

Google Flights collects information from different airlines and travel companies to show you all the flights available, their prices, and schedules. This helps travellers to compare airline prices, check flight durations, even track environmental impact, and at last find the best deals.
In this tutorial, I’ll show you how you can easily scrape all the data you need from Google Flights using Python and Playwright.
What Data to Extract from Google Flights?
Google Flights has a lot of valuable information. To get started, apply filters for your departure and destination. For example, I’m looking for a one-way flight from Boston to Honolulu. Once you set your filters, you’ll see a range of flight options.
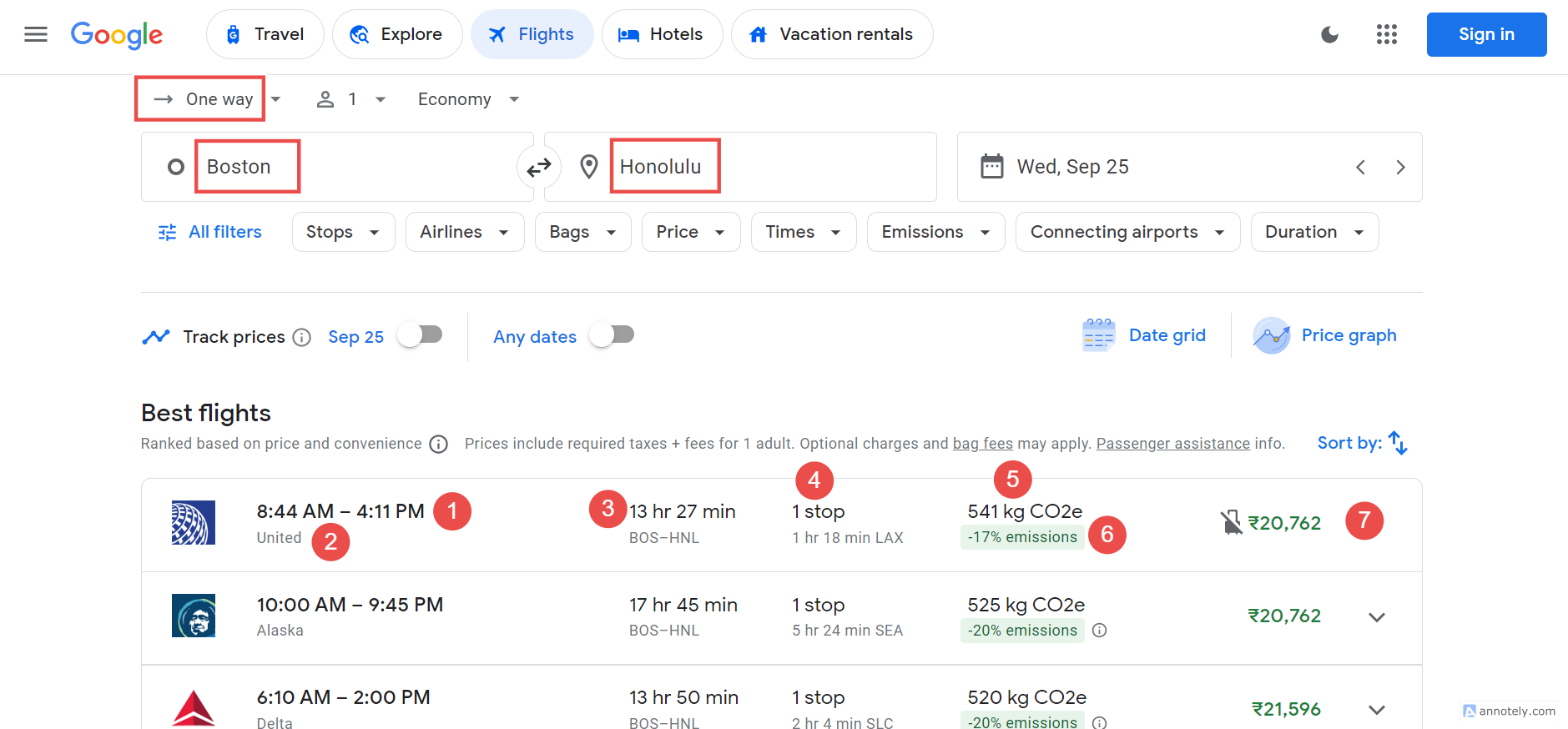
We’re going to extract several key details, including:
- Flight name
- Departure time
- Arrival time
- Flight duration
- Prices
- Number of stops
- CO2 emissions (to help you choose more eco-friendly travel options)
- CO2 emissions change.
