

Google News is a popular news aggregator that compiles headlines from thousands of news sources worldwide, making it a valuable resource for web scraping.
In this article, we'll look at how to effectively scrape data from Google News. Even though the raw data can be messy, we'll show you how to clean it up and organize it into a CSV file. We'll also discuss the challenges and best practices for scraping Google News, including how to avoid getting blocked.
Does Google News Allow Scraping?
Yes, you can scrape Google News. The data on the Google News website is publicly accessible and free to use. However, it's important to respect their terms of service and ensure that you don't overwhelm their servers with excessive requests.
Why Scrape Google News?
There are many reasons to scrape Google News, including:
- Real-time information: Stay up-to-date with the latest news and events.
- Comprehensive data: Gather vast amounts of data for in-depth analysis.
- Competitive intelligence: Monitor competitors and industry trends.
- Sentiment analysis: Gauge public opinion on various topics.
How to scrape Google News in Python
Follow this step-by-step tutorial to learn how to create a web scraper for Google News using Python.
1. Choosing the Optimal Approach
Scraping Google News can be challenging. While tools like Playwright or Selenium can be used, the complex HTML structure and nested elements make it difficult to extract data accurately. See the below image:
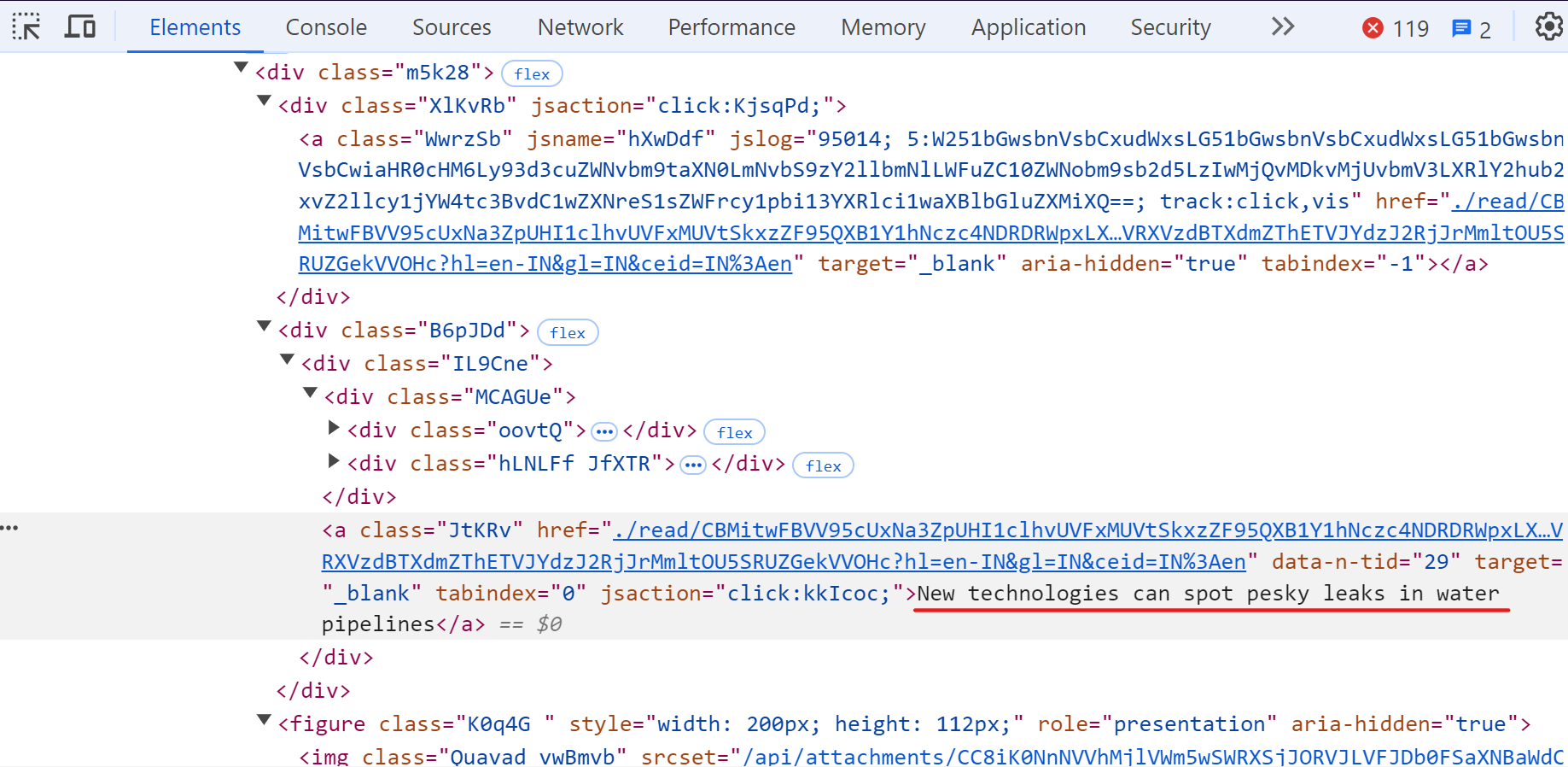
A more efficient approach is to use RSS feeds. Many news websites, including Google News, offer RSS feeds that provide a standardized way to access and aggregate news content.
Here's an example of how an RSS feed typically looks:
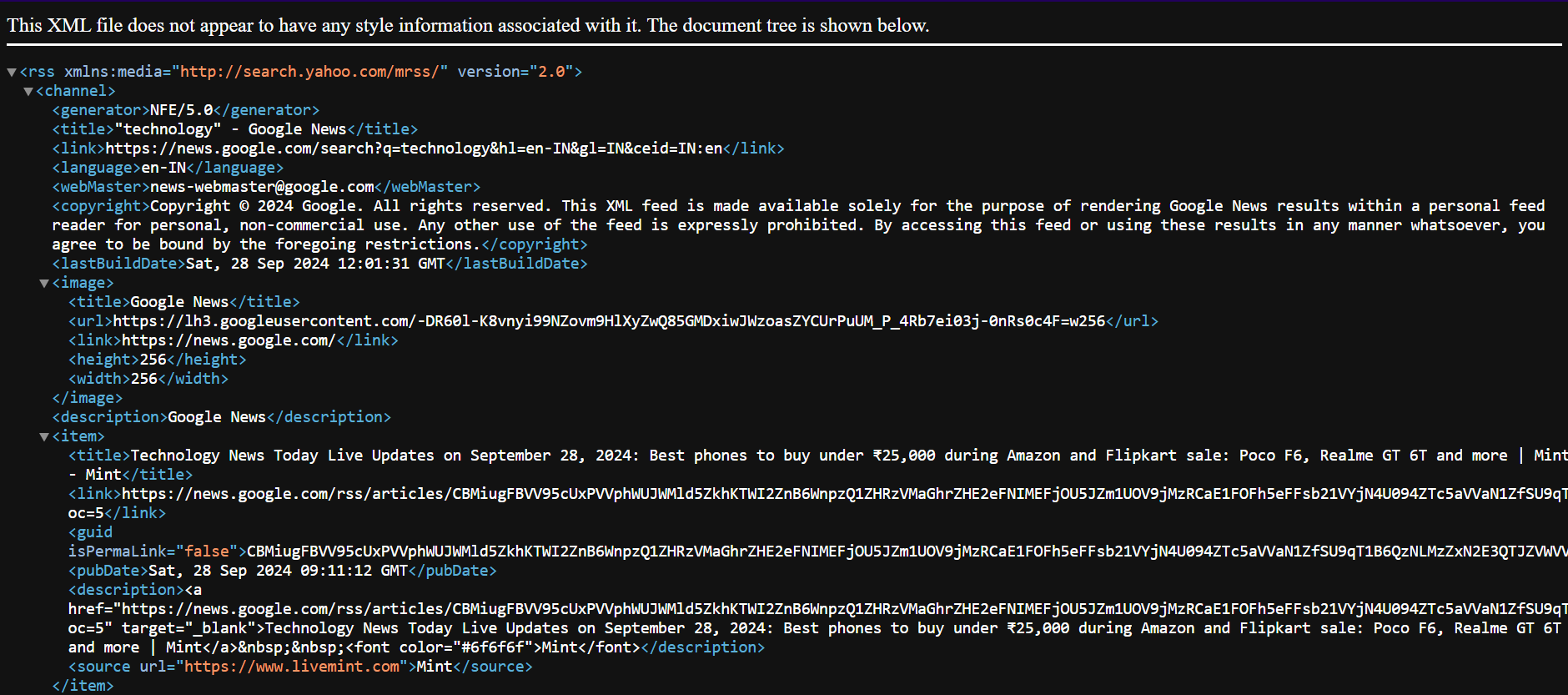
The XML format makes it easy to extract key data without dealing with complex web elements. This simplifies the scraping process and ensures reliable data extraction.
