

In this article, we will learn how to create a simple e-commerce search API with multiple platform support: eBay and Amazon. AutoScraper and FastAPi provide the ability to create a powerful JSON API for the date. With Playwright's help, we'll extend our scraper and avoid blocking by using ScrapingAnt's web scraping API.
Let's satisfy the requirements
To complete the whole tutorial we'll need the following libraries:
- FastAPI - to implement the API
- Uvicorn - to serve the API
- AutoScraper - to parse data into structured format
- Playwright or ScrapingAnt API client - for blocking avoidance and web scraping at scale
To install all the requirements via pip just run the following command (Python 3.7+ required):
pip install fastapi 'uvicorn[standard]' autoscraper playwright scrapingant-client
playwright install
Not all the described libraries are required for a complete project, but I'd suggest installing them to try different ways of data extraction.
Scrape one page, and you'll scrape them all
Let's start from the most interesting part - creating a smart scraper to fetch data from Amazon's search result page. For a simple case, we'll use the title, price and product link as a required data for extraction. To generate a product link for Amazon's product we'll need to get a unique product id like B077XTPWZ5.
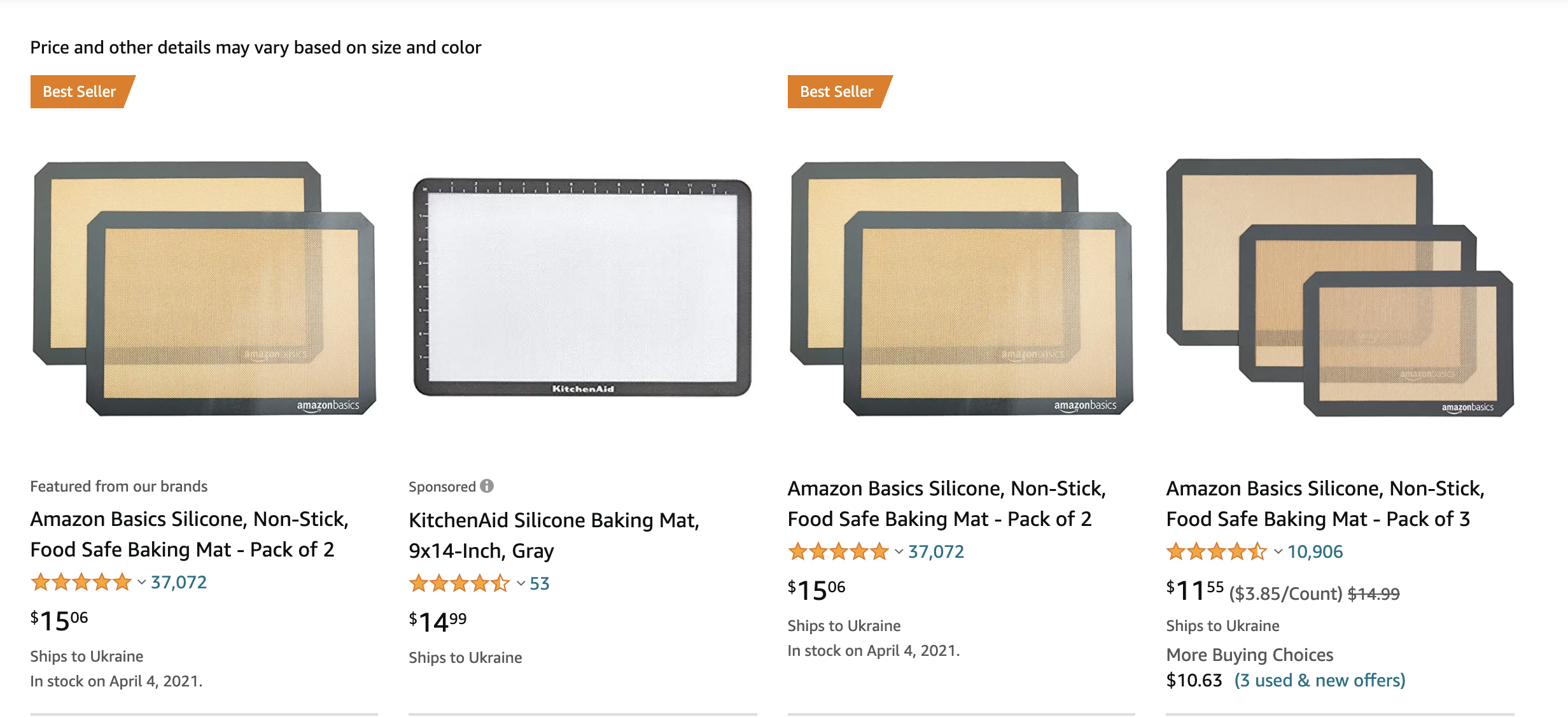
Using AutoScraper, it would be easily done by just providing some sample data:
from autoscraper import AutoScraper
url = 'https://www.amazon.com/s?k=baking+mat'
wanted_dict = {
'title': [
'Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 2',
'Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3',
],
'price': ['$15.06', '$11.55'],
'url': ['B0725GYNG6', 'B077XTPWZ5']
}
scraper = AutoScraper()
scraper.build(url=url, wanted_dict=wanted_dict)
# results grouped per rule to we'll know which one to use
scraper.get_result_similar(url, grouped=True)
The code above tells us how to apply several samples when the structure of items on search result pages is different, and we want the scraper to learn them all, which is redundant for the current case and added to show this cool feature.
If you want to copy and run this code, you may need to update the wanted_dict with your values.
From the output, we’ll know which rule corresponds to which data:
{
"rule_iqkj": ["Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 2", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 4", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat, Macaron - Pack of 2", "Amazon Basics Anti-Fatigue Mat Marbleized Composite Mat 1/2' Thick 2X3 Black/Gray/White"],
"rule_0emm": ["Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 2", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 4", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat, Macaron - Pack of 2", "Amazon Basics Anti-Fatigue Mat Marbleized Composite Mat 1/2"],
