

Google Images is a major source of visual content on the web, and scraping these images can be very useful for research, image processing, creating datasets for machine learning, and more. However, due to Google's complex DOM structure and the dynamic nature of search results, accurately extracting images can be quite challenging.
In this article, we will guide you through the entire process of scraping Google Images using Python. You will learn how to interact with the images, download them, handle potential errors, and optimize the downloading process.
TL;DR: Python Google Images Scraper Code
If you don't have much time but need a quick way to extract data from Google Images, just copy and paste the code, run it, and you're good to go!
import asyncio
import json
import os
import shutil
from aiohttp import ClientSession, ClientTimeout
from urllib.parse import urlparse, urlencode
from playwright.async_api import async_playwright
# Function to extract the domain from a URL
def extract_domain(url):
"""
Extract the domain from the given URL.
If the domain starts with 'www.', it removes it.
Args:
url (str): The URL to extract the domain from.
Returns:
str: The extracted domain.
"""
domain = urlparse(url).netloc
if domain.startswith("www."):
domain = domain[4:]
return domain
# Function to download an image with retry logic
async def download_image(session, img_url, file_path, retries=3):
"""
Download an image from the given URL and save it to the specified file path.
If the download fails, it retries the specified number of times.
Args:
session (ClientSession): The aiohttp session to use for downloading.
img_url (str): The URL of the image to download.
file_path (str): The path to save the downloaded image.
retries (int, optional): The number of retries for downloading. Defaults to 3.
Returns:
None
"""
attempt = 0
while attempt < retries:
try:
# Attempt to download the image
async with session.get(img_url) as response:
if response.status == 200:
# Write the image content to the file
with open(file_path, "wb") as f:
f.write(await response.read())
print(f"Downloaded image to: {file_path}")
return
else:
print(f"Failed to download image from {img_url}. Status: {response.status}")
except Exception as e:
print(f"Error downloading image from {img_url}: {e}")
attempt += 1
# Retry if the maximum number of attempts has not been reached
if attempt < retries:
print(f"Retrying download for {img_url} (attempt {attempt + 1}/{retries})")
await asyncio.sleep(2**attempt) # Exponential backoff for retries
print(f"Failed to download image from {img_url} after {retries} attempts.")
# Function to scroll to the bottom of the page
async def scroll_to_bottom(page):
"""
Scroll to the bottom of the web page using Playwright.
Args:
page (Page): The Playwright page object to scroll.
Returns:
None
"""
print("Scrolling...")
previous_height = await page.evaluate("document.body.scrollHeight")
while True:
# Scroll to the bottom of the page
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(1)
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == previous_height:
break
previous_height = new_height
print("Reached the bottom of the page.")
# Main function to scrape Google Images
async def scrape_google_images(search_query="macbook m3", max_images=None, timeout_duration=10):
"""
Scrape images from Google Images for a given search query.
Args:
search_query (str, optional): The search term to use for Google Images. Defaults to "macbook m3".
max_images (int, optional): The maximum number of images to download. If None, downloads all available. Defaults to None.
timeout_duration (int, optional): The timeout duration for the image download session. Defaults to 10 seconds.
Returns:
None
"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False) # Launch a Chromium browser
page = await browser.new_page() # Open a new browser page
# Build the Google Images search URL with the query
query_params = urlencode({"q": search_query, "tbm": "isch"})
search_url = f"https://www.google.com/search?{query_params}"
print(f"Navigating to search URL: {search_url}")
await page.goto(search_url) # Navigate to the search results page
# Scroll to the bottom of the page to load more images
await scroll_to_bottom(page)
await page.wait_for_selector('div[data-id="mosaic"]') # Wait for the image section to appear
# Set up directories for image storage
download_folder = "downloaded_images"
json_file_path = "google_images_data.json"
if os.path.exists(download_folder):
# Prompt the user whether to delete or archive the existing folder
user_input = input(f"The folder '{download_folder}' already exists. Do you want to delete it? (yes/no): ")
if user_input.lower() == "yes":
print(f"Removing existing folder: {download_folder}")
shutil.rmtree(download_folder)
else:
archive_folder = f"{download_folder}_archive"
print(f"Archiving existing folder to: {archive_folder}")
shutil.move(download_folder, archive_folder)
os.makedirs(download_folder) # Create a new folder to store the images
# Initialize the JSON file to store image metadata
with open(json_file_path, "w") as json_file:
json.dump([], json_file)
# Find all image elements on the page
image_elements = await page.query_selector_all('div[data-attrid="images universal"]')
print(f"Found {len(image_elements)} image elements on the page.")
async with ClientSession(timeout=ClientTimeout(total=timeout_duration)) as session:
images_downloaded = 0
image_data_list = []
# Iterate through the image elements
for idx, image_element in enumerate(image_elements):
if max_images is not None and images_downloaded >= max_images:
print(f"Reached max image limit of {max_images}. Stopping download.")
break
try:
print(f"Processing image {idx + 1}...")
