

Imagine if you could describe the data you need in simple English, and AI takes care of the entire extraction and processing, whether from websites or local documents like PDFs, JSON, Markdown, and more. Even better, what if AI could summarize the data into an audio file or find the most relevant Google search results for your query—all at no cost or for just a few cents? This powerful functionality is provided by ScrapeGraphAI, an open-source AI-based Python scraper!
In this 2-part series on ScrapeGraphAI, Part 1 will walk you through setting up and running ScrapeGraphAI with Ollama. We'll explore its scraping pipelines and show how to extract data from local documents such as JSON and HTML files.
By the end of the series, you will have a fully functional LLM-powered Glassdoor job scraper ready to collect data on companies that are hiring.
Here’s a preview of the AI scraper you’ll build by the end of this series.

All you need to do is provide the job URLs and specify the data you want to scrape, and the app will handle the rest as shown below:
What is ScrapeGraphAI?
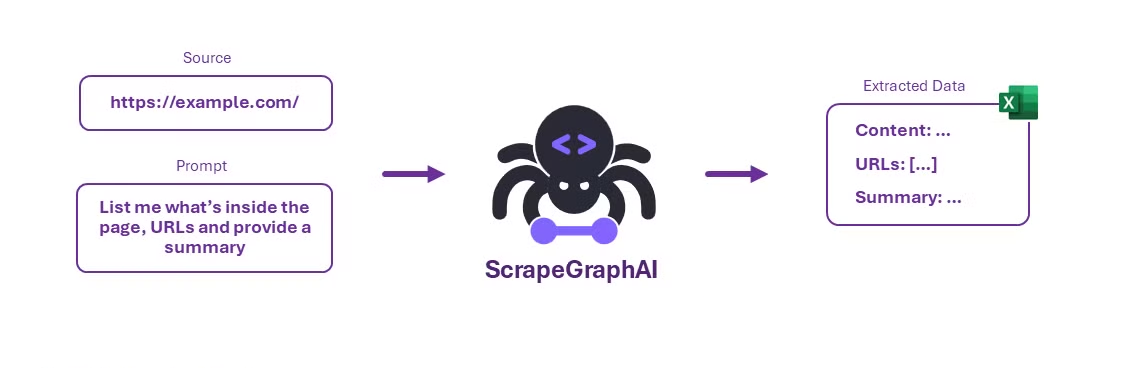
ScrapeGraphAI is an open-source Python library that transforms web scraping by using Large Language Models (LLMs) and graph logic to build scraping pipelines for websites and local documents (e.g., XML, HTML, JSON, Markdown). So, how does ScrapeGraphAI differ from traditional web scraping approach?
Unlike traditional scraping scripts that often require manual configuration and struggle with evolving website structures, ScrapeGraphAI automatically adapts to changes like new designs or layouts. This reduces the frequent need for developers to rewrite scripts, ensuring that scrapers remain functional even as websites evolve.
Key Features
- Simple extraction process: You only need to specify the data you want to extract, and ScrapeGraphAI takes care of the rest, providing a more flexible and low-maintenance solution compared to traditional scraping tools.
- Adaptive to website changes: Unlike traditional tools that rely on fixed patterns and manual configurations, ScrapeGraphAI uses LLMs to adapt to website structure changes, minimizing the need for constant developer updates.
- Broad LLM support: ScrapeGraphAI integrates with various LLMs, including GPT, Gemini, Groq, Azure, and Hugging Face, as well as local models that can run on your machine with Ollama.
Scraping Pipelines
ScrapeGraphAI provides several scraping pipelines to extract information from websites or local files, generate Python scripts, or even create audio files. Let’s explore each one:
- SmartScraperGraph: One-page scraper that only requires a user prompt and a URL (or local file).
- SearchGraph: Multi-page scraper that extracts data from search engines.
- SpeechGraph: Text-to-speech pipeline that generates a response but also creates an audio file.
- ScriptCreatorGraph: Creates a Python script for scraping websites.
- ScriptCreatorMultiGraph: Like ScriptCreatorGraph, but supports multiple data sources.
- SmartScraperMultiGraph: Similar to SmartScraperGraph but handles multiple sources.
