

Puppeteer is a powerful Node.js library that provides a high-level API for controlling browsers through the DevTools Protocol. It is commonly used for testing, web scraping, and automating repetitive browser tasks. However, Puppeteer's default settings can trigger bot detection systems, especially in headless mode.
That's where the Puppeteer Stealth plugin comes in. Puppeteer Stealth resolves these issues by modifying these settings to simulate human browsing behaviour.
Understanding Puppeteer Stealth
Puppeteer Stealth, also known as puppeteer-extra-plugin-stealth, is an extension of the Puppeteer library. This plugin is designed to enhance Puppeteer's capabilities by making it more difficult for websites to detect automated browsing activities.
As per the documentation:
It's probably impossible to prevent all ways to detect headless chromium, but it should be possible to make it so difficult that it becomes cost-prohibitive or triggers too many false-positives to be feasible.
Key Features
Puppeteer Stealth comes with a variety of features that help in evading detection:
- Evasion Modules: The plugin includes multiple evasion modules that tackle different aspects of browser fingerprinting. These modules can modify the user-agent string, and remove the
navigator.webdriverproperty, and adjust other browser settings to make the browser appear more human-like. - Customizable Evasion Strategies: Users can customize which evasion strategies to enable or disable, allowing for a tailored approach depending on the target website's anti-scraping measures. This flexibility is crucial for adapting to different levels of bot detection.
- Integration with Puppeteer Extra: Puppeteer Stealth is built on top of Puppeteer Extra, a lightweight wrapper around Puppeteer that supports plugins. This integration allows for easy addition of other plugins, such as those for solving CAPTCHAs or managing cookies.
Built-in Evasion Modules
Puppeteer Stealth uses various built-in evasion modules to address specific bot detection techniques. Here are some of the key modules included:
- User-Agent Override: This module updates the default user agent string used by Puppeteer, which includes "HeadlessChrome", a clear indicator of automated browsing.
- Navigator.webdriver Property: One common method for detecting bots is checking the
navigator.webdriverproperty. In a headless browser, this property is set totrue, indicating automation. The Puppeteer Stealth removes this property. - Chrome App and CSI: Regular browsers have
chrome.appandchrome.csiobjects, but headless browsers usually don't. This module adds those objects, making the browser seem less like a bot. - Accept-Language Header: In headless mode, Puppeteer does not set the
Accept-Languageheader. This can be a red flag for detection systems. The User-Agent Override module addresses this by setting theAccept-Languageheader to match the user-agent string.
For a full list of all the evasion modules, you can visit Evasion Modules.
Installing Puppeteer Stealth
To get started with Puppeteer Stealth, you need to install both Puppeteer Extra and the Stealth plugin.
npm install puppeteer-extra puppeteer-extra-plugin-stealth
Don't forget to have Puppeteer installed! If not already installed, you can add it with:
npm install puppeteer
Configuring Puppeteer with Stealth Plugin
After installing, you need to set up Puppeteer to use the Stealth plugin. Here's how you can do it:
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
// Apply the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://nowsecure.nl/');
await browser.close();
})();
In the code, the use() method is used to add the Stealth plugin to Puppeteer.
The result should look something like this:
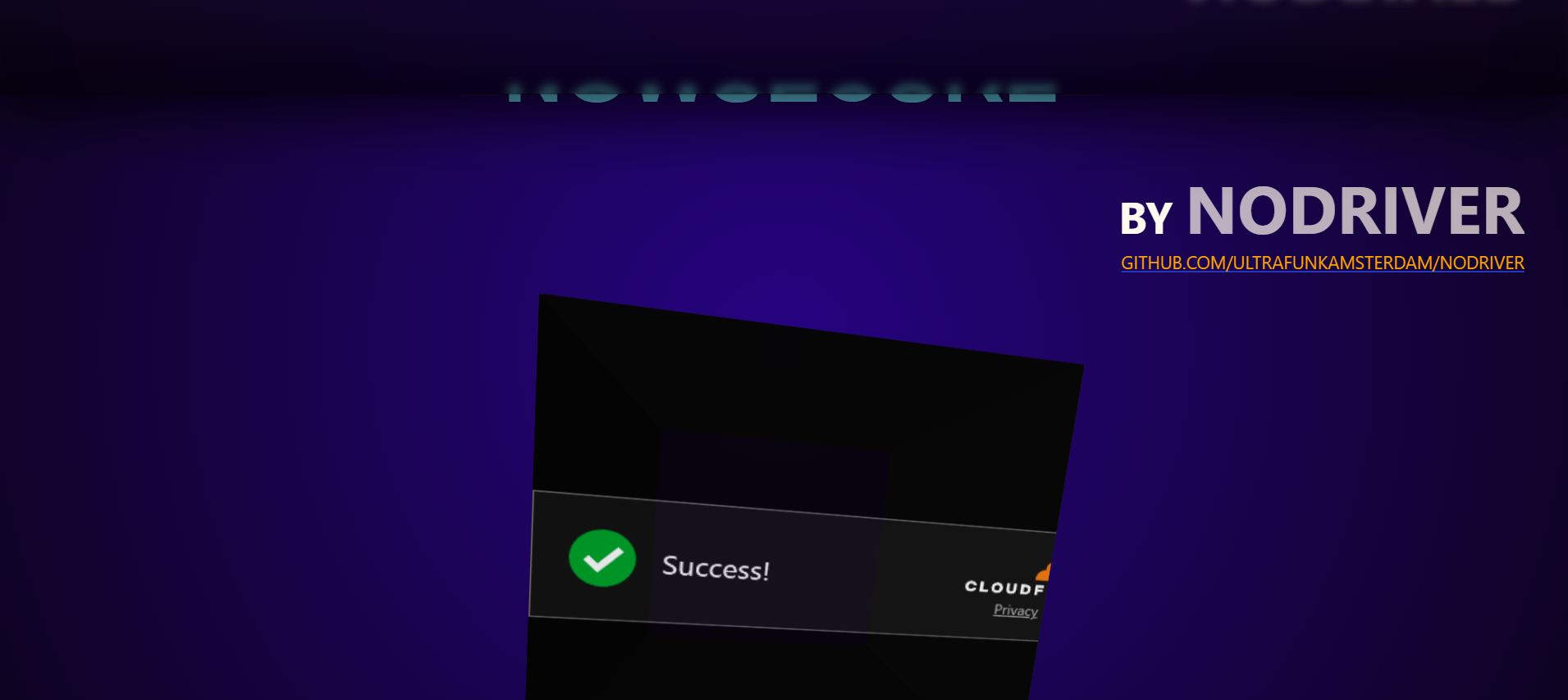
Great Job! Detection successfully bypassed.
Error Handling
Proper error handling is important to keep your scraping operations running smoothly. One effective way to do this is to use retry mechanisms for network requests to handle temporary issues. Here’s an example of adding retry logic in Puppeteer:
import puppeteer from 'puppeteer-extra';
import StealthPlugin from 'puppeteer-extra-plugin-stealth';
puppeteer.use(StealthPlugin());
async function scrape(url, retries = 3) {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
try {
for (let attempt = 0; attempt < retries; attempt++) {
try {
await page.goto(url);
const data = await page.evaluate(() => document.title);
return data;
} catch (error) {
console.error(`Attempt ${attempt + 1} failed: ${error.message}`);
}
}
} finally {
await browser.close();
}
throw new Error('All attempts to scrape failed'); // Throw error after all retries
}
async function main() {
try {
const data = await scrape('https://nowsecure.nl/');
console.log(data);
} catch (error) {
console.error('Failed to scrape:', error);
}
}
main();
In this code, the scrape function tries to fetch the page up to three times. If all attempts fail, it throws an error showing that the scrape was unsuccessful.
Puppeteer Extra Plugins
Here are some other Puppeteer Extra plugins aside from Puppeteer Stealth:
- puppeteer-extra-plugin-proxy: This plugin allows you to route your requests through proxies to avoid rate limiting in web scraping.
- puppeteer-Extra-Plugin-Recaptcha: This plugin is designed to handle captchas during web scraping tasks. It integrates with captcha-solving services to automatically solve captchas encountered on target websites.
- puppeteer-Extra-Plugin-Adblocker: This plugin is used to block ads during web scraping tasks.
- puppeteer-extra-plugin-anonymize-ua: This plugin anonymizes the user-agent on all pages and supports dynamic replacing, so the browser version remains intact and recent.
Using a Web Scraping API
Playwright Stealth is a powerful web scraping plugin, but it does have its limitations, as outlined in the official documentation. There are instances where it can still be detected, meaning it's not entirely reliable when attempting to bypass advanced anti-bot measures.
This leads to the question: what is the ultimate solution?
To reliably scrape any website, regardless of its anti-bot complexity, using a web scraping API like ScrapingAnt is highly effective. It automatically handles Chrome page rendering, low latency rotating proxies, and CAPTCHA avoidance, so you can focus on your scraping logic without worrying about getting blocked. To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you. Get started today with 10,000 free credits 🚀
Wrapping up
Puppeteer Stealth is a powerful tool designed to minimize the likelihood of detection. Its advanced evasion techniques significantly reduce the risk of your scraping activities being flagged or blocked. However, as anti-bot technologies continue to advance, dealing with advanced anti-bot systems can be challenging. In such cases, using a web scraping API like ScrapingAnt can be highly effective.