Let’s dive in and start scraping the data!
Prerequisites
We’ll be using Python with the asynchronous version of Playwright for this tutorial. While Playwright offers both sync and async options, the async version is faster and more efficient for our scraping tasks.
If you’re new to Playwright, I recommend checking out my Playwright 4-part series. It covers everything from the basics to more advanced techniques.
Here’s what you need to get started:
- Python Installation: Make sure you have the latest version of Python installed.
- Code Editor: Choose a code editor that you’re comfortable with. Popular choices include: PyCharm, Visual Studio Code, and Jupyter Notebook.
- Basic CSS or XPath Knowledge: Some familiarity with CSS selectors or XPath will help, but don’t worry if you're unfamiliar with these concepts, this tutorial is designed to be straightforward and easy to follow.
Installing Libraries
To get started, we need to install Playwright and the required browser binaries. Simply run the following commands in your terminal:
pip install playwright
playwright install
Once you’ve completed these steps, you’re all set to start scraping flight data from Google Flights. Let’s get coding!
Scrape Airline Names from Google Flights
To scrape the airline name, you can target the div with the class .sSHqwe. This class contains the airline’s name, and you can access it using the query_selector method.
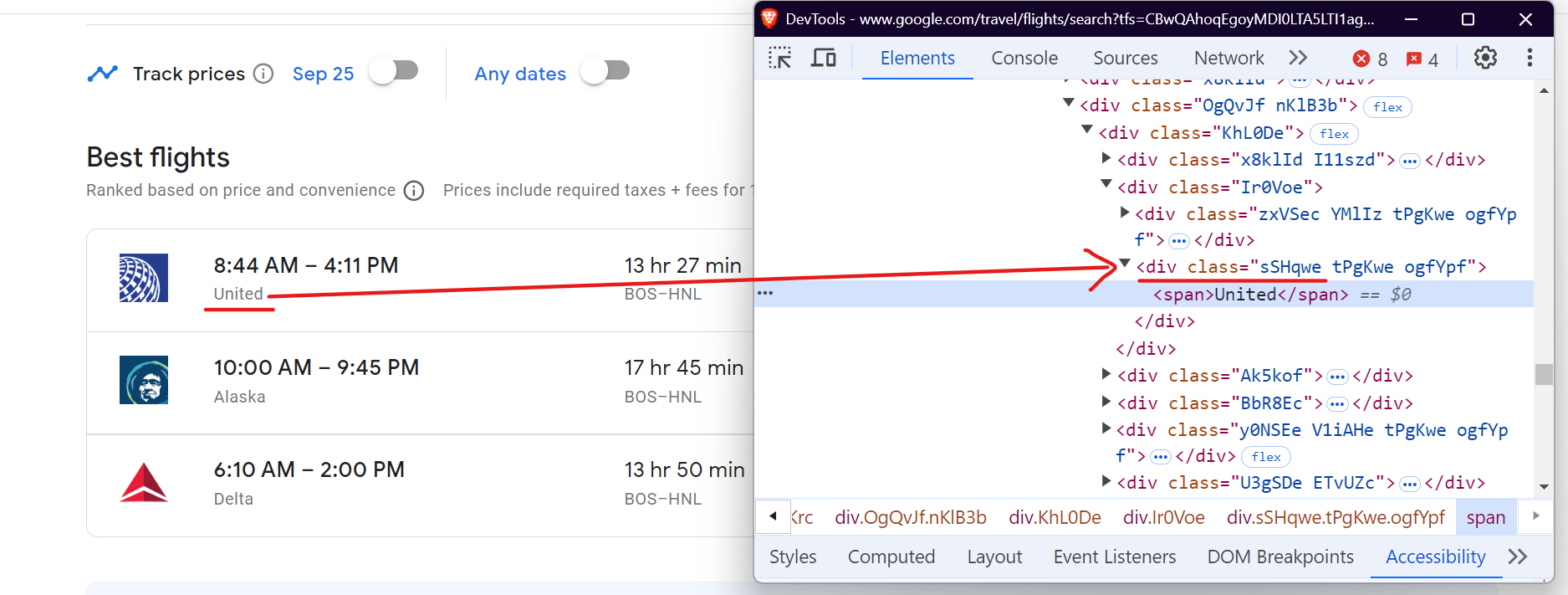
Here’s the code snippet:
airline = await flight.query_selector('.sSHqwe')
The query_selector method finds the first element that matches the provided selector. If no element is found, it returns null.