- OmniScraperGraph: Similar to SmartScraperGraph but also scrape images and describe them.
- OmniSearchGraph: Similar to SearchGraph but also scrape images and describe them.
Installing Ollama
Install the Ollama on your local machine to use local models like Llama3. Follow the installation instructions carefully to set it up correctly.
Setting Up Model
Let’s say we want to use llama3 as the chat model and nomic-embed-text as the embedding model. We first need to pull them from Ollama using:
ollama pull llama3
ollama pull nomic-embed-text
Note: This process is resource-intensive and may take some time to complete based on your system's capabilities. Please be patient while the process finishes!
Once the models are downloaded, start the chat model with:
ollama run llama3
If everything is set up correctly, you'll see a simple interface for interacting with the model. For example, you can ask, "How are you?”

If you get a response, the model is working correctly. You can close the prompt by typing /bye or pressing Ctrl + D.
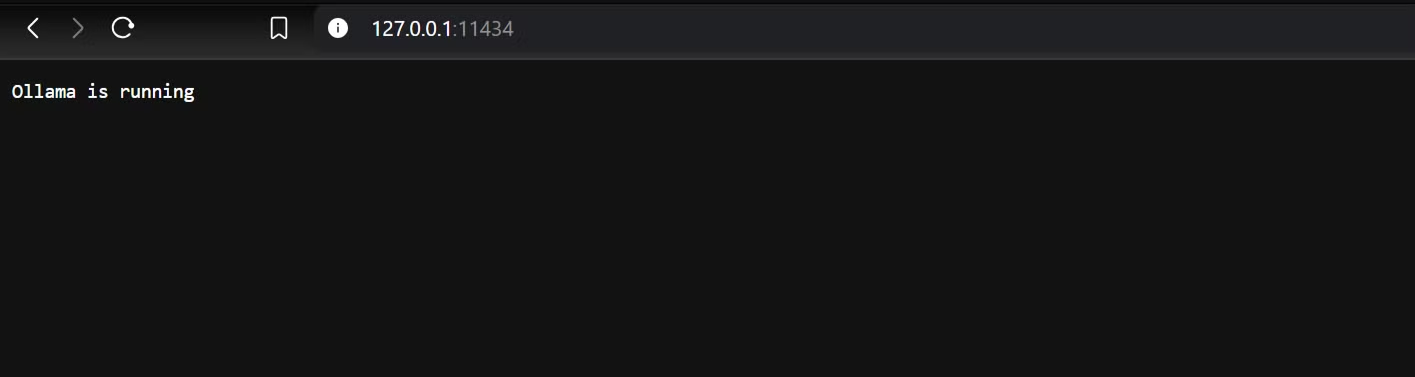
By default, the model is running at http://localhost:11434. Visiting this URL will show a message indicating that Ollama is running.
ScrapeGraphAI Installation
The final step in the setup process is to install ScrapeGraphAI. It is recommended to use a tool like Poetry or venv to create an isolated environment and effectively manage dependencies for your project.
To install ScrapeGraphAI, use the following command:
pip install scrapegraphai
This installation also includes Playwright, a tool for automating browser tasks.
If you want to delve deeper into using Playwright, check out my Playwright 4-part series where I cover everything from basics to advanced techniques.
Lastly, download and install the browser binaries:
playwright install
With these tools set up, you’re ready to start scraping!
Steps to Build a ScrapeGraphAI Application
Follow these general steps to create a simple ScrapeGraphAI application:
- Define Task: Specify the data you want to extract from websites or local documents.
- Select the Scraping Pipeline: Choose the appropriate pipeline for your needs. For a single page, use SmartScraperGraph. For other use cases, you can use different pipelines which were discussed earlier.
- Run the Pipeline: Run the pipeline using the .run() method to start data extraction.
- Check and Use Data: Validate the extracted data. While LLMs are powerful, they might not always give perfect results on the first try. Adjust the prompt and settings as necessary to get the desired result.
Scraping JSON Data using LLama
To begin web scraping using LLMs, we’ll start by scraping data from a JSON file. First, create a JSON file in your directory and add some data. For a more comprehensive example, you can download a sample JSON file from my GitHub.