"rule_91nj": ["Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 2", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 4", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat, Macaron - Pack of 2", "Amazon Basics Anti-Fatigue Mat Marbleized Composite Mat 1/2' Thick 2X3 Black/Gray/White"],
"rule_pkc7": ["Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 2", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 4", "Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat, Macaron - Pack of 2", "Amazon Basics Anti-Fatigue Mat Marbleized Composite Mat 1/2"],
"rule_vv2c": ["Amazon Basics Silicone, Non-Stick, Food Safe Baking Mat - Pack of 3", "Silpat Premium Non-Stick Silicone Baking Mat, Half Sheet Size, 11-5/8 x 16-1/2"],
"rule_o7dc": ["$15.06", "$11.55", "$14.99", "$25.87", "$12.05", "$13.99", "$45.49"],
"rule_y9sp": ["$15.06", "$11.55", "$14.99", "$25.87", "$12.05", "$13.99", "$45.49"],
"rule_4psi": ["$15.06", "$11.55", "$14.99", "$12.05", "$13.99", "$24.99", "$14.99", "$9.19", "$11.50", "$25.87", "$19.99", "$22.25", "$10.36", "$13.99", "$17.97", "$13.99", "$15.47", "$17.00", "$7.99", "$23.28", "$9.99", "$24.99", "$10.99", "$3.49", "$4.99", "$6.99", "$9.99", "$15.99", "$19.99", "$8.99", "$14.99", "$14.99", "$16.92", "$8.26", "$41.27", "$30.00", "$27.66", "$17.95", "$17.90"],
"rule_t1vk": ["$15.06", "$11.55", "$14.99", "$12.05", "$13.99", "$24.99", "$14.99", "$9.19", "$11.50", "$25.87", "$19.99", "$22.25", "$10.36", "$13.99", "$17.97", "$13.99", "$15.47", "$17.00", "$7.99", "$23.28", "$9.99", "$24.99", "$10.99", "$3.49", "$4.99", "$6.99", "$9.99", "$15.99", "$19.99", "$8.99", "$14.99", "$14.99", "$16.92", "$8.26", "$41.27", "$30.00", "$27.66", "$17.95", "$17.90"],
"rule_vjnv": ["B0725GYNG6", "B077XTPWZ5", "B07DZVRJBZ", "B077XR38W3", "B07Q1CJSWL"],
"rule_zho2": ["B0725GYNG6"],
"rule_3h0m": ["B0725GYNG6", "B077XTPWZ5", "B07DZVRJBZ", "B077XR38W3", "B07Q1CJSWL"],
"rule_h12x": ["B077XTPWZ5", "B00008T960"],
"rule_he5c": ["B077XTPWZ5"]
}
After analyzing the output, let’s keep only desired rules, remove the rest, and save our model:
scraper.keep_rules(['rule_iqkj', 'rule_7wqn', 'rule_vjnv', 'rule_y9sp'])
# Give it a file path
scraper.save('amazon-search')
Let's do the same trick for eBay:
from autoscraper import AutoScraper
url = 'https://www.ebay.com/sch/i.html?_nkw=baking+mat'
wanted_list = ['Durable Silicone Baking Mat Non-Stick Pastry Cookie Sheet Oven Baking Mat Liner', '$2.15', 'https://www.ebay.com/itm/Durable-Silicone-Baking-Mat-Non-Stick-Pastry-Cookie-Sheet-Oven-Baking-Mat-Liner/202362695368?hash=item2f1dc1aec8:g:S3UAAOSwwpdW62sK']
scraper = AutoScraper()
scraper.build(url=url, wanted_list=wanted_list)
scraper.get_result_similar(url, grouped=True)
... and the execution hangs.
What is the reason? Why it not worked?