2. Setting Up Environment
Before you start, make sure your development environment is ready:
- Install Python: Download and install the latest version from the official Python website.
- Choose an IDE: Use PyCharm, Visual Studio Code, or Jupyter Notebook.
Next, create a new project. It’s a best practice to use a virtual environment, as it helps manage dependencies and avoid conflicts between different projects. Navigate to your project directory and run the following command to create a virtual environment:
python -m venv google_news_scraper
Activate the virtual environment:
- On Windows, run:
google_news_scraper\\Scripts\\activate - On macOS and Linux, run:
source google_news_scraper/bin/activate
With the virtual environment activated. Now you need to install the required libraries to work with RSS feeds.
Install the Feedparser library by using the following command:
pip install feedparser
This library will help you download and parse RSS feeds easily.
3. Finding the Google News RSS Feed URL
To scrape data from Google News using RSS, we need a feed URL.
Here's how to find one:
Step 1: Go to https://news.google.com/ and search for your desired topic, like "technology".
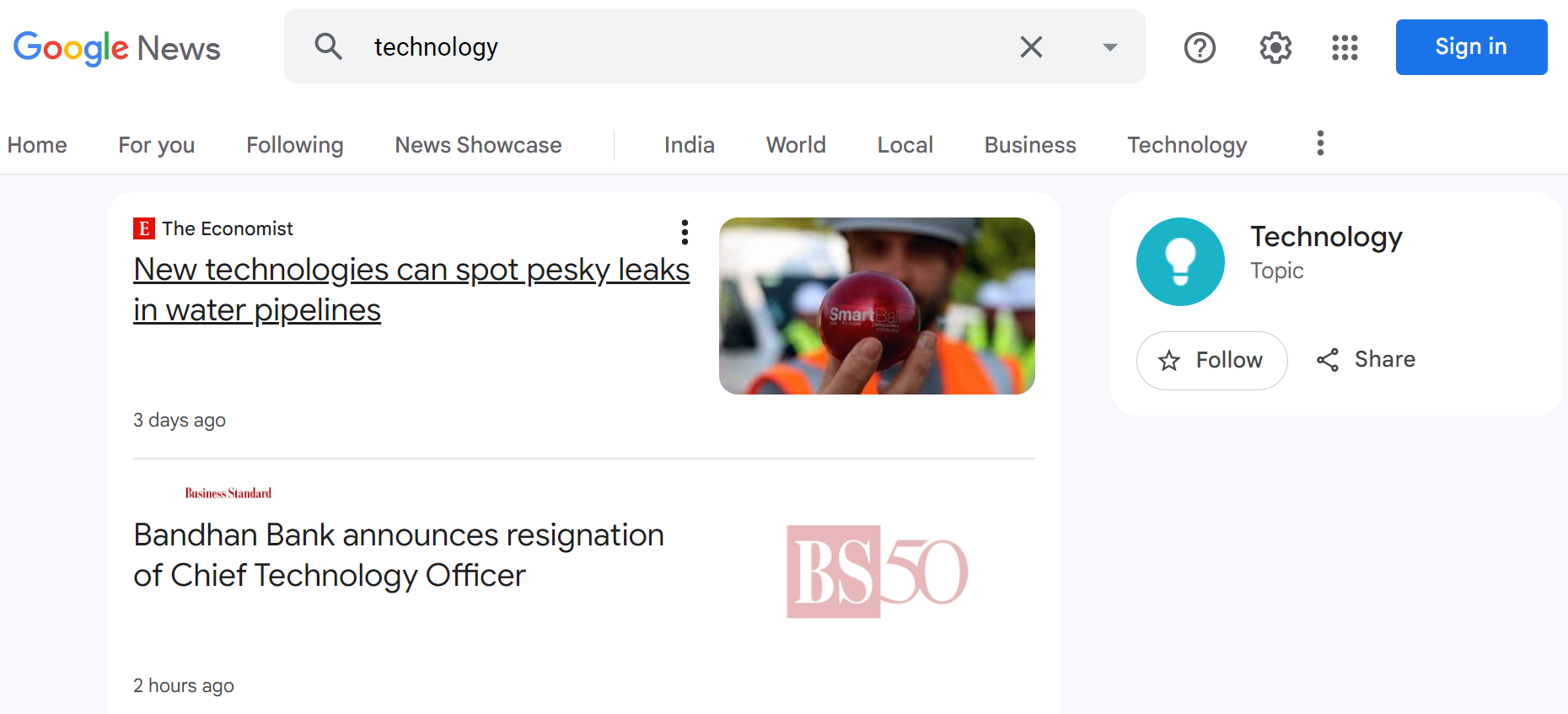
Step 2: Take the URL from the search results page, like:
https://news.google.com/search?q=technology
Step 3: Now, simply add "/rss" to the end. This will lead you to the RSS feed for that specific topic, like:
https://news.google.com/rss/search?q=technology
Step 4: Visit this URL, you'll see the RSS feed in XML format:
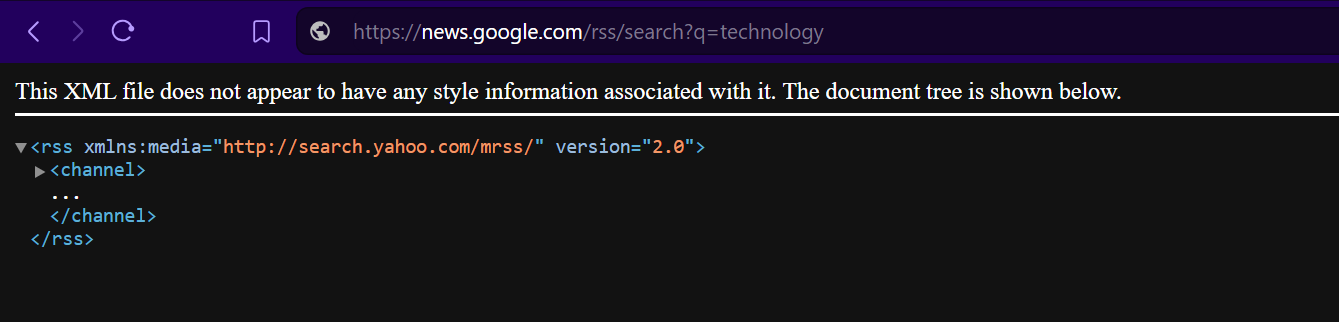
4. Parsing the RSS Feed
Once you have the RSS feed URL, you can use Python's feedparser library to download and parse the feed data. Here's an example code snippet:
import feedparser
# URL of the Google News RSS feed
gn_url = "https://news.google.com/rss/search?q=technology&hl=en-US&gl=US&ceid=US:en"
# Parse the RSS feed
gn_feed = feedparser.parse(gn_url)
print(gn_feed)
Running this code will print the entire parsed feed data in a structured format.