Scrape Flight Duration
Next, to scrape the flight duration (e.g., "13 hr 27 min"), use the div tag with the class .gvkrdb.
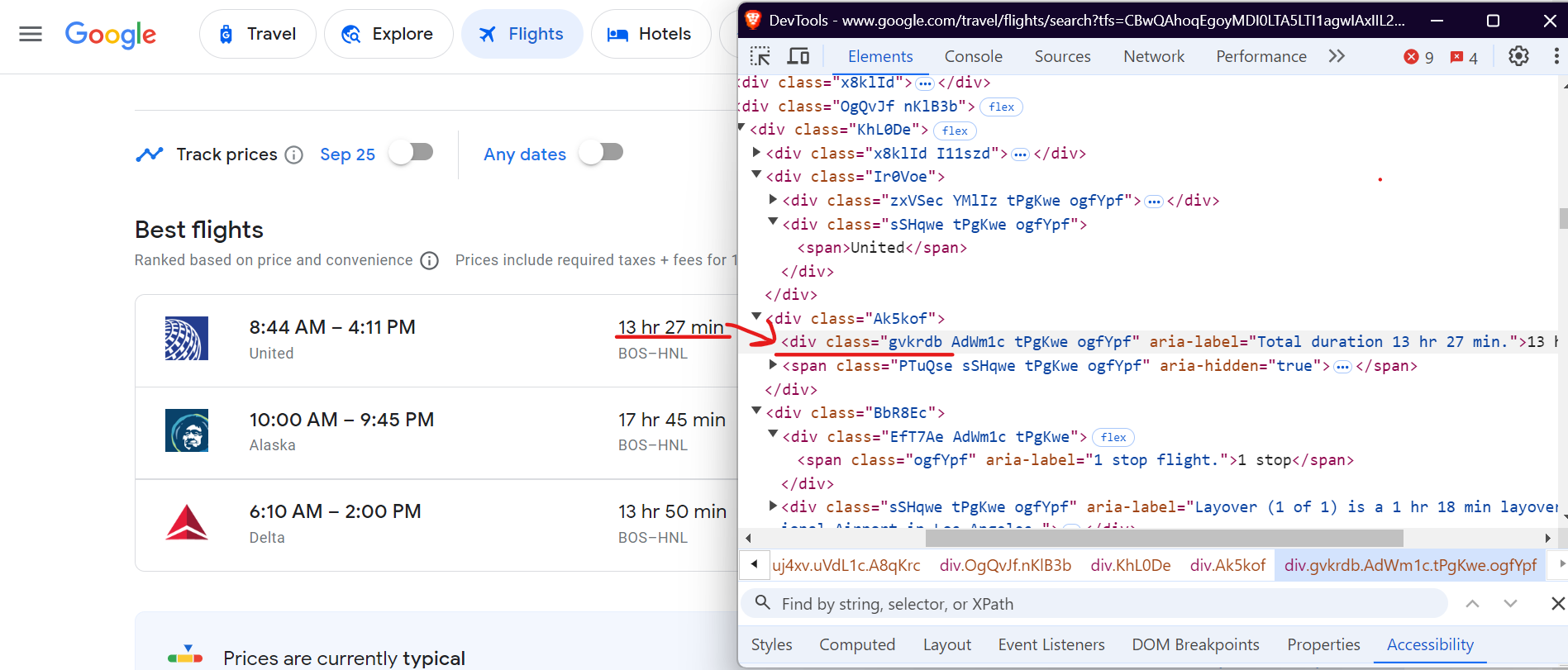
Here’s the code to extract the duration:
duration = await flight.query_selector('div.gvkrdb')
Scrape Flight Prices
To extract the price of the flight, target the div tag with the class.FpEdX and then grab the span tag containing the price.
