
If you are looking to scrape data from Twitter then look no further. As you have come to the perfect, my friend. Here, I shall teach you how to scrape Twitter easily and effortlessly. So let's begin!
Why Do We Scrape or Extract Data?
No matter what field you work in, data is an absolute must. Web scraping and data extraction have become indispensable in many industries, including advertising, business, e-commerce, finance, and many more.
We're only human, so of course, we make mistakes and have constraints. The value of data mining and web scraping becomes apparent here. In particular, when dealing with large quantities of data.
Data sets must be collected in a way that is efficient in terms of time and, more importantly, error-free. Web and data scraping, which is fully automated and extremely quick, and dependable, solves all these issues.
Why Do We Use Bots and Scrapers?
Using bots and scrapers to extract information from various sources is arguably the best method. The justification for this is:
Scraping data manually is both time-consuming and inefficient.
When working with large amounts of data, it is nearly impossible to manually scrape massive quantities of information.
Bots and scrapers are always dependable and less likely to make mistakes when compared to humans and manual extraction.
It requires less human input as it is automated and easy to use.
Is Twitter Scraping Legal?
The legality of scraping Twitter or even web scraping in general is undoubtedly a widely debated topic. The truth of the matter is that its legality lies in a grey area, meaning it can be considered legal or illegal based on:
- How it was extracted?
- Use of the extracted data
To make sure you are scraping legally, all you need to do is maintain scraping best practices and avoid violations. Here are a few things you need to maintain:
- GDOR, CCPA, and CFAA acts
- Scraping with permission
- Abiding by copyright laws
- Avoid being an inconvenience and nuisance to the sources
- Avoiding scraping personal data
- Refraining from misuse of extracted data
- Keeping extracted data secured.
For more details please visit this link.
How to Scrape Twitter? Here's How:
Just follow these steps to scrape Twitter with Python easily:
Step 1: Installation:
You need to install the following:
- The latest version of Python.
- An IDE, I used Visual Code Studio.
After that, you need to set up dependencies.
Dependencies:
For Windows:
Simply open up a Python Powershell by pressing SHIFT + RIGHT CLICK and select Open PowerShell Window here.
For Mac:
Open up a terminal. You can do this by pressing CMD + SPACE and typing in Terminal.
Then type the following command:
pip install pathlib
pip install pandas
pip install snscrape
Simply type these lines of code one by one and hit Enter and wait for the program to run and install all the necessary elements and components.
Step 2: Coding:
Simply copy this code into your IDE or create a file and save it as "MyTwitter Scraper.py" inside your VE. You can even paste this onto a normal text file but make sure to save it with .py in the end as that will convert it into an executable Python file.
