

In this article, we’d like to introduce an awesome open-source Web Scraping solution for running a pool of Chromium instances using Puppeteer.
Running a pool of Chromium instances using Puppeteer
Sequential execution to perform web scraping tasks is not a good idea as one process has to wait for the other processes to complete first. This is a time-consuming job when it comes to many processes waiting in a queue. So to overcome this we are going to perform these actions in parallel where the processes execute concurrently and result in less time consumption.
What does this library do?
- Handling of crawling errors
- Auto restarts the browser in case of a crash
- Can automatically retry if a job fails
- Different concurrency models to choose from (pages, contexts, browsers)
- Simple to use, small boilerplate
- Progress view and monitoring statistics (see below)
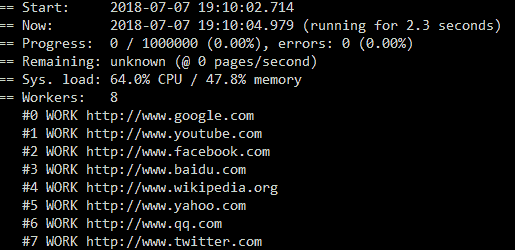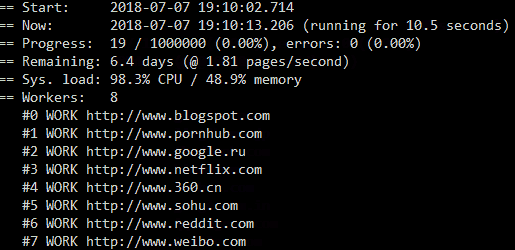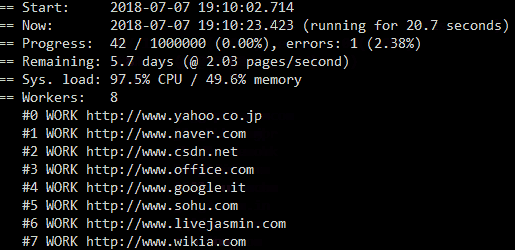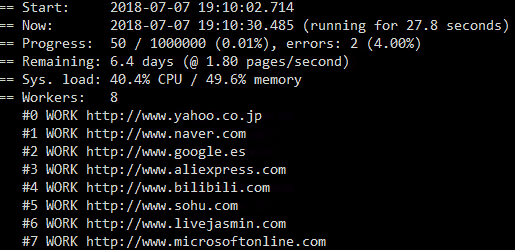
To read more about Puppeteer itself just visit the official Github page: https://github.com/puppeteer/puppeteer
Installing Puppeteer Cluster
To start using Puppeteer Cluster you should start by installing dependencies, for example, via NPM.
Install puppeteer (if you don't already have it installed):
npm install --save puppeteer
Then install puppeteer-cluster:
npm install --save puppeteer-cluster
Usage
All that you need to provide while using Puppeteer Cluster function is:
- Process count that needs to be executed in parallel
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2 // Can be 1,000,00 but let's start from 2
});
- Define a task that has to perform the expected action
await cluster.task(async ({ page, data: url }) => {
await page.goto(url);
//Perform the action, for example - store the result
})
- Invoke the task using queue and wait until the cluster completes the execution
cluster.queue('http://www.google.com/');
cluster.queue('https://scrapingant.com/');
The whole script will look like the below example:
const { Cluster } = require('puppeteer-cluster');
(async () => {
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2,
});
await cluster.task(async ({ page, data: url }) => {
await page.goto(url);
//Perform the action, for example - store the result
});
cluster.queue('http://www.google.com/');
cluster.queue('https://scrapingant.com/');
// many more pages
await cluster.idle();
await cluster.close();
})();
And that is all.
Documentation
For the extensive documentation just visit the Github repository: https://github.com/thomasdondorf/puppeteer-cluster
And the examples directory inside the repository: https://github.com/thomasdondorf/puppeteer-cluster/tree/master/examples
Conclusion
Apart from scraping you can still make use of Puppeteer Cluster for automation testing, performance testing, improving your site rank, and many more cases with parallel browser workers.
Of course, you can try our Web Scraping API that supports parallel execution of headless Chrome rendering with a simple API.