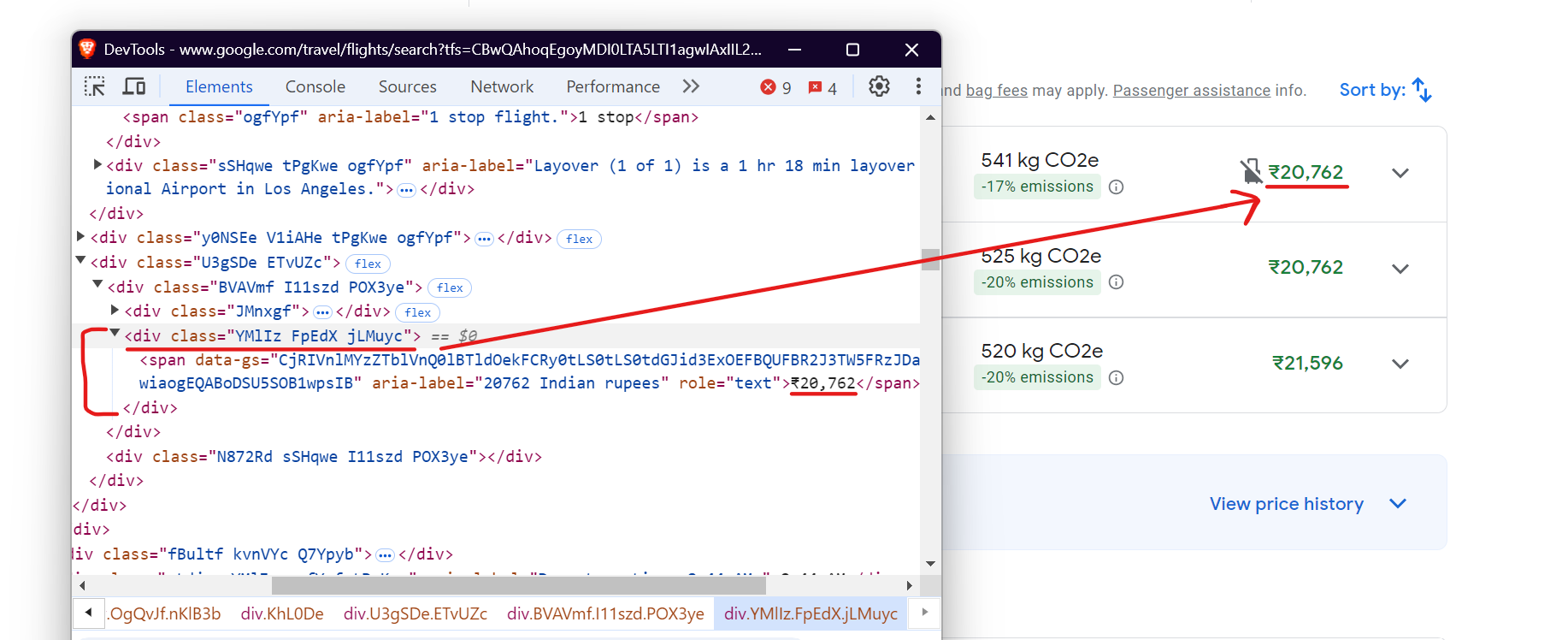
Here’s the snippet:
price = await flight.query_selector('div.FpEdX span')
Scrape Departure and Arrival Times
To scrape both the departure and arrival times, you can use selectors targeting span elements with aria-label attributes. For example, to extract the departure time, use [aria-label*="Departure time"] and for the arrival time, [aria-label*="Arrival time"].
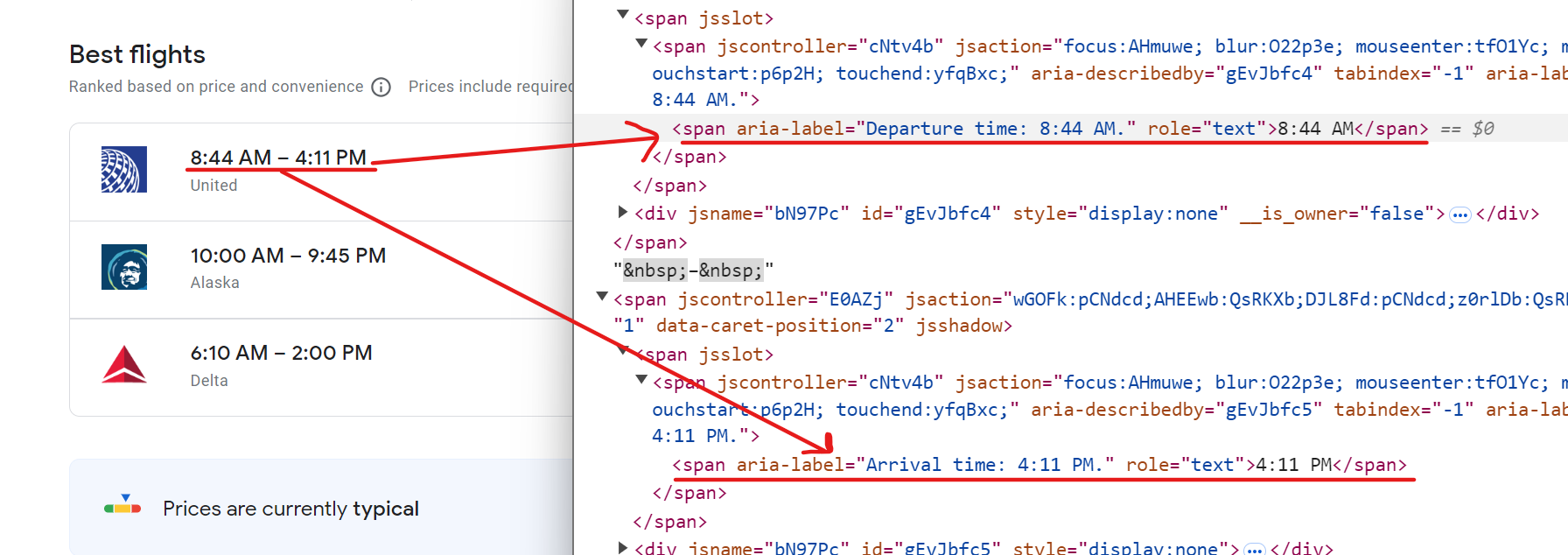