# Click on the image to get a full view
await image_element.click()
await page.wait_for_selector("img.sFlh5c.FyHeAf.iPVvYb[jsaction]")
img_tag = await page.query_selector("img.sFlh5c.FyHeAf.iPVvYb[jsaction]")
if not img_tag:
print(f"Failed to find image tag for element {idx + 1}")
continue
# Get the image URL
img_url = await img_tag.get_attribute("src")
file_extension = os.path.splitext(urlparse(img_url).path)[1] or ".png"
file_path = os.path.join(download_folder, f"image_{idx + 1}{file_extension}")
# Download the image
await download_image(session, img_url, file_path)
# Extract source URL and image description
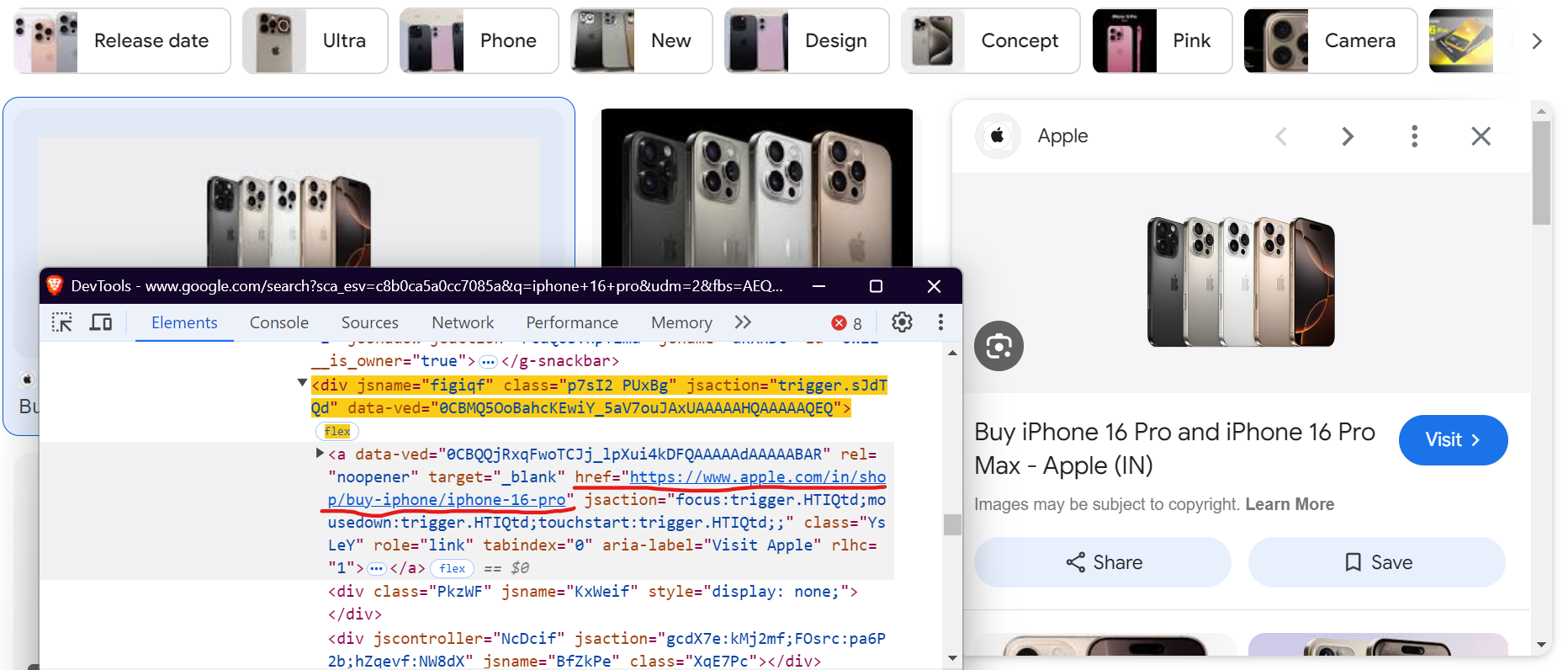
source_url = await page.query_selector('(//div[@jsname="figiqf"]/a[@class="YsLeY"])[2]')
source_url = await source_url.get_attribute("href") if source_url else "N/A"
image_description = await img_tag.get_attribute("alt")
source_name = extract_domain(source_url)
# Store image metadata
image_data = {
"image_description": image_description,
"source_url": source_url,
"source_name": source_name,
"image_file": file_path,
}