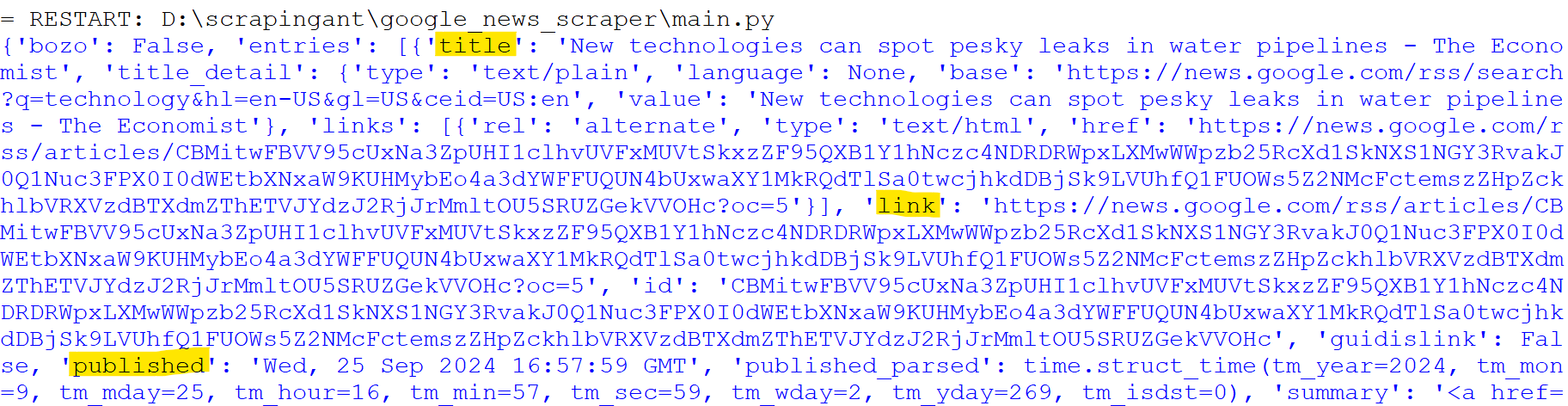
This data contains various information about the news articles, including titles, links, and publication dates. We'll explore how to extract this specific information in the next step.
5. Extracting Specific Information
RSS feed contains details about each news article under an item tag. We're interested in the title, link, publication date, and source.
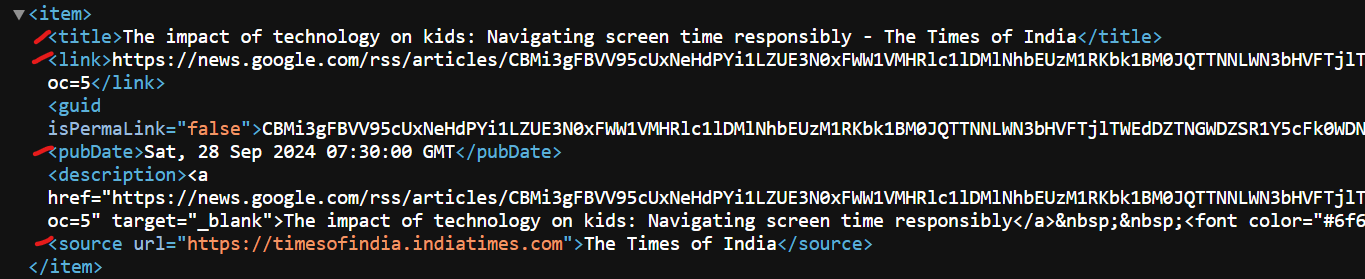
Here's the modified code to extract the specific data:
import feedparser
# URL of the Google News RSS feed
gn_url = "https://news.google.com/rss/search?q=technology&hl=en-US&gl=US&ceid=US:en"
# Parse the RSS feed
gn_feed = feedparser.parse(gn_url)
# Iterate through each news entry in the feed
for entry in gn_feed.entries:
news_title = entry.title
news_link = entry.link
publication_date = entry.published
news_source = entry.source
print([news_title, publication_date, news_source, news_link])
Running this code will output:

Nice, the data looks more readable!
6. Scraping News for Multiple Search Terms
So far, we've focused on extracting data from a single RSS feed. Now, let's modify the script to handle multiple search terms at once. Suppose you want news articles about both "meta llama 3.2" and "chatgpt o1 model”.