Here’s how you can do it:
departure_time = await flight.query_selector('span[aria-label*="Departure time"]')
arrival_time = await flight.query_selector('span[aria-label*="Arrival time"]')
Scrape CO2 Emissions and Emission Changes
To extract data on CO2 emissions, use the div with class .O7CXue for CO2 emissions and .N6PNV for emission changes.
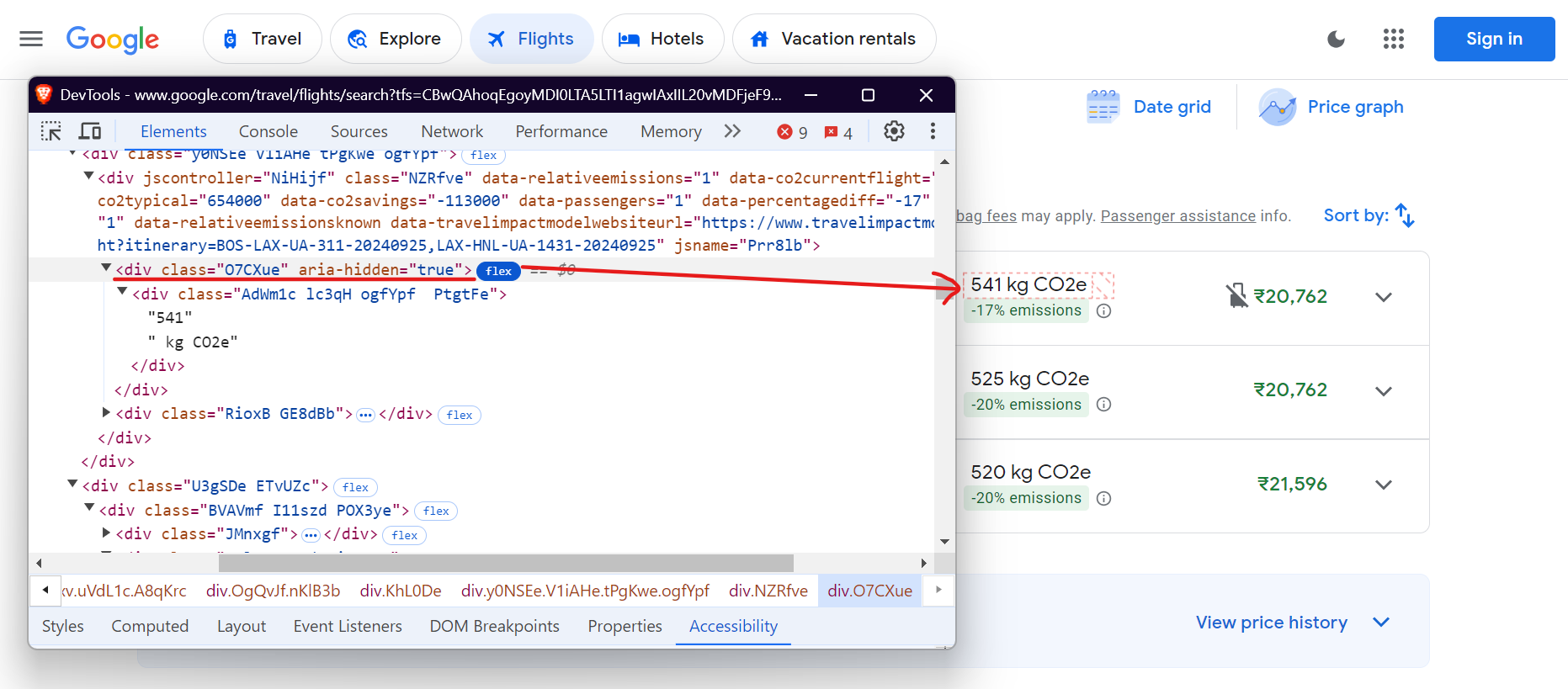
Here’s the code for CO2 emissions:
co2_emissions = await flight.query_selector('div.O7CXue')
And for the emission variation:
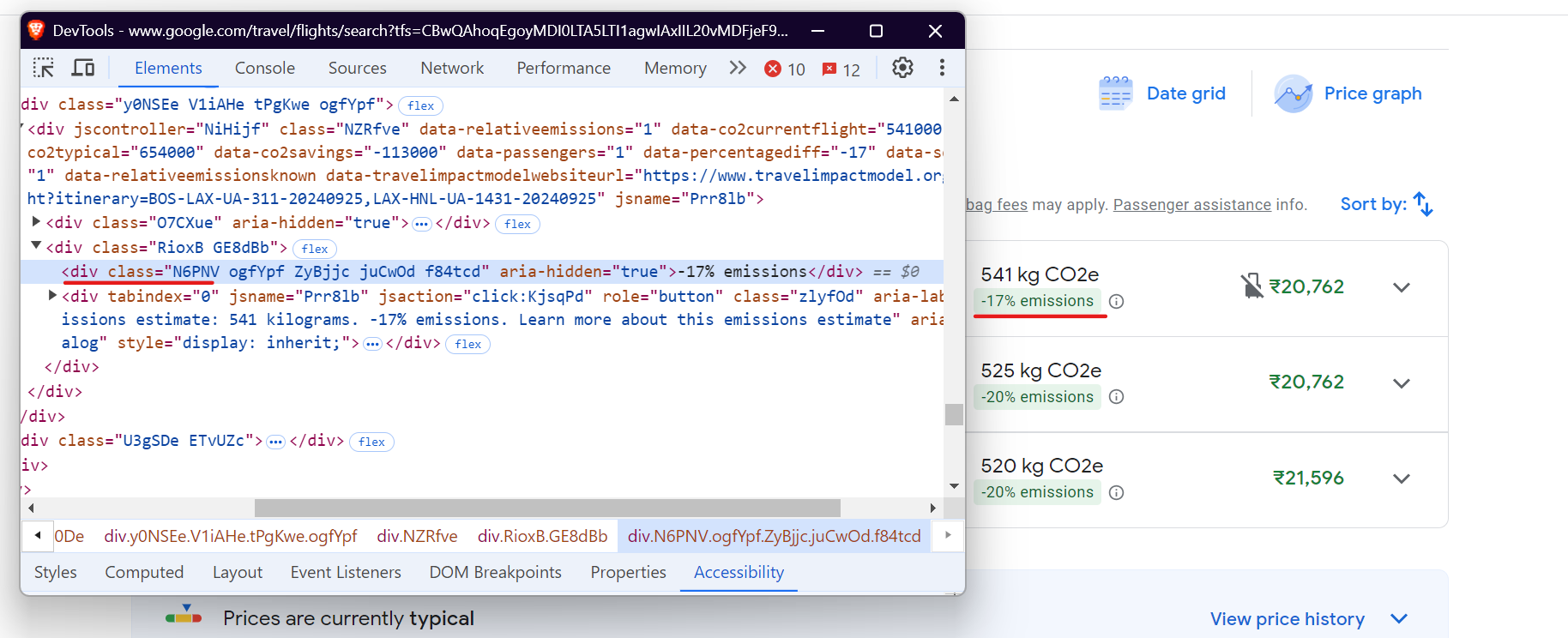
Here’s how you can do it:
emissions_variation = await flight.query_selector('div.N6PNV')
Scrape Flight Stops
Finally, to extract information about flight stops, use the div with class .hF6lYb and the span inside it with class .rGRiKd. This will give you details about the number of stops and where the flight stops.