image_data_list.append(image_data)
print(f"Image {idx + 1} metadata prepared.")
images_downloaded += 1
except Exception as e:
print(f"Error processing image {idx + 1}: {e}")
continue
# Save image metadata to a JSON file
with open(json_file_path, "w") as json_file:
json.dump(image_data_list, json_file, indent=4)
print(f"Finished downloading {images_downloaded} images.")
await browser.close() # Close the browser when done
# Run the main function with specified query and limits
asyncio.run(scrape_google_images(search_query="iphone 16 pro", max_images=10, timeout_duration=10))
Here's what the entire process looks like:
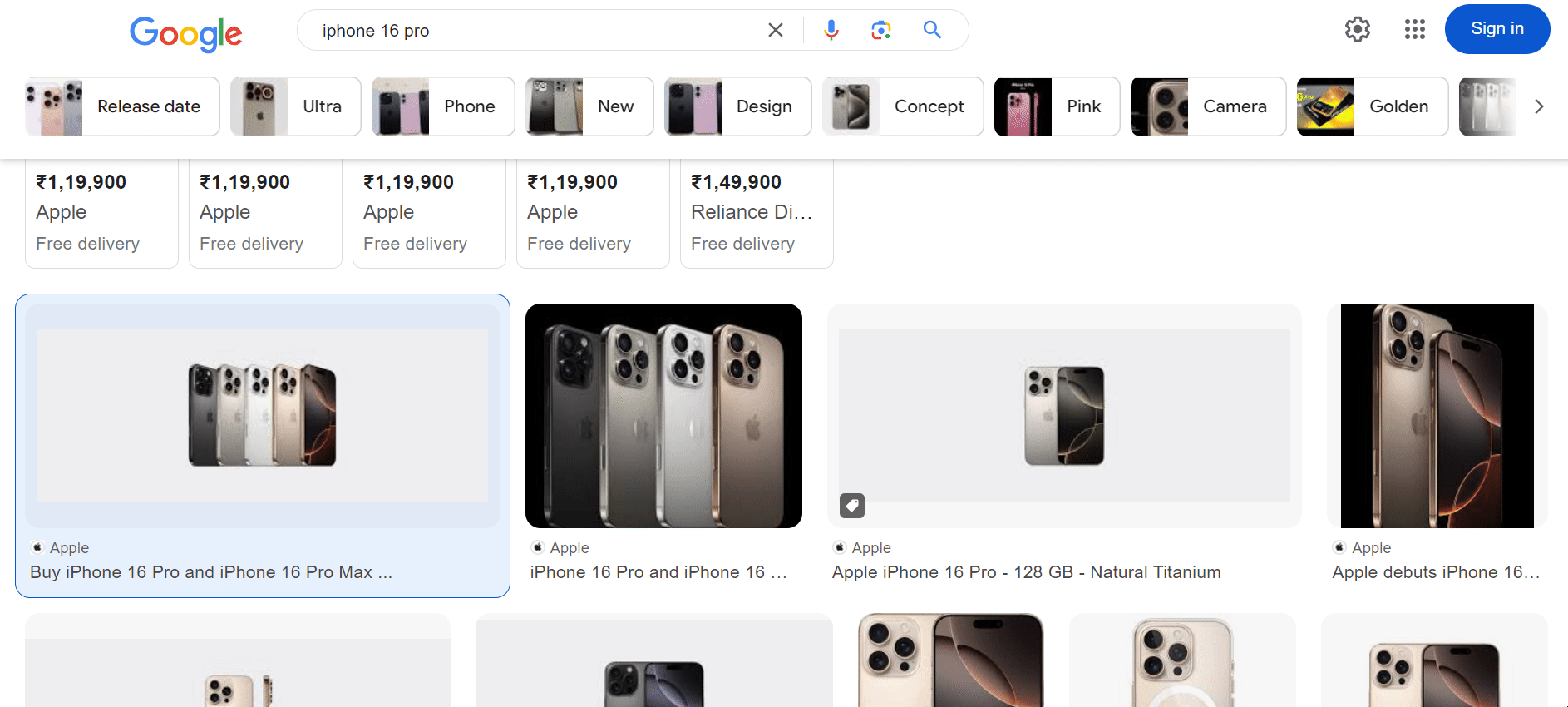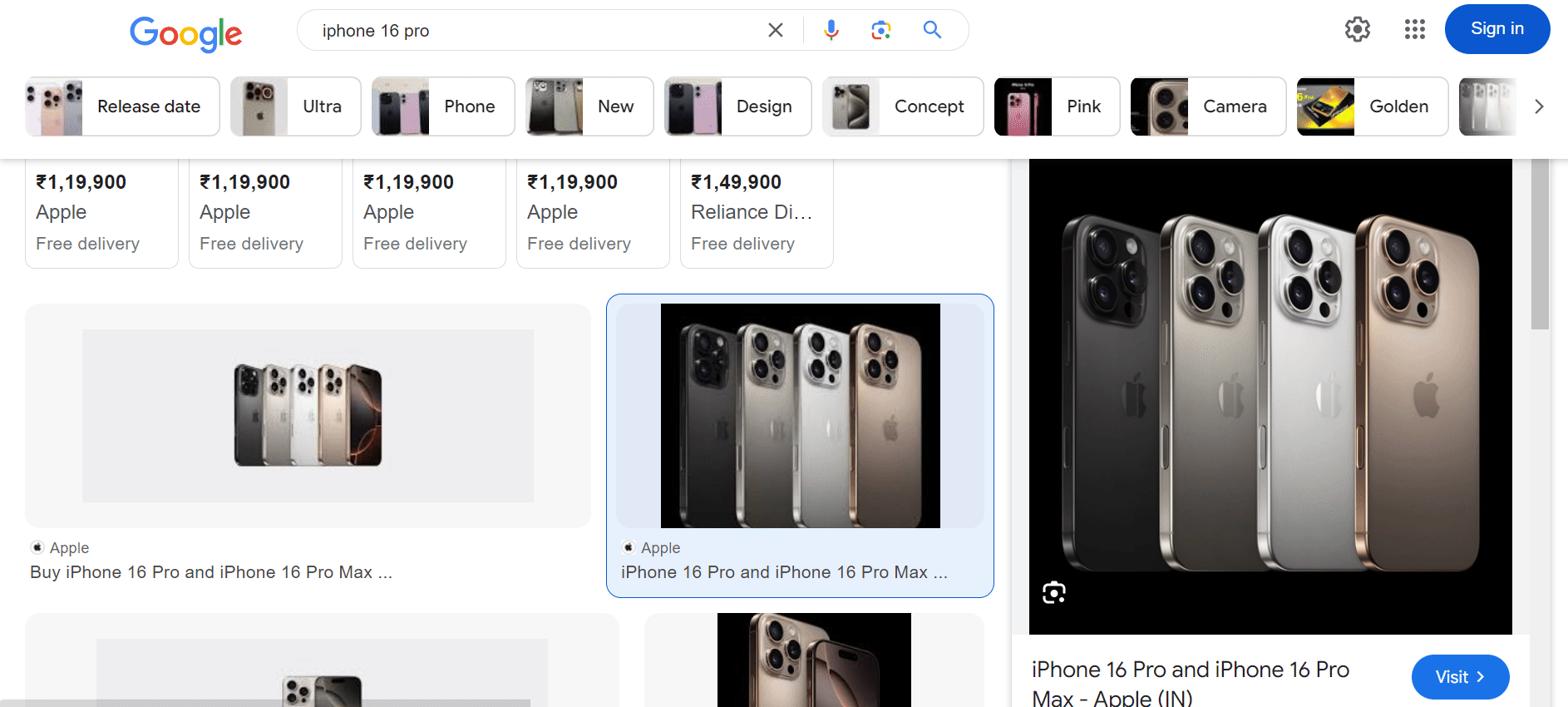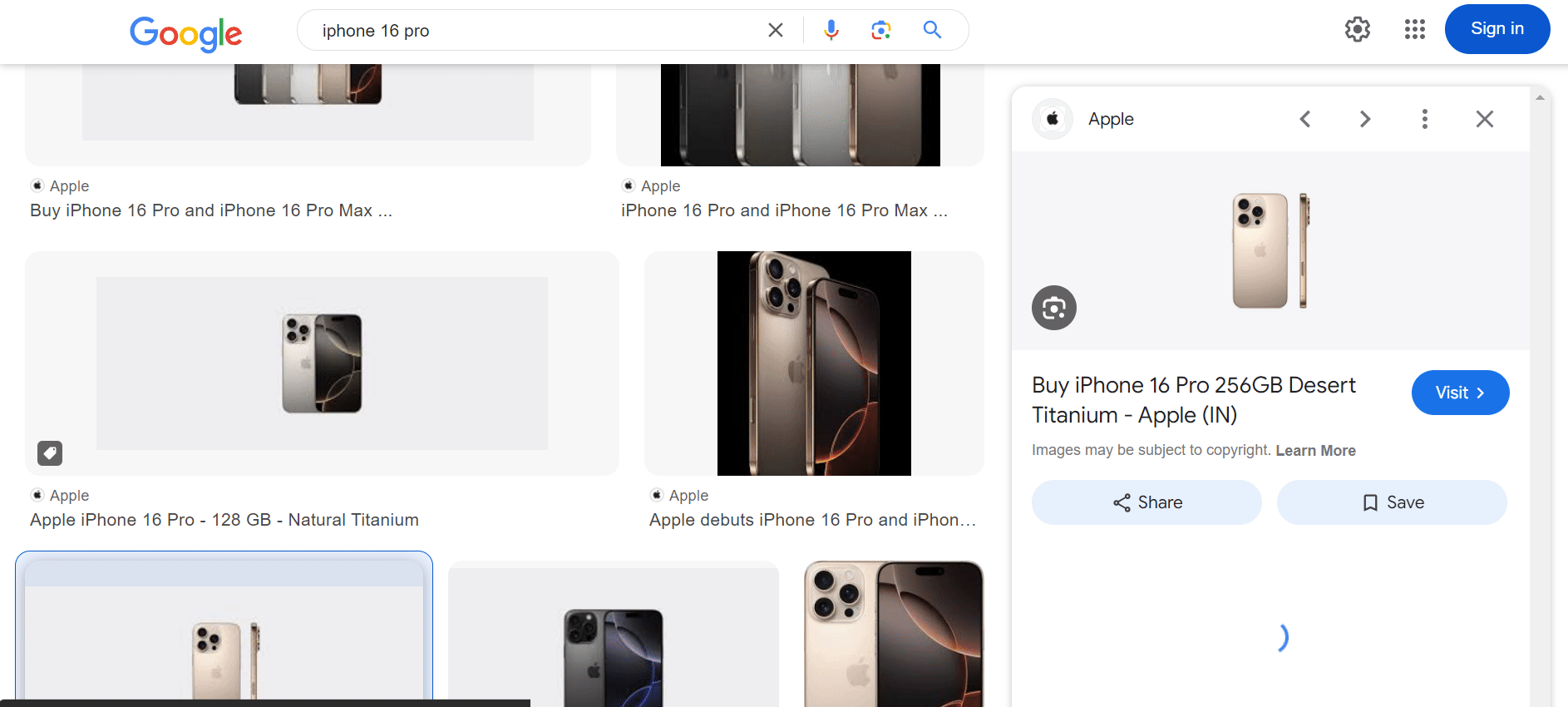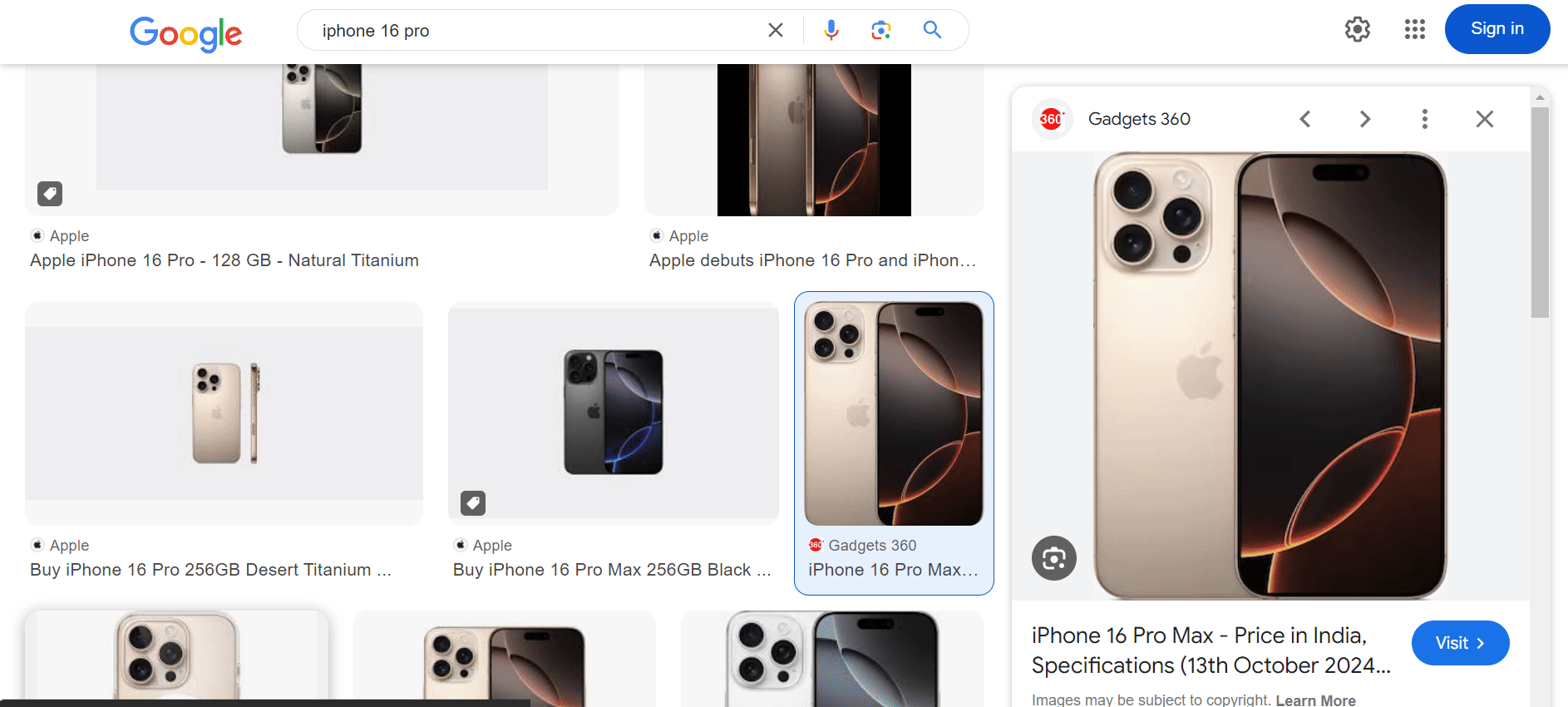
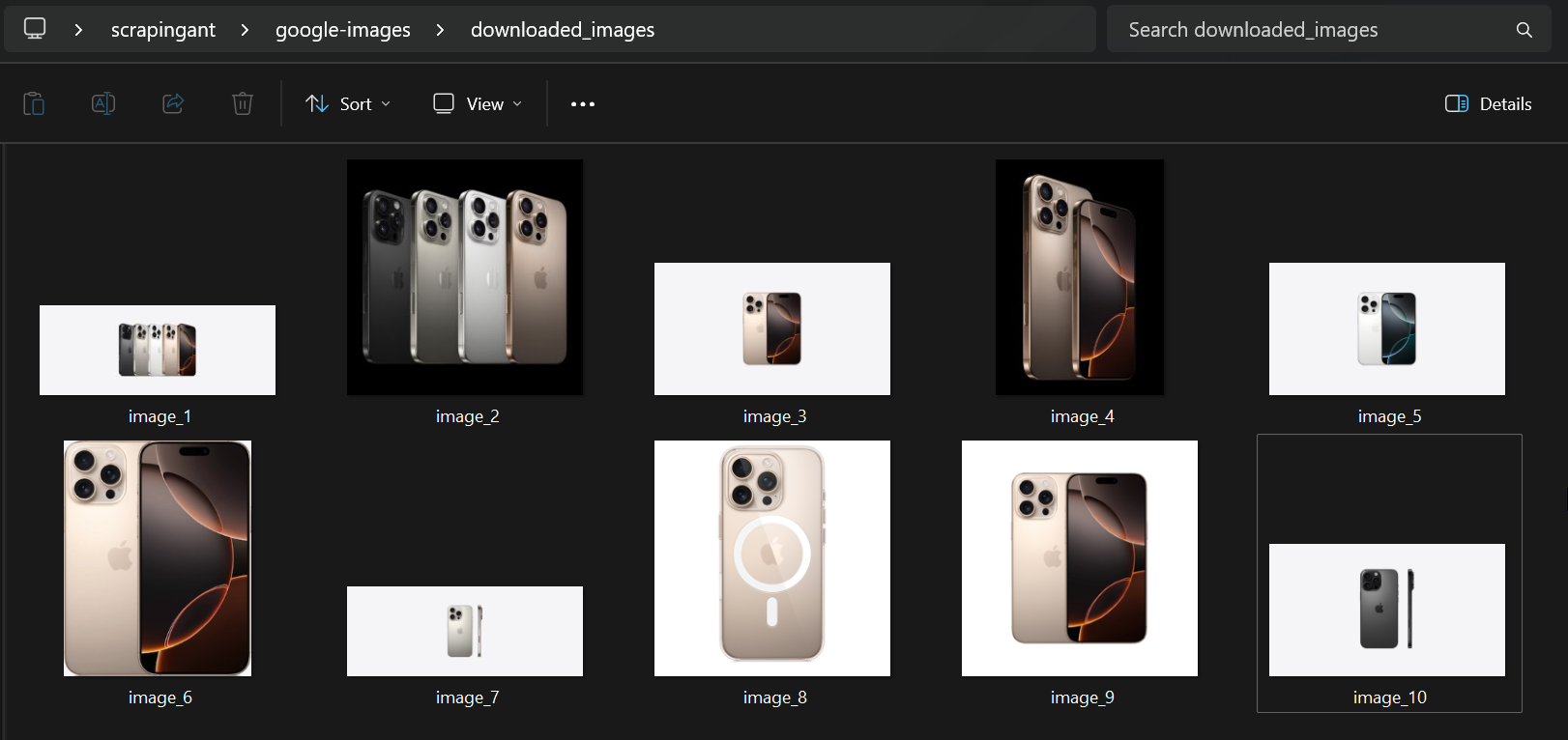
Once the script runs, check your downloaded_images for the images and google_images_data.json file containing all the metadata you need.
downloaded_images folder:
google_images_data.json:
[
{
"image_description": "Buy iPhone 16 Pro and iPhone 16 Pro Max - Apple (IN)",