AutoScraper is a good tool for automatic intelligent parsing. Still, it does not have capabilities for proper data extraction from the page, so the URL's direct data extraction can not work for some sites.
Let's try the workaround for the learning phase only: save the required page as HTML via the browser and then open via Python to pass the data into AutoScraper:
from autoscraper import AutoScraper
from pathlib import Path
# page content from https://www.ebay.com/sch/i.html?_nkw=baking+mat saved from the browser
html = Path('baking_mat_ebay.html').read_text()
wanted_list = ['Durable Silicone Baking Mat Non-Stick Pastry Cookie Sheet Oven Baking Mat Liner', '$2.14', 'https://www.ebay.com/itm/Durable-Silicone-Baking-Mat-Non-Stick-Pastry-Cookie-Sheet-Oven-Baking-Mat-Liner/202362695368?hash=item2f1dc1aec8:g:S3UAAOSwwpdW62sK']
scraper = AutoScraper()
scraper.build(html=html, wanted_list=wanted_list)
scraper.get_result_similar(html=html, grouped=True)
scraper.set_rule_aliases({'rule_9otk': 'title', 'rule_7n5a': 'price', 'rule_buz1': 'url'})
// No rules will be cleaned this time, all of them works fine
# Give it a file path
scraper.save('ebay-search')
How to extract data and avoid anti-scraping techniques? Let's try out two different approaches:
Playwright
Playwright is a high-level API over headless Chrome, Firefox and Webkit browser. It means that you can automate the action that we made above (open the page's HTML), and this action will not trigger the website's anti-scraping mechanism. Let's create a function that does content extraction:
from playwright.sync_api import sync_playwright
def get_webpage_content_playwright(url):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
content = page.content()
browser.close()
return content
This function allows us to get the page's HTML content without being blocked and detected as a bot.
Also, we'll need to apply rotating proxies to avoid rate-limiting for the web scraping at scale. Check out how to use a proxy in Playwright.
Let's check out the pros and cons of using Playwright for web scraping:
Pros:
- On-premise or cloud solution with no third party API
- Full browser control
- Customisable proxy pool
- Community support
Cons:
- Low scalability
- High proxy prices
- Complicated maintenance
- High expenses for infrastructure to run CPU intense task
ScrapingAnt API
ScrapingAnt web scraping API is a web interface for performing data extraction at a scale that already uses headless browsers and rotating proxies inside. Only one action is needed - execute an API request with a target URL. Let's create the same function with using ScrapingAnt API:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token='<YOUR-SCRAPINGANT-API-TOKEN>')
def get_webpage_content_scrapingant(url):
return client.general_request(url).content
To get you API token, please, visit Login page to authorize in ScrapingAnt User panel. It's free.