import os
import pathlib
import pandas as pd
DATE_START = input("Enter the start date in YYYY-MM-DD format i.e 2022-10-25: \n")
HASHTAG = input("Enter the hashtag: \n")
FILENAME = input("Enter the output filename: \n")
MAX_LIMIT = input("Enter the max limit:\n")
def sns_scrape():
os.system(f'snscrape --jsonl --progress --max-results {MAX_LIMIT} --since {DATE_START} twitter-hashtag "{HASHTAG}" > {FILENAME}.json')
if __name__ == "__main__":
sns_scrape()
filePath = FILENAME+'.json'
csvPath = FILENAME+'.csv'
print(filePath)
print(csvPath)
df = pd.read_json(filePath,lines=True)
df.to_csv(csvPath)
exit = input("Enter anything to exit")
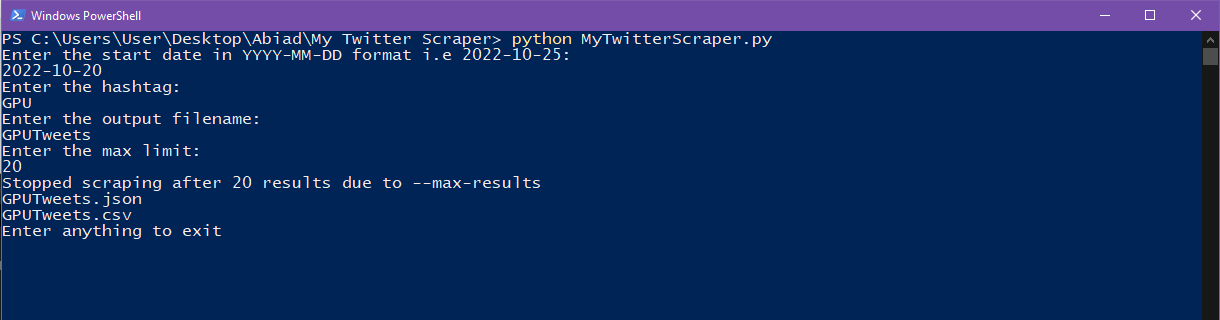
Now start a Powershell (or your preferable shell) in the Python script folder again, to scrape simply type in this command:
python MytwitterScraper.py
And then press Enter, and it will prompt you to fill in the date, hashtag, output file name, and no. of tweets. Simply input the info and hit Enter each time. It should look like this:
As a result you'll be able to observe the following json and csv files in your folder:
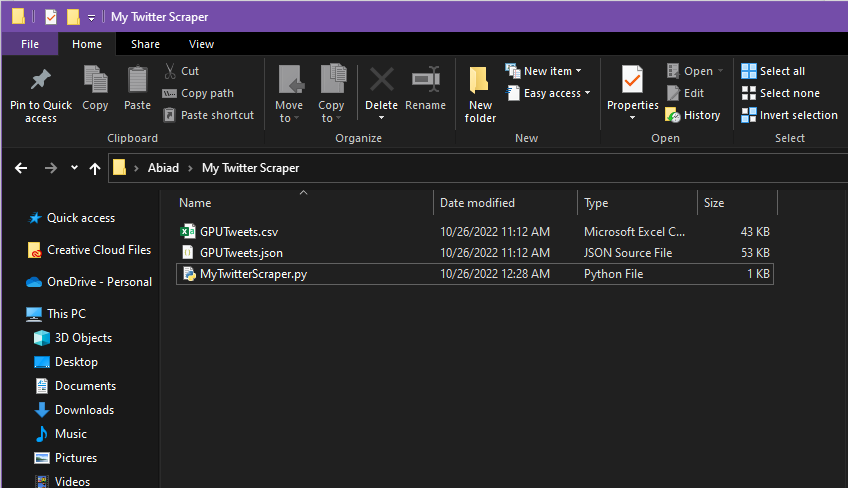
With the similar look for the csv file:
And done! It was that easy and simple!
Step 3: How Does It Work? (Optional)
The code is pretty simple and straightforward. It's just a few lines of code. Let's break it down.
import os
import pathlib
import pandas as pd
These are the libraries we need to import to make the code work. os is used to run the command in the shell. pathlib is used to create a path to the file. pandas is used to convert the json file into a csv file.
DATE_START = input("Enter the start date in YYYY-MM-DD format i.e 2022-10-25: \n")
HASHTAG = input("Enter the hashtag: \n")
FILENAME = input("Enter the output filename: \n")
MAX_LIMIT = input("Enter the max limit:\n")
These are the variables we need to input. DATE_START is the date from which you want to scrape the tweets. HASHTAG is the hashtag you want to scrape. FILENAME is the name of the output file. MAX_LIMIT is the maximum number of tweets you want to scrape.
def sns_scrape():
os.system(f'snscrape --jsonl --progress --max-results {MAX_LIMIT} --since {DATE_START} twitter-hashtag "{HASHTAG}" > {FILENAME}.json')
This is the function that will scrape the tweets. os.system is used to run the command in the shell. snscrape is the command that will scrape the tweets. --jsonl is used to convert the output into a json file. --progress is used to show the progress of the scraping. --max-results is used to set the maximum number of tweets to scrape. --since is used to set the date from which you want to scrape the tweets
I used a Python package called snscrape to scrape the tweets. It's a very powerful package that can scrape tweets, Facebook posts, Instagram posts, and even Reddit posts. It's very easy to use and has a lot of features. You can check it out here.
