loop = asyncio.ProactorEventLoop()
loop.run_until_complete(main())
Complete Code
Here's the complete code:
import asyncio
from undetected_playwright.async_api import async_playwright, Playwright
# Function to scrape data
async def scrape_data(playwright: Playwright):
args = ["--disable-blink-features=AutomationControlled"]
browser = await playwright.chromium.launch(headless=True, args=args)
page = await browser.new_page()
await page.goto("https://www.f5.com/company/blog/nginx")
headline_counter = 0
# Function to extract data from the current page
async def get_page_content():
nonlocal headline_counter
results = await page.query_selector_all("li.result")
for result in results:
# Extracting headlines
headline = await result.query_selector(".result__headline a")
headline_text = await headline.inner_text() if headline else "N/A"
headline_counter += 1
print(f"{headline_counter}. {headline_text}")
await get_page_content()
# Function to handle pagination
async def paginate():
while True:
await page.wait_for_selector(".pagination-container")
# Selecting the 'next' button
next_button = await page.query_selector('button[value="next"]')
# Checking if the 'next' button is disabled
if not next_button or "disabled" in await next_button.get_attribute("class"):
break
await next_button.click() # Clicking the 'next' button
await page.wait_for_load_state("networkidle") # waiting for the page to load
await get_page_content()
await paginate()
# Closing the browser
await browser.close()
# Main function to run the scraper
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
# Entry point of the script
if __name__ == "__main__":
loop = asyncio.ProactorEventLoop()
loop.run_until_complete(main())
Once you execute the code, the headlines will appear in your console as shown below:
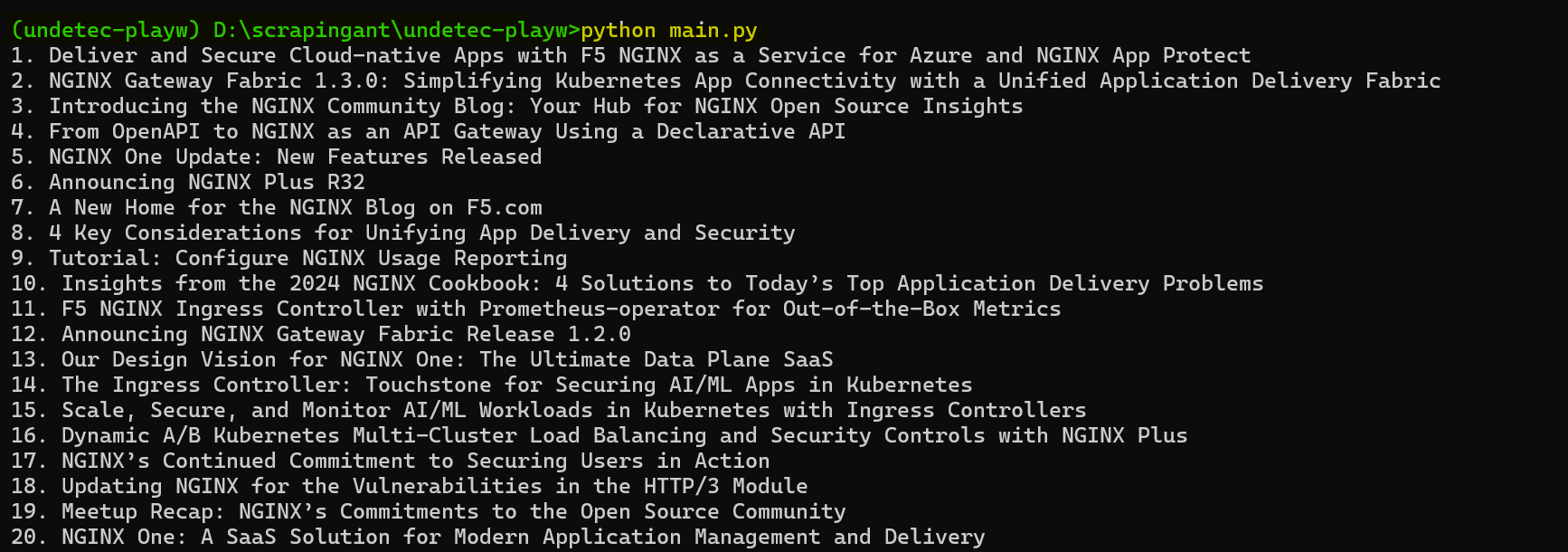
Great! You have successfully used undetected-playwright-python to avoid detection and effectively scrape data.
Quick Tests Revisited
Let's rerun the previous tests to verify if our Playwright setup is still avoiding detections.