{
"jobListings": [
{
"__typename": "JobListingSearchResult",
"jobview": {
"__typename": "JobView",
"header": {
"__typename": "JobViewHeader",
"adOrderId": 1136043,
"advertiserType": "GENERAL",
"ageInDays": 29,
"divisionEmployerName": null,
"easyApply": true,
"employer": {
"__typename": "Employer",
"id": 289172,
"name": "Omnipresent Inc",
"shortName": "Omnipresent"
},
"employerNameFromSearch": "Omnipresent",
"expired": false,
"goc": "data engineer",
"gocConfidence": 0.9,
"gocId": 100080,
"indeedJobAttribute": {
"__typename": "IndeedJobAttribute"
...
...
...
}
}
}
}
]
}
The JSON file contains complex company data such as salary, rating, location, pay currency, and minimum and maximum pay. It’s about 5,500 lines long but contains only a few relevant data. We’ll test whether AI can effectively extract useful data.
Let’s build our AI scraper!
First, import the JSONScraperGraph class from scrapegraphai.graphs. Then, configure the scraping settings in the graph_config dictionary. This defines the models and settings, including the base URLs for the Ollama and embedding servers where they are hosted.
# Import JSONScraperGraph from scrapegraphai.graphs
from scrapegraphai.graphs import JSONScraperGraph
# Configuration for the scraper graph
graph_config = {
"llm": {
"model": "ollama/llama3",
"temperature": 0,
"format": "json",
"base_url": "http://localhost:11434",
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"temperature": 0,
"base_url": "http://localhost:11434",
},
"verbose": True,
}
Next, open the JSON file to read its content.
with open("job_data.json", "r", encoding="utf-8") as file:
text = file.read()
Create an instance of JSONScraperGraph, set a prompt to extract specific details from the JSON, and run the scraper.
# Initialize JSONScraperGraph with specified parameters
json_scraper_graph = JSONScraperGraph(
prompt="List me all employer name, rating, job title, location, currency, min and max pay.",
source=text,
config=graph_config,
)
# Execute the scraping and processing of JSON data
result = json_scraper_graph.run()
# Display the result in the console
print(result)
Once the script runs (this might take a few minutes depending on your system), it will output a Python dictionary containing the data you requested.

Great! The data is now easy to read and ready for further use.