Pros:
- Simple usage
- Always reproducible results
- Low maintenance and usage price
- Large proxy pool
- High data extraction success rate
Cons:
- Third-party API usage
- Paid when scraping web pages at scale
Learning phase notes
Model creation should be implemented in exactly the same way you're going to use for other pages scraping. If you're planning to use AutoScraper with url param - you should also create the model with passing url param. The different browsers may create different layouts, so a Playwright or a desktop Chrome model can not parse HTML retrieved with a direct URL propagation or content retrieved via ScrapingAnt web scraping API.
To save HTML for learning, you can use the following snippets:
Playwright
from pathlib import Path
from playwright.sync_api import sync_playwright
url = 'https://www.ebay.com/sch/i.html?_nkw=baking+mat'
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
Path('baking_mat_ebay.html').write_text(page.content())
browser.close()
ScrapingAnt
from pathlib import Path
from scrapingant_client import ScrapingAntClient
url = 'https://www.ebay.com/sch/i.html?_nkw=baking+mat'
client = ScrapingAntClient(token='<YOUR-SCRAPINGANT-API-TOKEN>')
html = client.general_request(url=url).content
Path('baking_mat_ebay.html').write_text(html)
Create your own API
It's time to glue-up everything together and create our e-commerce API based on Amazon and eBay. The final code contains both data extraction functions, so you'll be able to modify and use your favorite:
from autoscraper import AutoScraper
from fastapi import FastAPI
from scrapingant_client import ScrapingAntClient
from typing import Optional
from playwright.sync_api import sync_playwright
ebay_scraper = AutoScraper()
amazon_scraper = AutoScraper()
ebay_scraper.load('ebay-search')
amazon_scraper.load('amazon-search')
client = ScrapingAntClient(token='<YOUR-SCRAPINGANT-API-TOKEN>')
app = FastAPI()
def get_ebay_result(search_query):
url = 'https://www.ebay.com/sch/i.html?_nkw=%s' % search_query
html = get_webpage_content_scrapingant(url)
result = ebay_scraper.get_result_similar(html=html, group_by_alias=True)
return _aggregate_result(result)
def get_amazon_result(search_query):