It's also possible to use this package from Python code, but, unfortunately, it's not documented, so I used the command line to scrape the tweets.
if __name__ == "__main__":
sns_scrape()
filePath = FILENAME+'.json'
csvPath = FILENAME+'.csv'
print(filePath)
print(csvPath)
df = pd.read_json(filePath,lines=True)
df.to_csv(csvPath)
exit = input("Enter anything to exit")
This is the main function. It will run the sns_scrape function and then convert the json file into a csv file. It will also prompt you to exit the program.
Step 4: Conclusion:
That's it! You've successfully scraped the tweets. You can now use the csv file for your analysis. You can also use the json file if you prefer json structure to work with.
I used Python script to automate json to csv conversion and to make the process easier. You can also do it manually by using the command line. It's very easy to do. Simply type in the following command:
snscrape --jsonl --progress --max-results 100 --since 2021-10-25 twitter-hashtag "#python" > python.json
So, actually, no need to run the separate Python script. Still, you should have Python installed and snscrape package installed to run the command.
As the alternative, you can perform prompt automation and result saving using any of your favourite programming languages with the help of snscrape package.
I'd suggest read more about this package capabilities and features, as it allows you to scrape a lot of different social media platforms.
Why Do People Scrape Twitter?
Here are a few instances of why people want to scrape Twitter:
Behavior and Feedback Analysis
Twitter offers excellent data analysis methods, especially in the customer or client analysis department. It is a good sign, for instance, if clients describe positive thoughts regarding a product or service by using adjectives such as"great," "glad," "content," "happy," "super," etc. On the other hand, when users voice unfavorable thoughts about a product, then it is a hint for that brand to take action. A person's feelings can be used to develop and improve service to customers and even help influence improvements to products and services.
Branding
On Twitter, it has been demonstrated that negative news spreads much more rapidly than positive news does. Analyzing hashtags and evaluative remarks enables firms to swiftly debunk any phony bad articles or promptly reply to actual negative stories in order to limit the amount of harm done to their company's reputation. Monitoring brands and products not only helps businesses enhance their services and goods but also provides them with immediate information on recurrent problems.
Competitor Analysis
Every one of these strategies can be utilized when dealing with competitors. It is essential to analyze the thoughts and emotions regarding any product or service or to analyze competitors and their states on how they are doing currently, in order to formulate a strategic response. Monitoring also benefits quality assurance and thus reduces costs and expenses.
Customer Service
Twitter can be a rich source of information regarding customers. Businesses are able to study the interactions that surround them by conducting surveys of mentions of their products or brands. Twitter is now commonly utilized for customer support, and users often tweet to and tag companies and brands whenever they write anything about a product or service. The abovementioned information can be extracted and examined in order to identify recurring problematic instances. This applies to positive interactions with customers, whether they be experiences or talks.
Marketing
The data from Twitter can be scraped in order to help identify new influential individuals. You can observe what is trending currently by searching for hashtags and tweets that are related to your industry. Because of this, possibilities to communicate with influential people on Twitter or any other platform have arisen. In addition, Twitter data can assist you in discovering the hashtag words or phrases that influencers are utilizing, allowing you to mimic their use and so increase your chances of being found in hashtag trends that are similar to theirs.
Conclusion
In this article, we learned how to scrape tweets using Python. We used the snscrape package to scrape the tweets. We also learned how to convert the json file into a csv file. We also learned why people scrape Twitter. I hope I was able to help you out and provide you with the solution to your needs.
I highly recommend you using proxies while Twitter scraping, as you might get banned if you scrape too many tweets. You can check out my article on how to test proxies.
Happy Web Scraping and don't forget to check out my other articles on web scraping and proxies.