Here's the modified script:
import feedparser
import sys
def fetch_news(search_terms):
for search_term in search_terms:
search_term = search_term.replace(" ", "+")
gn_url = f"https://news.google.com/rss/search?q={search_term}&hl=en-US&gl=US&ceid=US:en"
gn_feed = feedparser.parse(gn_url)
if gn_feed.entries:
for news_item in gn_feed.entries:
news_title = news_item.title
news_link = news_item.link
publication_date = news_item.published
news_source = news_item.source
print(
f"Headline: {news_title}\nPublished: {publication_date}\nSource: {news_source}\nURL: {news_link}"
)
print(20 * "-")
else:
print(f"No news found for the term: {search_term}")
if __name__ == "__main__":
search_terms = sys.argv[1:]
if not search_terms:
print("No search terms provided. Exiting.")
sys.exit()
fetch_news(search_terms)
To begin, the code imports the sys module to allow user input. The fetch_news function accepts a list of search terms and processes each one individually. For every term, it creates a URL for an RSS feed, parses the feed, and retrieves the title, link, publication date, and source.
To run the script, open a terminal window and pass the desired search terms as arguments. For example:
python main.py "meta llama 3.2" "chatgpt o1 model"
This will fetch and display news articles related to both topics. If you wish to limit results to, for example, 1 article per search term, you can simply modify the code.
import feedparser
import sys
def fetch_news(search_terms, max_articles):
for search_term in search_terms:
# ...
if gn_feed.entries[:max_articles]:
for news_item in gn_feed.entries[:max_articles]:
# ...
else:
print(f"No news found for the term: {search_term}")
if __name__ == "__main__":
search_terms = sys.argv[1:-1]
max_articles = int(sys.argv[-1])
if not search_terms:
print("No search terms provided. Exiting.")
sys.exit()
fetch_news(search_terms, max_articles)
Run the script with the same command as before, but include the desired maximum number of articles:
python main.py "meta llama 3.2" "chatgpt o1 model" 1
This will now display only 1 article for each search term.
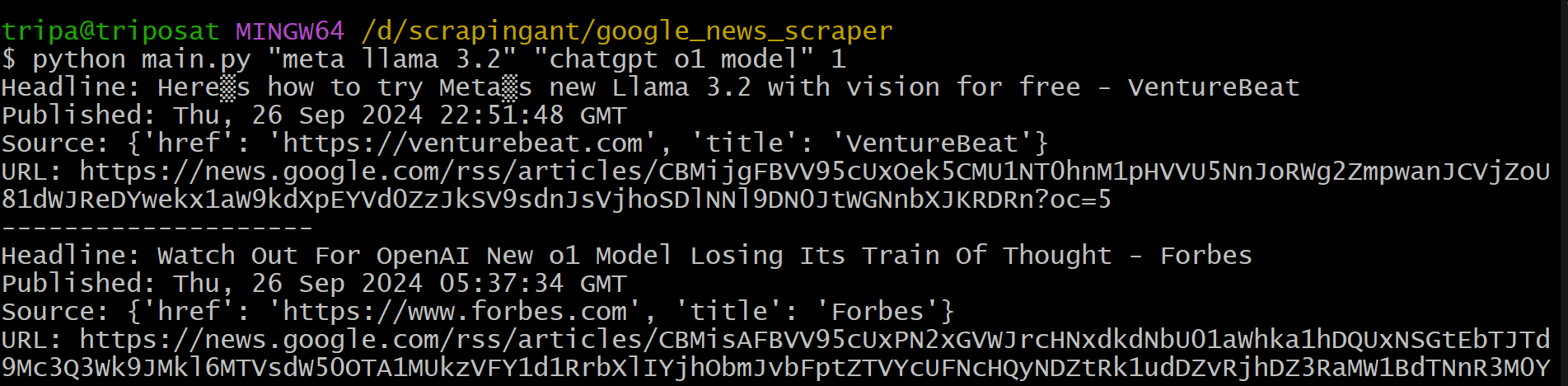
7. Cleaning the Data
Now that we have the desired data, let's make it more clear.