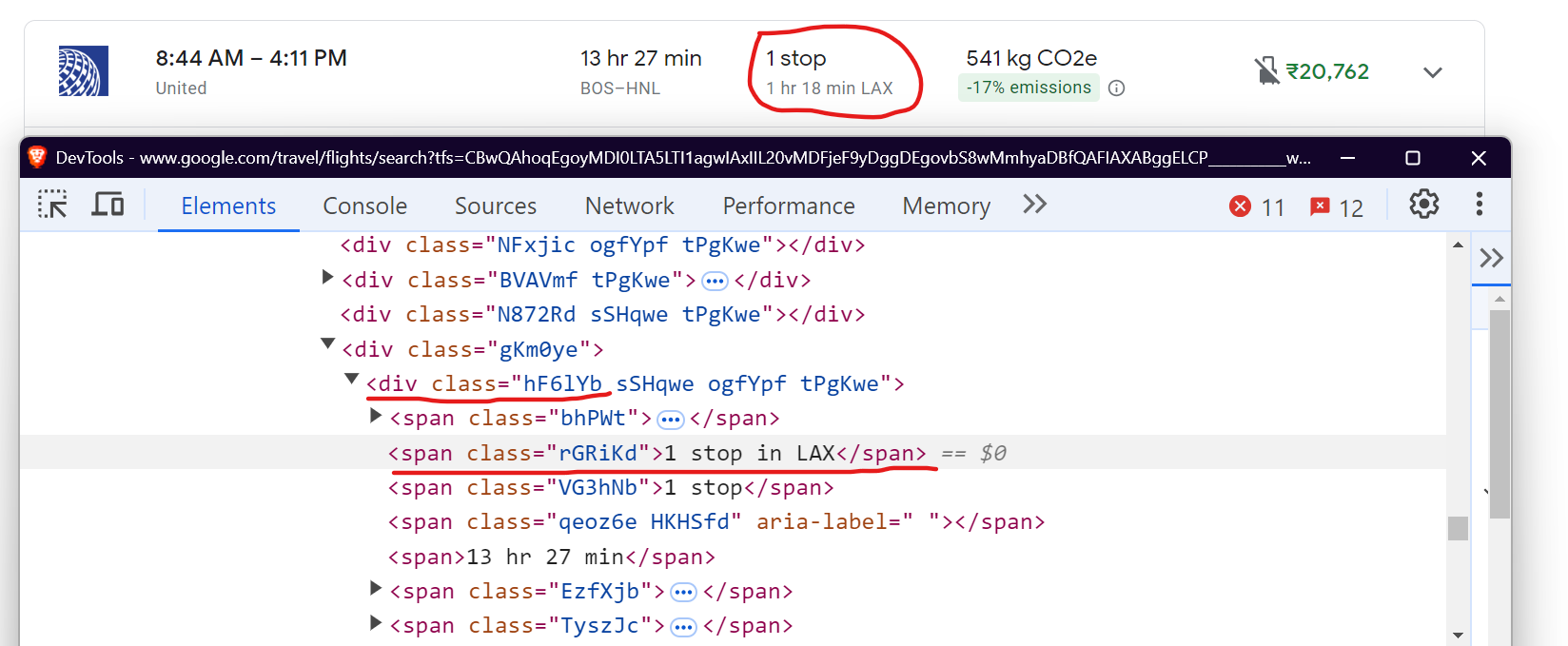
Here’s the code:
stop_info = await flight.query_selector('div.hF6lYb span.rGRiKd')
Complete Code
Here’s the complete code combining all the snippets
import asyncio
import json
from playwright.async_api import async_playwright
async def scrape_flight_data():
flight_data = [] # List to store flight details
# Start Playwright and open a browser
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True) # Launch browser
page = await browser.new_page() # Open a new browser page
# Go to the flight search results page
await page.goto("https://www.google.com/travel/flights/search?tfs=CBwQAhoqEgoyMDI0LTA9LTI1agwIAxIIL20vMDFjeF9yDggDEgovbS8wMmhyaDBfQAFIAXABggELCP___________wGYAQI&tfu=EgYIABAAGAA&hl=en&gl=IN")
# Wait for relevant flight data to load
await page.wait_for_selector(".pIav2d")
# Extract flight data
flights = await page.query_selector_all(".pIav2d")
for flight in flights:
# Extract departure time
departure_time = await flight.query_selector('span[aria-label*="Departure time"]')
departure_time_text = await departure_time.inner_text() if departure_time else "N/A"
# Extract arrival time
arrival_time = await flight.query_selector('span[aria-label*="Arrival time"]')
arrival_time_text = await arrival_time.inner_text() if arrival_time else "N/A"
# Extract airline
airline = await flight.query_selector(".sSHqwe")
airline_text = await airline.inner_text() if airline else "N/A"
# Extract flight duration
duration = await flight.query_selector("div.gvkrdb")
duration_text = await duration.inner_text() if duration else "N/A"
# Extract stop information
stop_info = await flight.query_selector("div.hF6lYb span.rGRiKd")
stop_info_text = await stop_info.inner_text() if stop_info else "N/A"
# Extract price
price = await flight.query_selector("div.FpEdX span")
price_text = await price.inner_text() if price else "N/A"
# Extract CO2 emissions
co2_emissions = await flight.query_selector("div.O7CXue")
co2_emissions_text = await co2_emissions.inner_text() if co2_emissions else "N/A"
# Extract CO2 emissions variation
emissions_variation = await flight.query_selector("div.N6PNV")
emissions_variation_text = await emissions_variation.inner_text() if emissions_variation else "N/A"
# Add the flight details to the flight_data list
flight_data.append({
"departure_time": departure_time_text,
"arrival_time": arrival_time_text,
"airline": airline_text,
"duration": duration_text,
"stops": stop_info_text,
"price": price_text,
"co2_emissions": co2_emissions_text,
"emissions_variation": emissions_variation_text,
})
# Save the extracted data to a JSON file
with open("flight_data.json", "w", encoding="utf-8") as json_file:
json.dump(flight_data, json_file, ensure_ascii=False, indent=4)
# Close the browser
await browser.close()
# Run the async function
asyncio.run(scrape_flight_data())
The final result is:
[
{
"departure_time": "8:44 AM",
"arrival_time": "4:11 PM",