"source_url": "https://www.apple.com/in/iphone-16-pro/",
"source_name": "apple.com",
"image_file": "downloaded_images\\image_1.png"
},
{
"image_description": "iPhone 16 Pro and iPhone 16 Pro Max - Apple (IN)",
"source_url": "https://www.apple.com/in/iphone-16-pro/",
"source_name": "apple.com",
"image_file": "downloaded_images\\image_2.jpg"
},
{
"image_description": "iPhone 16 Pro 256GB Desert Titanium",
"source_url": "https://www.apple.com/in/shop/buy-iphone/iphone-16-pro/6.3%22-display-256gb-desert-titanium",
"source_name": "apple.com",
"image_file": "downloaded_images\\image_3.png"
}
]
Prerequisites and Setup
Before we dive into the code, let’s see what you need to get started.
1. Check Python Installation
First, make sure Python is installed on your system. Open a terminal and run the following command:
python --version
If Python is not installed, you can download it from the official website.
2. Install Required Python Libraries
You’ll need a few important libraries. Here’s how to set up:
Install Playwright: Playwright is a powerful library used for automating browser interactions.
Install it using pip:
pip install playwright
Afterwards, install the required browsers by running:
playwright install
If you’re new to Playwright and want a step-by-step guide, I’ve created a 4-part Playwright series that’s beginner-friendly and covers everything you need to know.
Install aiohttp: aiohttp allows us to handle asynchronous HTTP requests, which will help download images concurrently:
pip install aiohttp
Install Additional Libraries: You'll also need urllib3 to handle URLs and manage file paths efficiently:
pip install urllib3
Once you’ve installed these libraries, you're ready to start building Google images scraper!
Building a Google Images Scraper
Let’s see the complete process of building a Google Images scraper, step-by-step.
What Data Can You Extract from Google Images?
When scraping Google Images, you can scrape data such as:
- Source URL: The webpage where the image originates.
- Image Descriptions (Alt Text): A brief description of the image.
- Image File: The actual image file that can be downloaded.
... and many more.