- Clean Headlines: Remove source names from the end of headlines.
- Shorten URLs: Use the pyshorteners library to shorten long URLs.
- Separate Source Information: Extract the source name and website link separately.
Hers’ the modified code:
import feedparser
import sys
import pyshorteners
# Shortens a given URL using TinyURL
def shorten_url(url):
s = pyshorteners.Shortener()
try:
short_url = s.tinyurl.short(url)
return short_url
except Exception as e:
print(f"Error shortening URL: {e}")
return url
# Cleans a news title by removing the source name
def clean_title(title):
return title.rsplit(' - ', 1)[0].strip()
def fetch_news(search_terms, max_articles):
# ... (rest of the code)
for news_item in gn_feed.entries[:max_articles]:
news_title = clean_title(news_item.title)
news_link = shorten_url(news_item.link)
publication_date = news_item.published
news_source = news_item.source.get("title")
source_url = news_item.source.get("href")
print(
f"Headline: {news_title}\nURL: {news_link}\nPublished: {publication_date}\nSource: {news_source} ({source_url})"
)
print(20 * "-")
# ... (rest of the code)
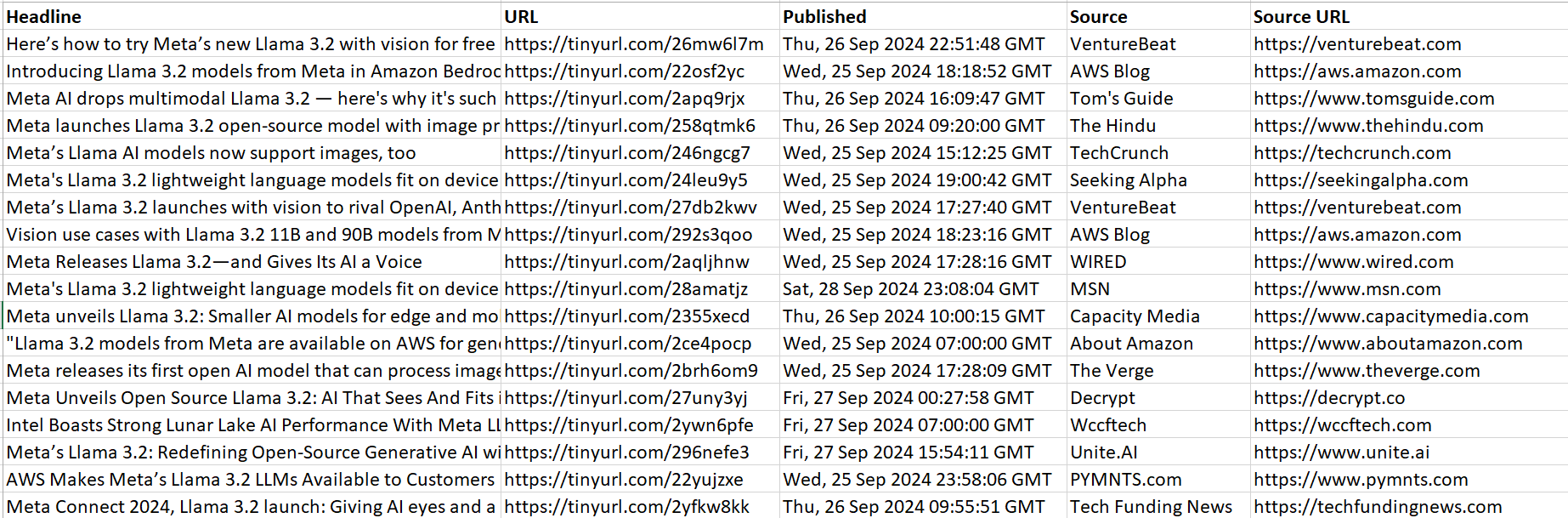
The result is:
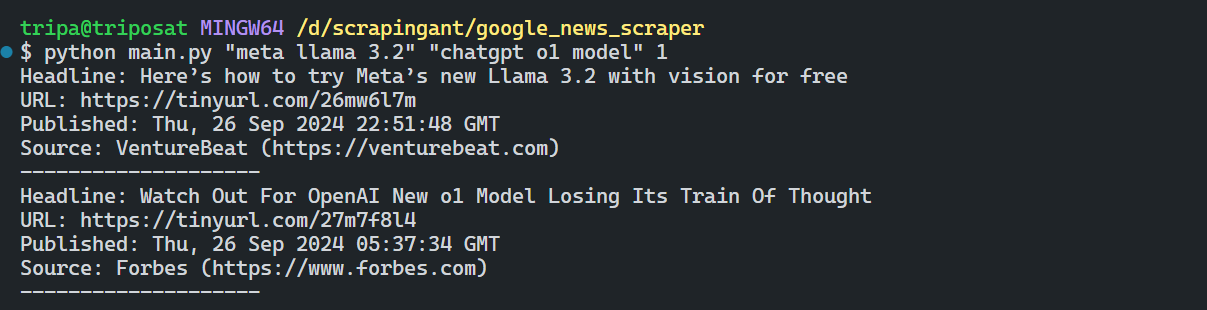
Awesome! The data is much cleaner and readable.
8. Exporting Data to CSV
Let’s modify the code to export the cleaned news data to a CSV file. This will help in easier access and manipulation of the data for future analysis.
Here's the complete code:
import feedparser
import sys
import pyshorteners
import csv
# Shortens a given URL using TinyURL
def shorten_url(url):
s = pyshorteners.Shortener()
try:
short_url = s.tinyurl.short(url)
return short_url
except Exception as e:
print(f"Error shortening URL: {e}")
return url
# Cleans a news title by removing the source name
def clean_title(title):
return title.rsplit(" - ", 1)[0].strip()
# Fetches news articles based on search terms and writes them to a CSV file
def fetch_news(search_terms, max_articles):
with open("news_data.csv", mode="w", newline="", encoding="utf-8-sig") as file:
writer = csv.writer(file)