This shows how ScrapeGraphAI can extract relevant data from a large, complex JSON file. It can also handle other formats like HTML, CSV, and PDF. Let’s try extracting data from HTML next!
Scraping HTML Data using LLama
Now, let’s see the power of ScrapeGraphAI to extract relevant data from this raw HTML. This time, we’ll be dealing with a much larger file—around 70,000 lines of HTML—packed with messy and redundant data, only a small portion of which is useful. Our goal is to extract company information such as names, roles, ratings, and salaries.
Here’s how we can achieve that:
from scrapegraphai.graphs import SmartScraperGraph
import json
# Configuration for the SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/llama3",
"temperature": 0,
"format": "json",
"base_url": "http://localhost:11434",
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"temperature": 0,
"base_url": "http://localhost:11434",
},
"verbose": True,
}
# File path for the raw HTML data
file_path = "raw_html_jobs.html"
# Read the HTML file content
with open(file_path, "r", encoding="utf-8") as file:
text = file.read()
# Initialize the SmartScraperGraph with the configuration and HTML content
smart_scraper_graph = SmartScraperGraph(
prompt="List me all the company name, role, rating and salary",
source=text,
config=graph_config,
)
# Run the SmartScraperGraph to extract data
result = smart_scraper_graph.run()
# Save the extracted data to a JSON file
with open("extracted_data.json", "w", encoding="utf-8") as json_file:
json.dump(result, json_file, ensure_ascii=False, indent=4)
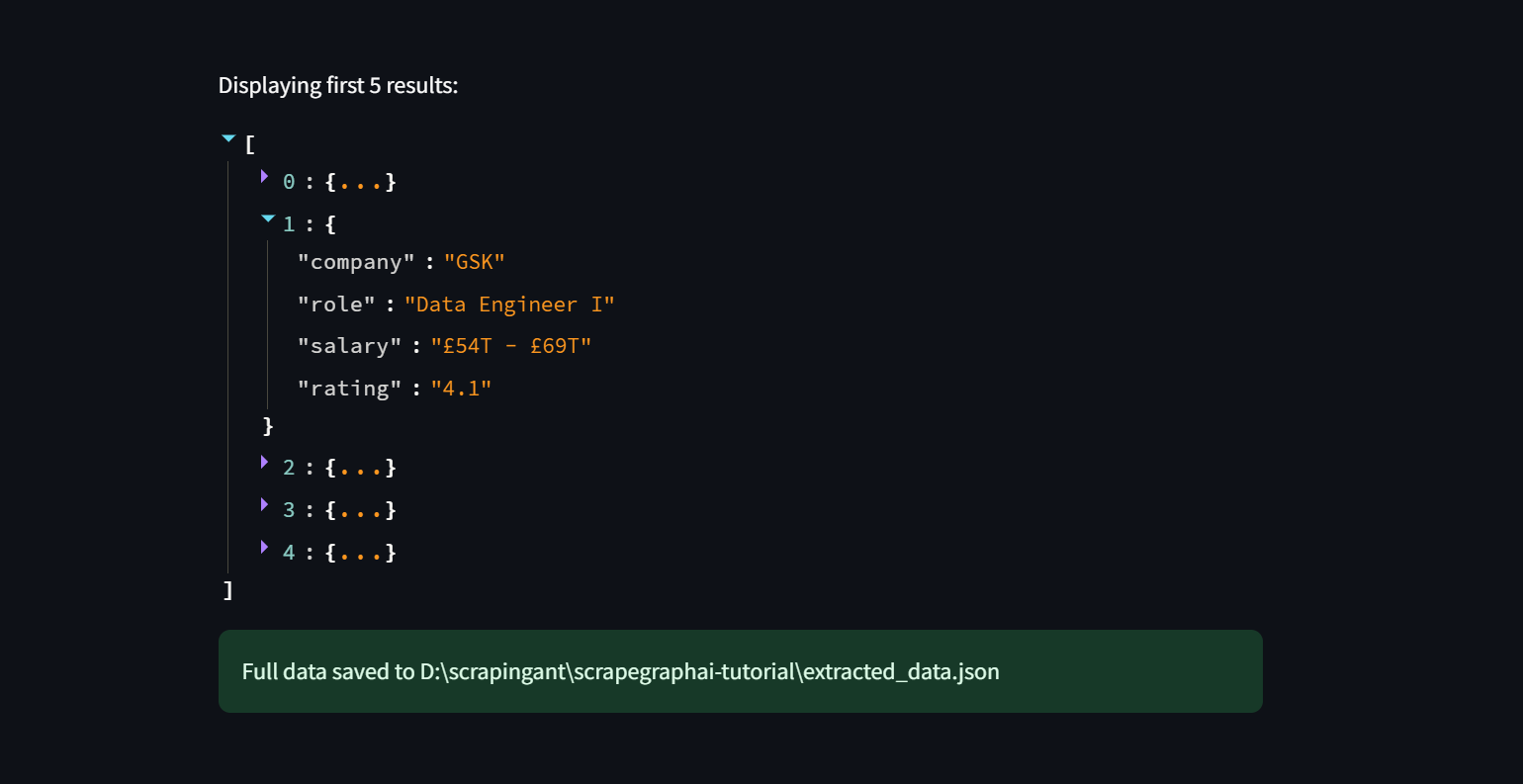
The process is quite similar to the one we used for JSON, but in this case, we’re using the SmartScraperGraph pipeline. This allows us to extract relevant data from the HTML data and save the results in a JSON file.
Once the script finishes running, you’ll have a clean and organized dataset.

Awesome! This data is now in a format that’s easy to analyze or use in other applications, showing just how powerful ScrapeGraphAI can be for parsing complex documents!
Next Step
This part covers the use of local models like LLama for parsing complex documents, but the process is slow, resource-intensive, and may sometimes be less accurate. In Part 2, we will shift to using API-based models like OpenAI for faster and real-time web scraping.