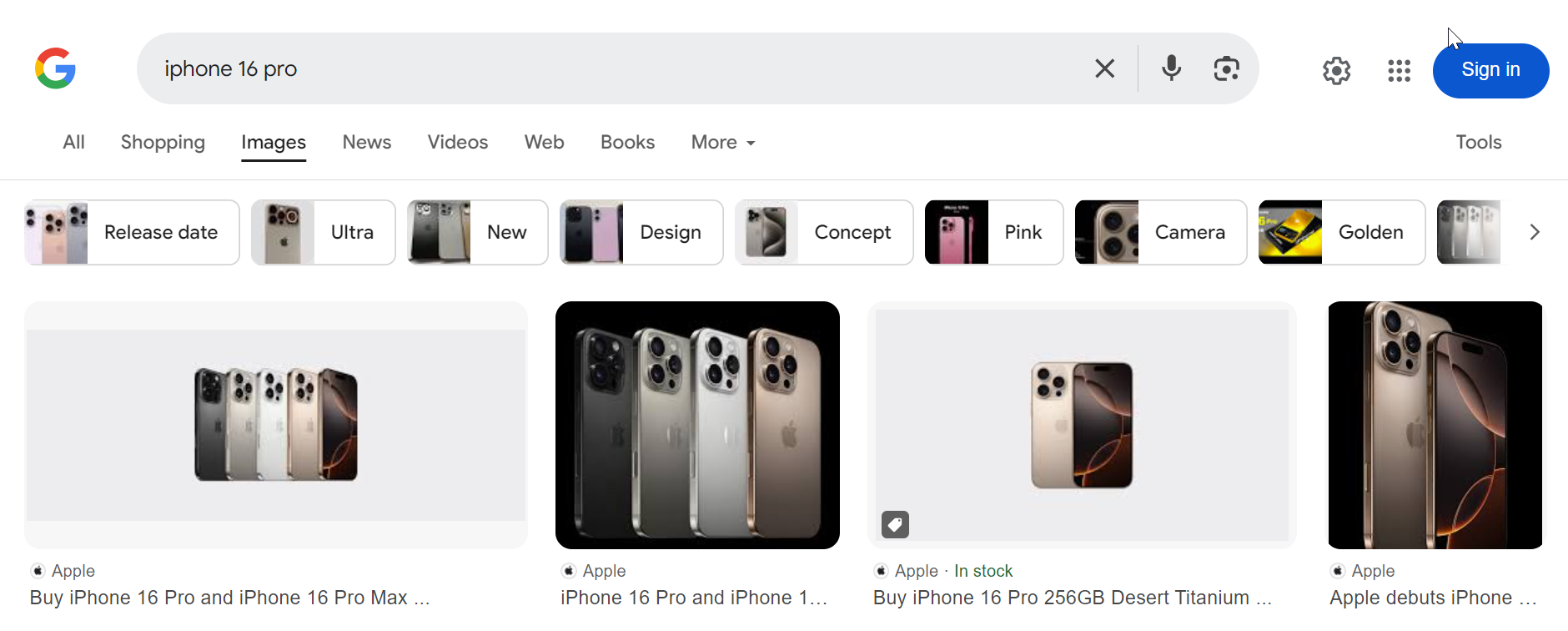
Step 1: Navigate to Google Images
To begin, we'll use Playwright to launch a headless browser and navigate to Google Images based on a search query. For example, if you want to search for "iPhone 16 Pro", the URL will look like this:
https://www.google.com/search?q=iphone+16+pro&tbm=isch
The tbm=isch parameter tells Google to return image search results instead of regular web results.
Here’s the code to navigate to Google Images:
from urllib.parse import urlencode
from playwright.async_api import async_playwright
import asyncio
async def scrape_google_images(search_query):
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
query_params = urlencode({"q": search_query, "tbm": "isch"})
search_url = f"https://www.google.com/search?{query_params}"
print(f"Navigating to: {search_url}")
await page.goto(search_url)
await browser.close()
asyncio.run(scrape_google_images(search_query="iphone 16 pro"))
This code sets up an asynchronous Playwright instance to control a Chromium browser. It also uses urlencode to properly format the search query for Google Images.
Here's how the page will appear:
Step 2: Scroll to Load More Images
Google Images uses dynamic loading, meaning it loads more results as you scroll. To extract all images, you'll need to scroll down the page until no more new images appear.
async def scroll_to_bottom(page):
previous_height = await page.evaluate("document.body.scrollHeight")
while True:
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(1)
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == previous_height:
break
previous_height = new_height
This code continuously scrolls to the bottom of the page until all images are loaded.
Step 3: Extract Image Elements
Once the page is fully loaded, it’s time to extract the image elements. The images on the page are nested inside specific HTML containers.