# Write the CSV header
writer.writerow(["Headline", "URL", "Published", "Source", "Source URL"])
for search_term in search_terms:
search_term = search_term.replace(" ", "+")
gn_url = f"https://news.google.com/rss/search?q={search_term}&hl=en-US&gl=US&ceid=US:en"
gn_feed = feedparser.parse(gn_url)
if gn_feed.entries[:max_articles]:
for news_item in gn_feed.entries[:max_articles]:
news_title = clean_title(news_item.title)
news_link = shorten_url(news_item.link)
publication_date = news_item.published
news_source = news_item.source.get("title")
source_url = news_item.source.get("href")
# Write each news item to the CSV file
writer.writerow(
[
news_title,
news_link,
publication_date,
news_source,
source_url,
]
)
else:
print(f"No news found for the term: {search_term}")
if __name__ == "__main__":
search_terms = sys.argv[1:-1]
max_articles = int(sys.argv[-1])
if not search_terms:
print("No search terms provided. Exiting.")
sys.exit()
fetch_news(search_terms, max_articles)
After running the code, you will find a news_data.csv file created in the same directory as your script.
Does Google News have an API?
No, Google News does not have its API. If you want to access Google News data programmatically, you would need to rely on third-party APIs, but most of these are paid services.
Challenges and Considerations
While Google News RSS feeds are a great way to access news content, but Google employs advanced methods for detecting and preventing excessive scraping by bots. While rotating IPs, adding random delays, and mimicking user behaviour can help, these methods aren't foolproof.
A better solution is to use ScrapingAnt, a web scraping API that manages everything for you—IP rotation, delays, and browser emulation—so you can extract data without getting blocked.
To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you.
Conclusion
We've covered how to effectively scrape Google News by fetching and parsing its RSS feed. During scraping, there can be challenges, so we've also discussed ways to overcome them. Additionally, we explored how using ScrapingAnt can be a better solution for scraping Google News at scale.