url = 'https://www.amazon.com/s?k=%s' % search_query
html = get_webpage_content_scrapingant(url)
result = amazon_scraper.get_result_similar(html=html, group_by_alias=True)
result['url'] = [f'https://www.amazon.com/dp/{i}' for i in result['url']]
return _aggregate_result(result)
def get_webpage_content_scrapingant(url):
return client.general_request(url).content
def get_webpage_content_playwright(url):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
content = page.content()
browser.close()
return content
def _aggregate_result(result):
"""
:param result {
'title': ['name1', 'name2']
'url': ['url1', 'url2']
'price': ['price1', 'price2']
}
:returns [
{'title': 'name1', 'url': 'url1', 'price': 'price1'},
{'title': 'name2', 'url': 'url2', 'price': 'price2'},
]
"""
final_result = []
items_count = len(result['title'])
for i in range(items_count):
final_result.append({alias: result[alias][i] for alias in result})
return final_result
@app.get("/")
def search_api(q: Optional[str] = None):
return dict(result=get_ebay_result(q) + get_amazon_result(q))
Execute the following command to run the API server:
uvicorn main:app --reload
By running this code, the API server will be up listening on port 8080. So let’s test our API by opening http://127.0.0.1:8080/?q=baking in our browser:
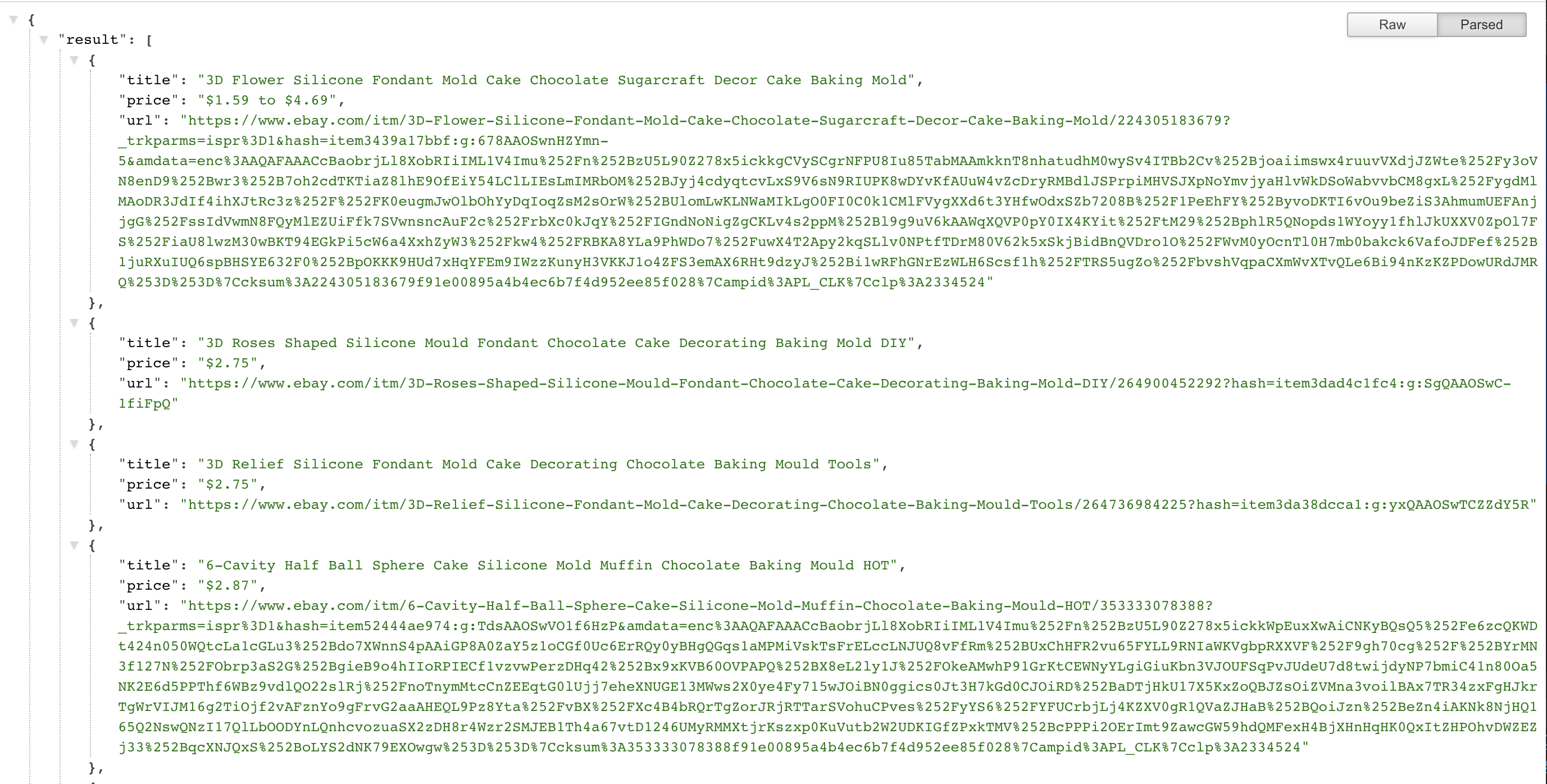
And finally, we're having our own custom multi-sourced e-commerce API. Just replace baking in the URL with your desired search query to get its results.
Conclusion
This tutorial is intended for personal and educational use. I hope this article is useful and helps to grab all the provided code snippets to a fully-functional and production grade application.
I'd recommend following the links below to extend your knowledge and have a deep dive into the project parts:
- AutoScraper Github
- AutoScraper Examples
- Introducing AutoScraper: A Smart, Fast and Lightweight Web Scraper For Python
- AutoScraper and Flask: Create an API From Any Website in Less Than 5 Minutes
- FastAPI Documentation
- Playwright Documentation
- ScrapingAnt Documentation
Happy web scraping, and don't forget to check websites policies regarding the scraping bots 😉