Quick Test 1:
We tested the Playwright scraper on the Browserscan website. Here’s the code used:
import asyncio
from undetected_playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
args = []
args.append("--disable-blink-features=AutomationControlled")
browser = await playwright.chromium.launch(headless=False, args=args)
page = await browser.new_page()
await page.goto("https://www.browserscan.net/")
input("Press ENTER to exit:")
await browser.close()
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
loop = asyncio.ProactorEventLoop()
loop.run_until_complete(main())
The test results show that our Playwright scraper was not detected this time, which is promising.
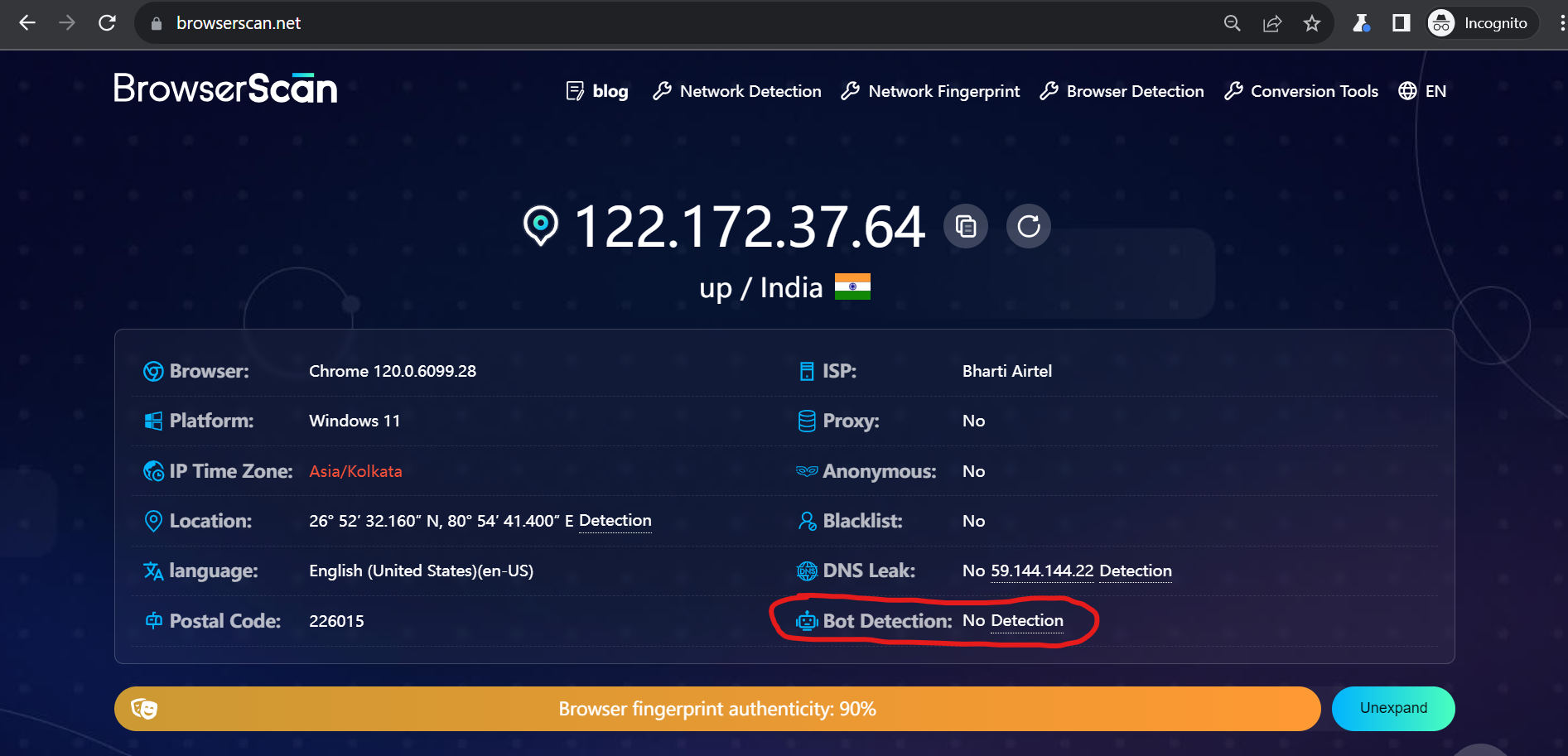
Quick Test 2:
Next, we tested the scraper on the CreepJS website. The site gave our session a Trust Score of 90.5% (A-), showing that it was highly trustworthy. This means our scraper performed well with few errors or signs of suspicious activity.