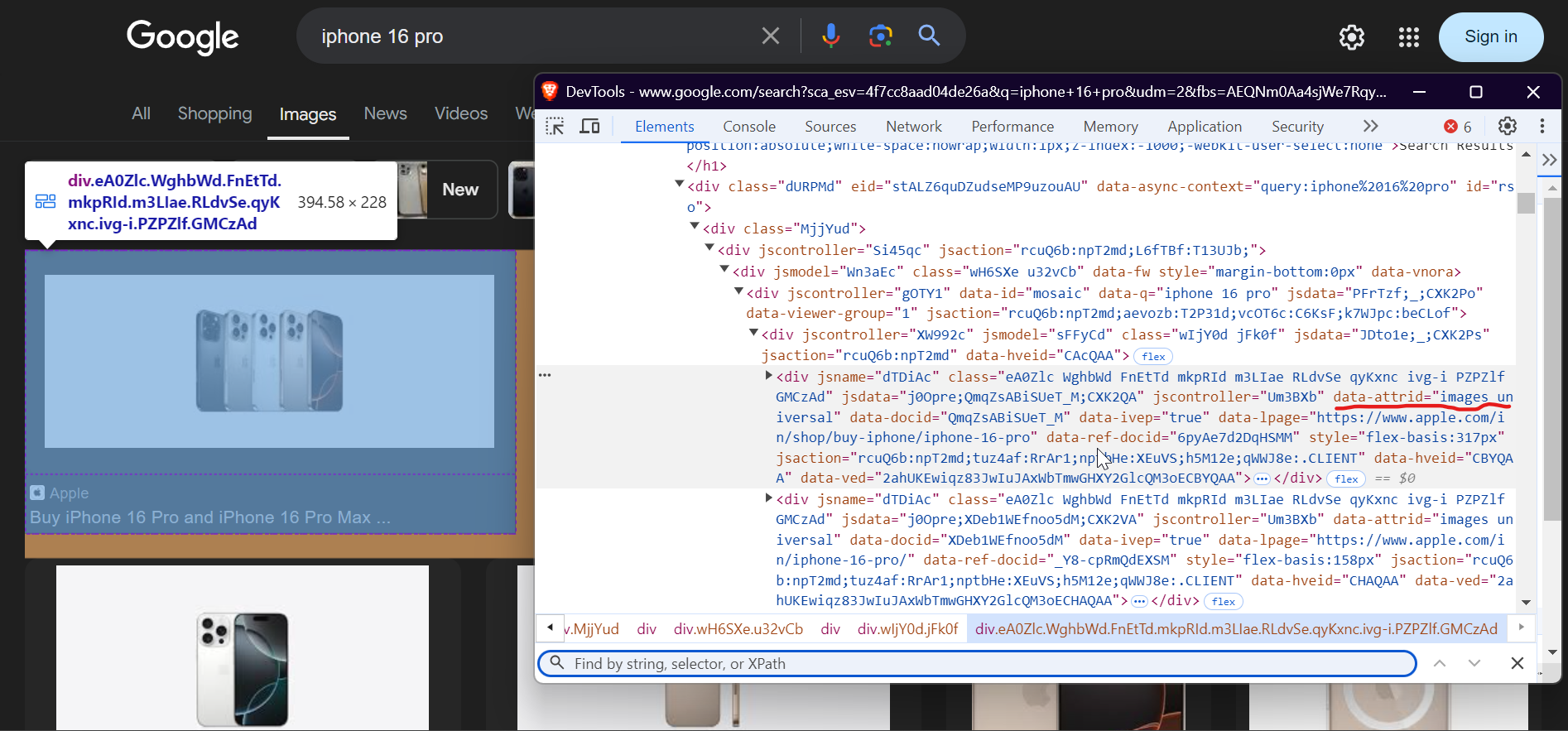
Here’s how you can use Playwright to select all image elements:
image_elements = await page.query_selector_all('div[data-attrid="images universal"]')
Step 4: Iterate Over and Process Image Elements
Now that we have the image elements, we can iterate through each of them and download the images.
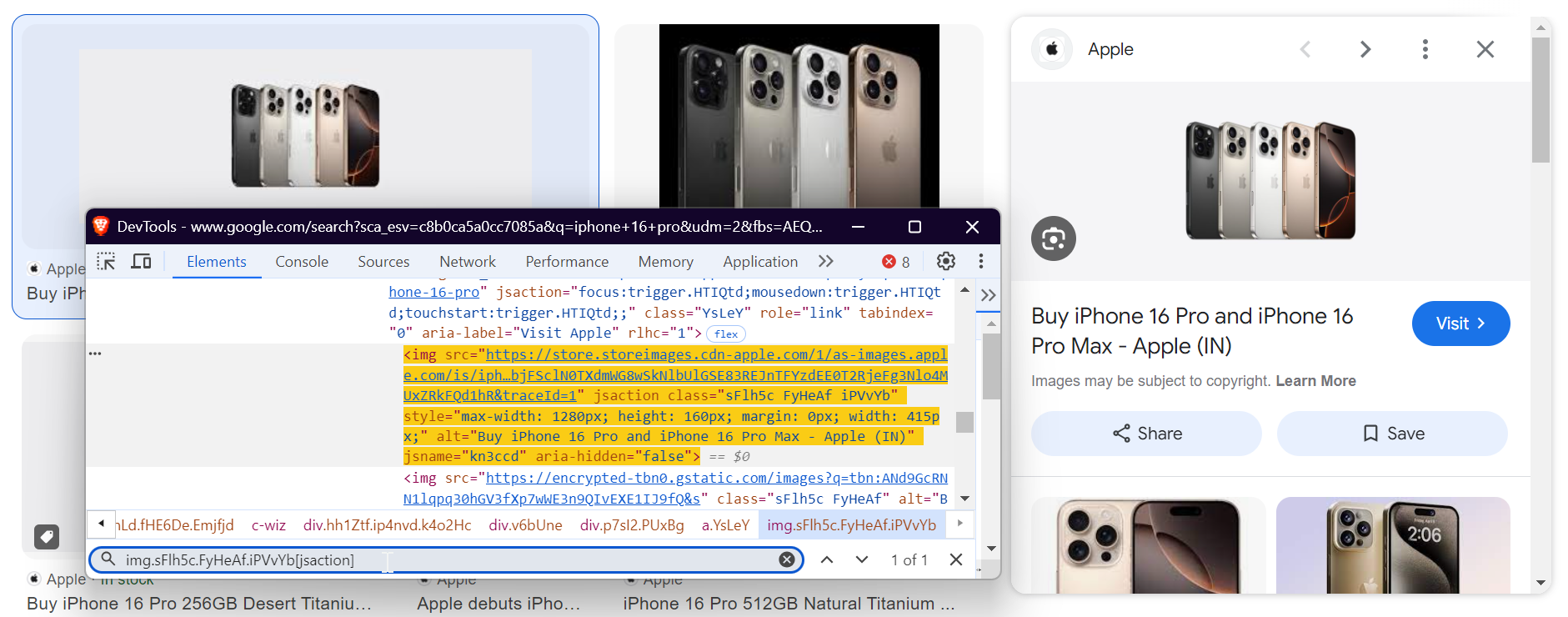
Here’s how to loop through each image element:
for idx, image_element in enumerate(image_elements):
try:
await image_element.click()
await page.wait_for_selector("img.sFlh5c.FyHeAf.iPVvYb[jsaction]")
except Exception as e:
print(f"Error processing image {idx + 1}: {e}")
continue
This code clicks each image to load the full-size version, waits for it to appear, and handles any errors during the process.
Step 5: Download Images Asynchronously
To download images efficiently, we’ll use aiohttp to make asynchronous HTTP requests, allowing us to download multiple images concurrently.
async def download_image(session, img_url, file_path, retries=3):
attempt = 0
while attempt < retries:
try:
async with session.get(img_url) as response:
if response.status == 200:
with open(file_path, "wb") as f:
f.write(await response.read())
print(f"Downloaded image to: {file_path}")
return
except Exception as e:
print(f"Error downloading image from {img_url}: {e}")
attempt += 1
if attempt < retries:
await asyncio.sleep(2**attempt)
This code ensures that images are downloaded efficiently with retry logic to handle potential download errors.