"airline": "United",
"duration": "13 hr 27 min",
"stops": "1 stop in LAX",
"price": "₹20,762",
"co2_emissions": "541 kg CO2e",
"emissions_variation": "-17% emissions"
},
{
"departure_time": "10:00 AM",
"arrival_time": "9:45 PM",
"airline": "Alaska",
"duration": "17 hr 45 min",
"stops": "1 stop in SEA",
"price": "₹20,762",
"co2_emissions": "525 kg CO2e",
"emissions_variation": "-20% emissions"
},
{
"departure_time": "6:10 AM",
"arrival_time": "2:00 PM",
"airline": "Delta",
"duration": "13 hr 50 min",
"stops": "1 stop in SLC",
"price": "₹21,597",
"co2_emissions": "520 kg CO2e",
"emissions_variation": "-20% emissions"
},
...
...
...
]
Using a Web Scraping API
To handle dynamic content on Google Flights and overcome challenges such as IP blocking, CAPTCHA challenges, and anti-scraping measures implemented by Google Flights, traditional bypass methods like using proxies or rotating IP addresses can improve success rates. However, these methods are not foolproof, as Google Flights may continue to implement new countermeasures.
To reliably scrape any website, regardless of its anti-bot complexity, using a web scraping API like ScrapingAnt is highly effective. It automatically handles Chrome page rendering, low latency rotating proxies, and CAPTCHA avoidance, so you can focus on your scraping logic without worrying about getting blocked.
To start using the ScrapingAnt API, you only need two things: the URL you’d like to scrape and the API key, which can be obtained from your ScrapingAnt dashboard after signing up for a free test account.
To integrate the ScrapingAnt API into your Python project, install the Python client scrapingant-client :
pip install scrapingant-client
You can also explore more on the GitHub project page.
The ScrapingAnt API client is straightforward to use, supporting various input and output formats as described on the Request and Response Format page. Below is a simple example demonstrating its usage:
from scrapingant_client import ScrapingAntClient
client = ScrapingAntClient(token="YOUR_SCRAPINGANT_API_KEY")
response = client.general_request(
"https://www.amazon.com/Dowinx-Headrest-Ergonomic-Computer-Footrest/dp/B0CVWXK632/"
)
print(response.content)
Here's our result:

This shows how ScrapingAnt simplifies the web scraping process by handling the complexities for you.
Conclusion
In this tutorial, you learned how to scrape flight data from Google Flights using Python and Playwright. We covered how to extract key details like flight names, departure and arrival times, flight durations, prices, number of stops, CO2 emissions, and emission changes.
By following the steps outlined in this tutorial, you can easily scrape flight data from Google Flights and use it to find the best deals for your next trip. You can also use a web scraping API like ScrapingAnt to handle dynamic content and anti-scraping measures, ensuring reliable and efficient data extraction.