

Tripadvisor is without a doubt one of the biggest travel platforms out there travelers will consult to find out about the next hot summer destination.
It's a goldmine for user reviews and ratings of hotels, restaurants and vacation rentals.
In this short tutorial we will be scraping the names, reviews and standard prices of hotels in Python using ScrapingAnts Web Scraping API.
Why Scrape TripAdvisor ?
Data from Tripadvisor can be used in endless ways to learn about the Hotel and Travel industry, it can also be used for competitive analysis and business intelligence. Such as getting notified when there's a new rental available or when there's a price update.
Using Tripadvisor's public reviews we can also learn about public opinion on hotels, restaurants and rentals.
Let's have a look at how we can start scraping data from Tripadvisor in Python using ScrapingAnt's Web Scraping API.
Scraping Tripadvisor with ScrapingAnts Web Scraping API in Python
In this short tutorial, we'll be scraping Italian Hotels Name, number of reviews and URL of hotel pages.
First, let's import the libraries we will need in this tutorial:
from bs4 import BeautifulSoup
import http.client
Now let's setup the URLs we will be scraping.
Since Tripadvisor uses a different pagination pattern starting from the second page and we still want the data from the first page, we'll have to declare a base URL for the first page and a template URL for the rest of the pages, in this example we will be scraping data of hotels based in Italy:
base_url = "https://www.tripadvisor.com/Hotels-g187768-Italy-Hotels.html"
template_url = "https://www.tripadvisor.com/Hotels-g187768-oa{}-Italy-Hotels.html"
You can replace these URLs with any URL you want from Tripadvisor, you can easily get them by doing a Search on Tripadvisor and don't forget to add oa{} in the template_url.
Now let's generate the pages we will scrape, we'll just scrape the first two pages to keep it short and simple:
num_pages = 2
urls = [base_url]
for i in range(30, (num_pages * 30), 30):
urls.append(template_url.format(i))
Now let's create three lists that will contain all of our data:
Hotel_Name = []
Hotel_Review = []
Hotel_Link = []
Since we will be looping through multiple URLs, we need to add a for loop:
for url in urls:
Now let's connect to ScrapingAnts API using Python's http library:
conn = http.client.HTTPSConnection("api.scrapingant.com")
conn.request("GET", "/v2/general?url={}&x-api-key=YOUR-API-TOKEN&proxy_type=residential&proxy_country=US".format(url))
Now let's add our API token in the request string, you can find your API token in the ScrapingAnt Dashboard after creating an account, we'll also use proxies by adding &proxy_type=residential&proxy_country=US at the end of our request string so that we don't get flagged and blocked by Tripadvisor's anti-bot protection.
Note that we will perform a GET request and we'll add a format() method at the end of the request string so that we can update the string with a new URL in every loop.
Finally, let's instantiate the response of our request to a variable called data:
res = conn.getresponse()
data = res.read()
We then parse the scraped data using BeautifulSoup and instantiate it to a variable called soup:
soup = BeautifulSoup(data, "html.parser")
Now let's go find the element tags on Tripadvisor's page for the names, number of reviews and URL of hotel pages using the "Inspect" tool. Tripadvisor uses dynamic naming for elements so we will avoid using them.
Let's start with the name of the hotel, we will extract it using the "data-automation": "hotel-card-title" tag and value:

For the reviews we will extract them using the aria-label tag ::

And finally, we will extract the hotel URL using the href tag present within the same tag we've used to extract the name of the hotel:

Here's the code to find, scrape and add the data to their respective lists:
hotel_name = soup.find_all("div", attrs={"data-automation": "hotel-card-title"})
for name in hotel_name:
Hotel_Name.append(name.text)
for review in soup.find_all("div", attrs={"aria-label": True}):
text = review["aria-label"]
if "reviews" in text:
Hotel_Review.append(text.split()[-2].replace(",", ""))
hotel_link = soup.find_all("div", attrs={"data-automation": "hotel-card-title"})
for link in hotel_link:
Hotel_Link.append('https://www.tripadvisor.com'+link.find('a')['href'])
Finally, let's print out the data:
print(Hotel_Name)
print(Hotel_Review)
print(Hotel_Link)
Here's what the code should look like:
from bs4 import BeautifulSoup
import http.client
base_url = "https://www.tripadvisor.com/Hotels-g187768-Italy-Hotels.html"
template_url = "https://www.tripadvisor.com/Hotels-g187768-oa{}-Italy-Hotels.html"
num_pages = 2
urls = [base_url]
for i in range(30, (num_pages * 30), 30):
urls.append(template_url.format(i))
Hotel_Name = []
Hotel_Review = []
Hotel_Link = []
for url in urls:
conn = http.client.HTTPSConnection("api.scrapingant.com")
conn.request("GET", "/v2/general?url={}&x-api-key=YOUR-API-TOKEN".format(url))
res = conn.getresponse()
data = res.read()
soup = BeautifulSoup(data, "html.parser")
hotel_name = soup.find_all("div", attrs={"data-automation": "hotel-card-title"})
for name in hotel_name:
Hotel_Name.append(name.text)
for review in soup.find_all("div", attrs={"aria-label": True}):
text = review["aria-label"]
if "reviews" in text:
Hotel_Review.append(text.split()[-2].replace(",", ""))
hotel_link = soup.find_all("div", attrs={"data-automation": "hotel-card-title"})
for link in hotel_link:
Hotel_Link.append('https://www.tripadvisor.com'+link.find('a')['href'])
print(Hotel_Name)
print(Hotel_Review)
print(Hotel_Link)
Now let's save it to a file called test.py, open a Terminal if you're on Mac or Linux, or a Command Prompt if you're on Windows and type in python test.py.
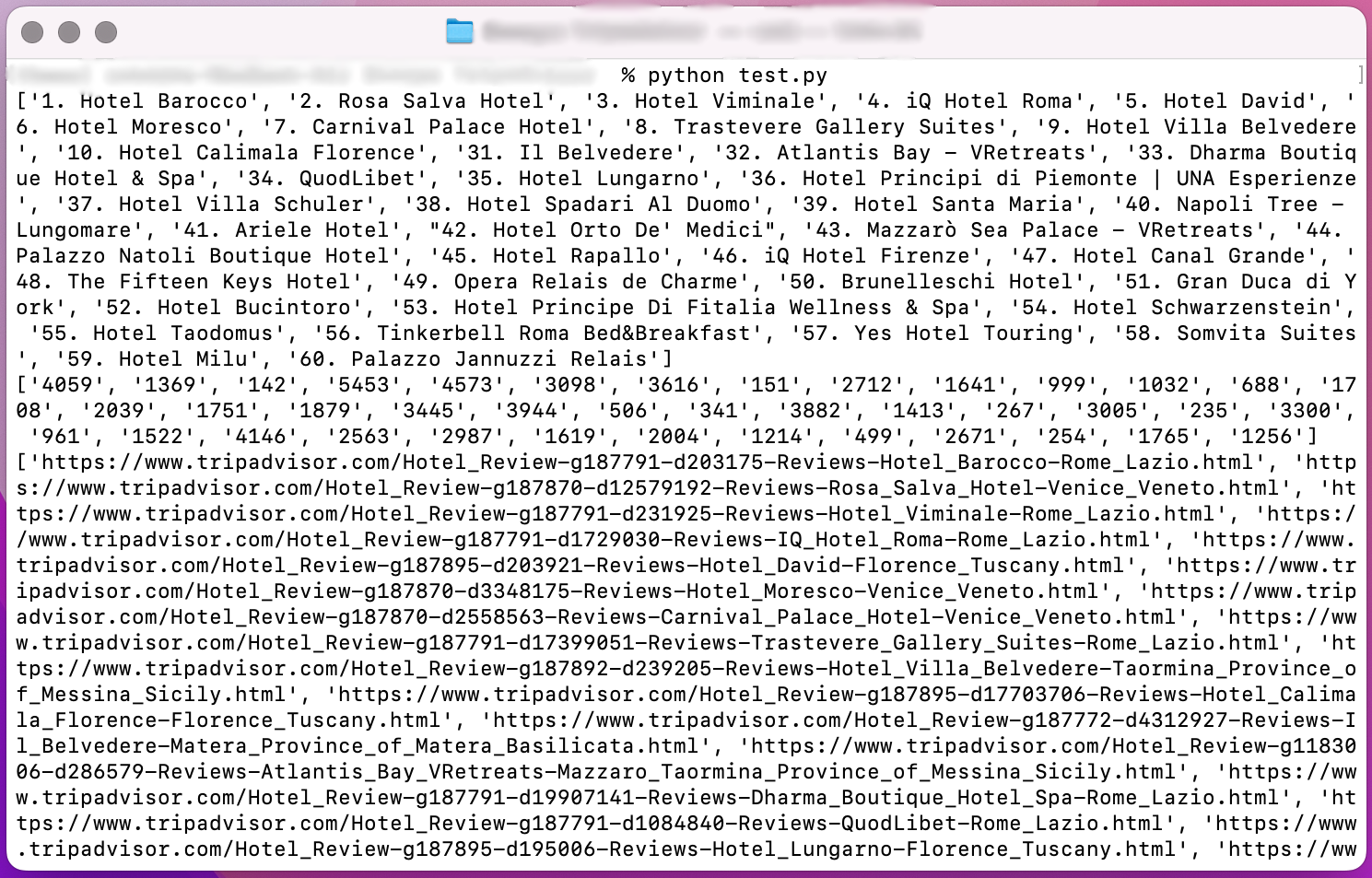
The output should look like this:
To Conclude
In this short example, we've seen how easy it was to scrape hotel data from Tripadvisor using ScrapingAnt's Web Scraping API and a few lines of Python code.
We've learned how to scrape pages recursively from Tripadvisor, how to find HTML tags using the Inspect tool and how to extract data from non-dynamic HTML tags using BeautifulSoup HTML parser.
We've also learned how we could avoid getting blocked by Tripadvisor's anti-bot protection by sending our requests through ScrapingAnts proxies.