Step 6: Extract Image Metadata
Besides downloading the images, it's important to capture metadata like the source URL, domain name, and image description (alt text).
Here’s the code snippet:
source_url = await page.query_selector('(//div[@jsname="figiqf"]/a[@class="YsLeY"])[2]')
source_url = await source_url.get_attribute("href") if source_url else "N/A"
source_name = extract_domain(source_url)
image_description = await img_tag.get_attribute("alt")
This code fetches the image's source URL and its alt text. Additionally, we use the extract_domain() function to extract the domain from the source URL.
The extract_domain() function takes a URL and extracts the domain name. For example, if the URL is:
https://www.gadgets360.com/apple-iphone-16-pro-max-price-in-india-128236
…the source domain extracted would be gadgets360.com.
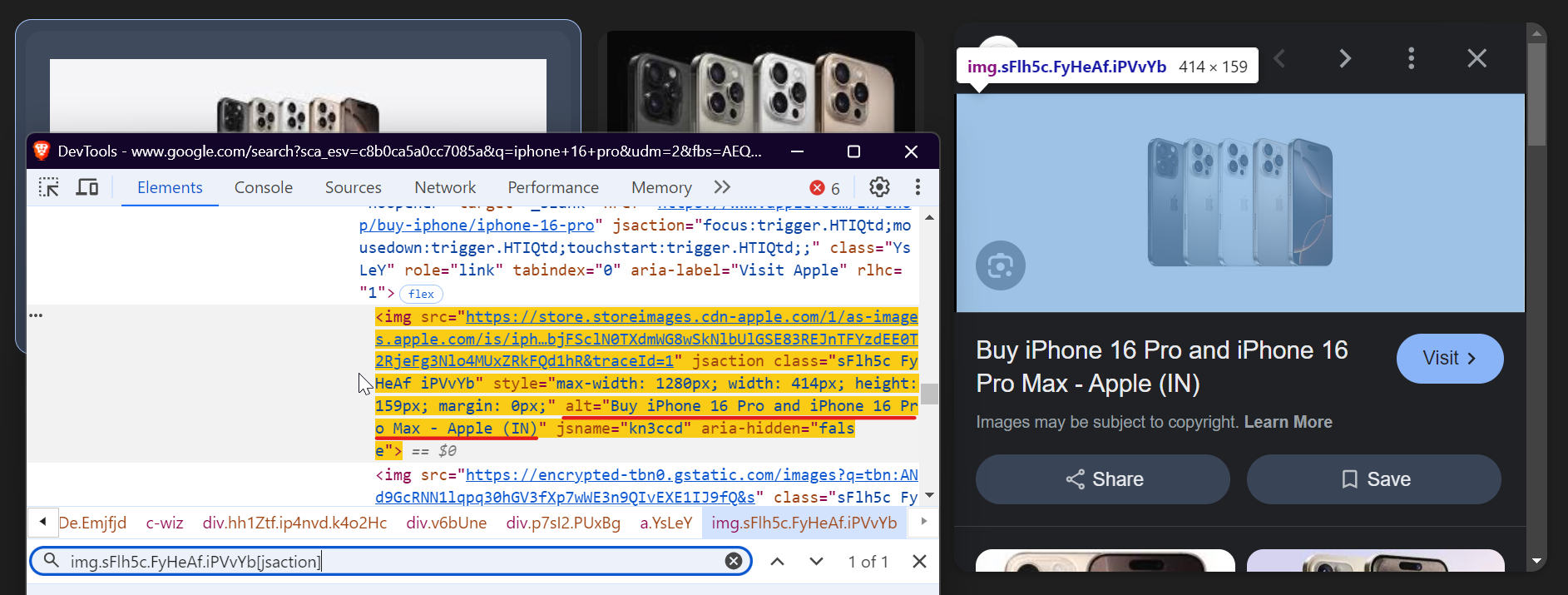
Next, you extract the image description using the image's alt attribute. To select the image, use the following selector:
img_tag = await page.query_selector("img.sFlh5c.FyHeAf.iPVvYb[jsaction]")
In the screenshot below, you can see the alt text highlighted, which we're extracting:
Step 7: Save Data in JSON Format
After downloading images and collecting metadata, organize the data and save it to a JSON file.
image_data = {
'image_description': image_description,
'source_url': source_url,
'source_name': source_name,
'image_file': file_path
}
image_data_list.append(image_data)
with open(json_file_path, 'w') as json_file:
json.dump(image_data_list, json_file, indent=4)
Step 8: Run the Scraper
To run the scraper, call the main function with the desired search query and the maximum number of images to download. If max_images is set to None, the script will download all images available on the page.
asyncio.run(scrape_google_images(search_query="iphone 16 pro", max_images=10, timeout_duration=10))
You can download the complete code from my gisthub gist: [Google Images Scraper - ScrapingAnt].
And that’s it! You've built a fully functioning Google Images scraper. You can download the complete code from my GitHub: Google Images Scraper - ScrapingAnt.
Challenges and Considerations
While Google Images provides valuable data, scraping it directly can be difficult due to Google’s advanced bot detection systems. Even with methods like rotating IPs, adding random delays, and mimicking user behavior, these techniques aren't foolproof, especially if you're scraping at scale across multiple search queries.
A more efficient solution is to use ScrapingAnt, a web scraping API that manages everything for you—IP rotation, delays, and browser emulation—ensuring that you can scrape large amounts of Google Images data without getting blocked.
To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you.
Conclusion
We've covered everything you need to know about scraping Google Images, from downloading images concurrently to handling errors smoothly. The images will be saved in a designated folder, and you can easily control how many to download by specifying the number. If no limit is set, the scraper will continue scrolling until it captures all available images.
Scraping at scale presents challenges like bot detection and rate limiting, but using tools like ScrapingAnt simplifies the process by handling these issues automatically. Get started today with 10,000 free API credits 🚀