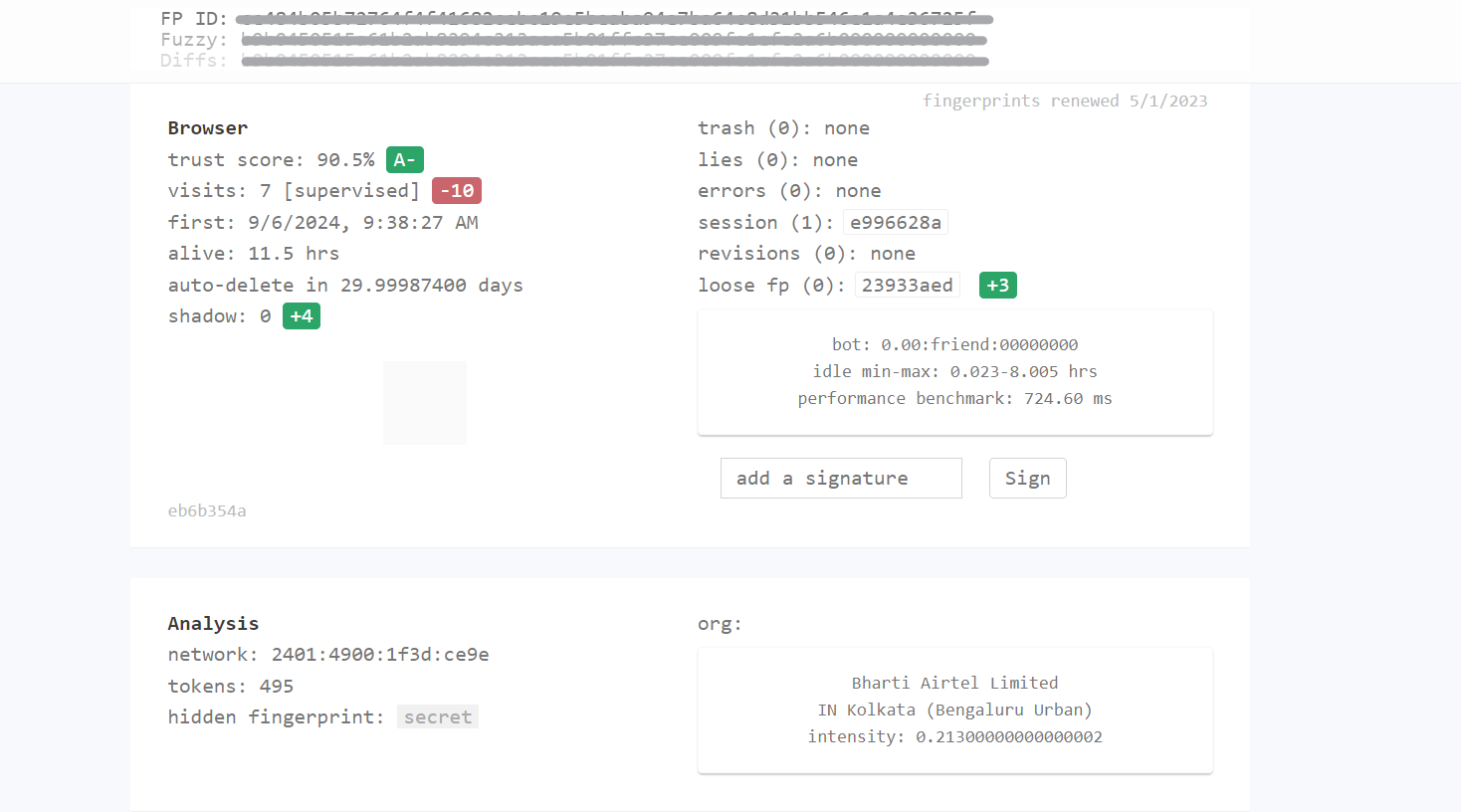
Both tests show that our Playwright setup is currently effective in avoiding detection.
Using a Web Scraping API
While traditional bypass methods can improve success rates, they are not foolproof, especially when dealing with advanced anti-bot systems. To reliably scrape any website, regardless of its anti-bot complexity, using a web scraping API like ScrapingAnt is highly effective. It automatically handles Chrome page rendering, low latency rotating proxies, and CAPTCHA avoidance, so you can focus on your scraping logic without worrying about getting blocked.
To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you.
Wrapping up
In this guide, we explored the challenges of bot detection for Playwrights and how to overcome them using the undetected-playwright library. Our tests with Browserscan and CreepJS show that the undetected-playwright setup reduces the detection.
Even if your Playwright script is highly sophisticated, you may still face challenges when dealing with advanced bot detection systems. This is where web scraping APIs like ScrapingAnt come in.
ScrapingAnt automatically handles Chrome page rendering, low latency rotating proxies, and CAPTCHA avoidance, allowing you to focus on your scraping logic without worrying about getting blocked. Get started today with 10,000 free credits 🚀